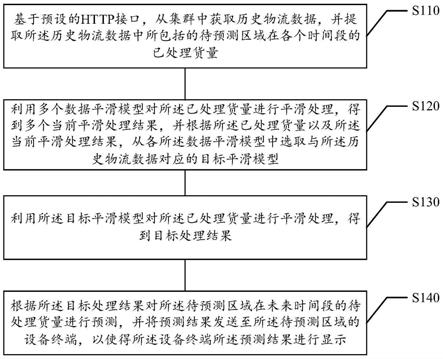
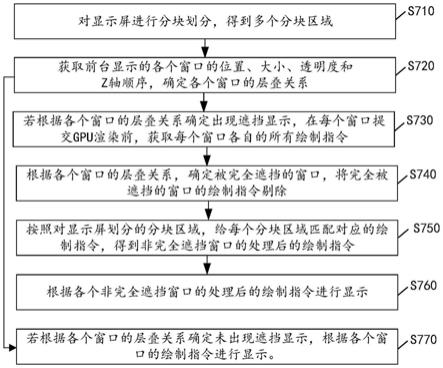
技术特征:
1.一种视觉语言模型获得方法,其特征在于,包括:获取预训练图像和与所述预训练图像对应的文本描述;将所述文本描述进行遮盖处理获得掩码文本描述;获取初始视觉语言模型;将所述预训练图像和所述掩码文本描述输入所述初始视觉语言模型以获得预测文本描述;基于所述预训练图像、所述文本描述、所述掩码文本描述和所述预测文本描述通过所述初始视觉语言模型执行多个预训练任务以训练所述初始视觉语言模型,获得预训练后的视觉语言模型以处理图像文本任务。2.根据权利要求1所述的方法,其特征在于,所述将所述预训练图像和所述掩码文本描述输入所述初始视觉语言模型以获得预测文本描述包括:将所述预训练图像和所述掩码文本描述输入所述初始视觉语言模型,获得所述初始视觉语言模型输出的预测文本描述分布;从所述预测文本描述分布中采样获得所述预测文本描述。3.根据权利要求2所述的方法,其特征在于,所述初始视觉语言模型包括初始句子编码器、初始目标编码器、初始跨模态编码器和初始跨模态解码器;所述多个预训练任务包括掩码语言建模任务和掩码句子生成任务;所述预测文本描述分布包括第一编码器预测文本描述分布和第一解码器预测文本描述分布;所述预测文本描述包括编码器预测文本描述和解码器预测文本描述;所述将所述预训练图像和所述掩码文本描述输入所述初始视觉语言模型,获得所述初始视觉语言模型输出的预测文本描述分布包括:将所述预训练图像输入所述初始目标编码器获得第一目标编码器输出;将所述掩码文本描述输入所述初始句子编码器获得第一句子编码器输出;将所述第一目标编码器输出与所述第一句子编码器输出通过所述初始跨模态编码器执行所述掩码语言建模任务,获得所述第一编码器预测文本描述分布;将所述第一目标编码器输出与所述第一句子编码器输出通过所述初始跨模态解码器执行所述掩码句子生成任务,获得所述第一解码器预测文本描述分布;所述从所述预测文本描述分布中采样获得所述预测文本描述包括:从所述第一编码器预测文本描述分布中采样获得所述编码器预测文本描述;从所述第一解码器预测文本描述分布中采样获得所述解码器预测文本描述。4.根据权利要求3所述的方法,其特征在于,还包括:将所述预训练图像进行遮盖处理获得掩码预训练图像;所述多个预训练任务还包括掩码目标分类任务和图像句子匹配任务;所述基于所述预训练图像、所述文本描述、所述掩码文本描述和所述预测文本描述通过所述初始视觉语言模型执行多个预训练任务以训练所述初始视觉语言模型包括:以所述文本描述为标签基于所述第一编码器预测文本描述分布获得第一掩码语言建模损失;将所述文本描述输入所述初始句子编码器获得第二句子编码器输出;
将所述掩码预训练图像输入所述初始目标编码器获得第二目标编码器输出;将所述第二目标编码器输出与所述第二句子编码器输出通过所述初始跨模态编码器执行所述掩码目标分类任务,获得第一编码器预测目标分布;以所述预训练图像为标签基于所述第一编码器预测目标分布获得第一掩码目标分类损失;根据所述第二句子编码器输出和所述第一目标编码器输出执行所述图像句子匹配任务,获得图像句子匹配损失;以所述文本描述为标签基于所述第一解码器预测文本描述分布获得第一掩码句子生成损失;基于所述编码器预测文本描述、所述解码器预测文本描述和所述预训练图像通过所述初始句子编码器、所述初始目标编码器、所述初始跨模态编码器和所述初始跨模态解码器获得第二阶段任务损失;基于所述第一掩码语言建模损失、所述第一掩码目标分类损失、所述图像句子匹配损失、所述第一掩码句子生成损失和所述第二阶段任务损失获得预训练总损失函数;利用所述预训练总损失函数训练所述初始句子编码器、所述初始目标编码器、所述初始跨模态编码器和所述初始跨模态解码器。5.根据权利要求4所述的方法,其特征在于,所述基于所述编码器预测文本描述、所述解码器预测文本描述和所述预训练图像通过所述初始句子编码器、所述初始目标编码器、所述初始跨模态编码器和所述初始跨模态解码器获得第二阶段任务损失包括:将所述编码器预测文本描述输入所述初始句子编码器获得第三句子编码器输出;将所述第一目标编码器输出与所述第三句子编码器输出通过所述初始跨模态编码器执行所述掩码语言建模任务,获得第二编码器预测文本描述分布;以所述文本描述为标签基于所述第二编码器预测文本描述分布获得第二掩码语言建模损失;将所述第一目标编码器输出与所述第三句子编码器输出通过所述初始跨模态编码器执行所述掩码目标分类任务,获得第二编码器预测目标分布;以所述预训练图像为标签基于所述第二编码器预测目标分布获得第二掩码目标分类损失;将所述解码器预测文本描述输入所述初始句子编码器获得第四句子编码器输出;将所述第一目标编码器输出与所述第四句子编码器输出通过所述初始跨模态解码器执行所述掩码句子生成任务,获得第二解码器预测文本描述分布;以所述文本描述为标签基于所述第二解码器预测文本描述分布获得第二掩码句子生成损失;将所述第二掩码语言建模损失、所述第二掩码目标分类损失和所述第二掩码句子生成损失相加获得所述第二阶段任务损失。6.根据权利要求4所述的方法,其特征在于,所述基于所述编码器预测文本描述、所述解码器预测文本描述和所述预训练图像通过所述初始句子编码器、所述初始目标编码器、所述初始跨模态编码器和所述初始跨模态解码器获得第二阶段任务损失包括:将所述编码器预测文本描述输入所述初始句子编码器获得第三句子编码器输出;
将所述第一目标编码器输出与所述第三句子编码器输出通过所述初始跨模态解码器执行所述掩码句子生成任务,获得第三解码器预测文本描述分布;以所述文本描述为标签基于所述第三解码器预测文本描述分布获得第三掩码句子生成损失;将所述解码器预测文本描述输入所述初始句子编码器获得第四句子编码器输出;将所述第一目标编码器输出与所述第四句子编码器输出通过所述初始跨模态编码器执行所述掩码语言建模任务,获得第三编码器预测文本描述分布;以所述文本描述为标签基于所述第三编码器预测文本描述分布获得第三掩码语言建模损失;将所述第一目标编码器输出与所述第四句子编码器输出通过所述初始跨模态编码器执行所述掩码目标分类任务,获得第三编码器预测目标分布;以所述预训练图像为标签基于所述第三编码器预测目标分布获得第三掩码目标分类损失;将所述第三掩码语言建模损失、所述第三掩码目标分类损失和所述第三掩码句子生成损失相加获得所述第二阶段任务损失。7.根据权利要求4所述的方法,其特征在于,所述基于所述编码器预测文本描述、所述解码器预测文本描述和所述预训练图像通过所述初始句子编码器、所述初始目标编码器、所述初始跨模态编码器和所述初始跨模态解码器获得第二阶段任务损失包括:将所述编码器预测文本描述输入所述初始句子编码器获得第三句子编码器输出;将所述第一目标编码器输出与所述第三句子编码器输出通过所述初始跨模态解码器执行所述掩码句子生成任务,获得第三解码器预测文本描述分布;以所述文本描述为标签基于所述第三解码器预测文本描述分布获得第三掩码句子生成损失;将所述解码器预测文本描述输入所述初始句子编码器获得第四句子编码器输出;将所述第一目标编码器输出与所述第四句子编码器输出通过所述初始跨模态编码器执行所述掩码语言建模任务,获得第三编码器预测文本描述分布;以所述文本描述为标签基于所述第三编码器预测文本描述分布获得第三掩码语言建模损失;将所述第一目标编码器输出与所述第四句子编码器输出通过所述初始跨模态编码器执行所述掩码目标分类任务,获得第三编码器预测目标分布;以所述预训练图像为标签基于所述第三编码器预测目标分布获得第三掩码目标分类损失;所述第二阶段任务损失包括所述第三掩码语言建模损失、所述第三掩码目标分类损失和所述第三掩码句子生成损失;所述基于所述第一掩码语言建模损失、所述第一掩码目标分类损失、所述图像句子匹配损失、所述第一掩码句子生成损失和所述第二阶段任务损失获得预训练总损失函数包括:获取编解码器切换参数;基于所述第一掩码语言建模损失、所述第一掩码目标分类损失、所述图像句子匹配损
失、所述第一掩码句子生成损失、所述第二阶段任务损失和所述编解码器切换参数获得预训练总损失函数。8.一种视觉语言任务处理方法,其特征在于,包括:获取待处理任务的任务输入数据;将所述任务输入数据经由通过如权利要求1-7任一项所述的方法获得的预训练后的视觉语言模型进行处理;获得所述预训练后的视觉语言模型输出的任务处理结果。9.一种视觉语言模型获得装置,其特征在于,包括:数据获取模块,用于获取预训练图像和与所述预训练图像对应的文本描述;掩码处理模块,用于将所述文本描述进行遮盖处理获得掩码文本描述;模型初始化模块,用于获取初始视觉语言模型;第一预训练模块,用于将所述预训练图像和所述掩码文本描述输入所述初始视觉语言模型以获得预测文本描述;第二预训练模块,用于基于所述预训练图像、所述文本描述、所述掩码文本描述和所述预测文本描述通过所述初始视觉语言模型执行多个预训练任务以训练所述初始视觉语言模型,获得预训练后的视觉语言模型以处理图像文本任务。10.一种视觉语言任务处理装置,其特征在于,包括:数据获取模块,用于获取待处理任务的任务输入数据;任务处理模块,用于将所述任务输入数据经由通过如权利要求1-7任一项所述的方法获得的预训练后的视觉语言模型进行处理;结果输出模块,用于获得所述预训练后的视觉语言模型输出的任务处理结果。11.一种设备,包括:存储器、处理器及存储在所述存储器中并可在所述处理器中运行的可执行指令,其特征在于,所述处理器执行所述可执行指令时实现如权利要求1-8任一项所述的方法。12.一种计算机可读存储介质,其上存储有计算机可执行指令,其特征在于,所述可执行指令被处理器执行时实现如权利要求1-8任一项所述的方法。
技术总结
本公开提供一种视觉语言模型获得方法、视觉语言任务处理方法、装置、设备及存储介质,涉及人工智能技术领域。该方法包括:获取预训练图像和与所述预训练图像对应的文本描述;将所述文本描述进行遮盖处理获得掩码文本描述;获取初始视觉语言模型;将所述预训练图像和所述掩码文本描述输入所述初始视觉语言模型以获得预测文本描述;基于所述预训练图像、所述文本描述、所述掩码文本描述和所述预测文本描述通过所述初始视觉语言模型执行多个预训练任务以训练所述初始视觉语言模型,获得预训练后的视觉语言模型以处理图像文本任务。该方法实现了一定程度上提高训练后的视觉语言模型处理任务的准确度。理任务的准确度。理任务的准确度。
技术研发人员:潘滢炜 李业豪 姚霆 梅涛
受保护的技术使用者:北京京东世纪贸易有限公司
技术研发日:2020.07.31
技术公布日:2021/12/13
再多了解一些
本文用于企业家、创业者技术爱好者查询,结果仅供参考。