技术特征:
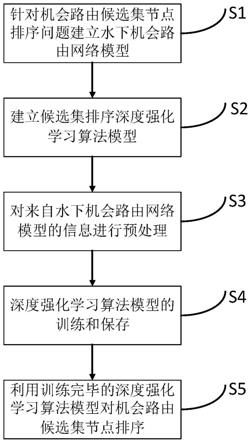
1.一种深度强化学习的机会路由候选集节点排序方法,其特征在于,包括以下步骤:步骤1:针对机会路由候选集节点排序问题建立水下机会路由网络模型;建立水下机会路由网络模型包括对深度强化学习智能体的状态、动作及奖励函数的定义,具体如下:深度强化学习智能体的状态定义为发送节点的候选集节点信息;对于发送节点i,状态被定义为c
i
为节点i的候选集;为节点i的候选集节点j的信息,其中,e
j
代表节点j的剩余能量,d
j
代表节点j的深度,代表邻居节点j与节点i之间的距离,代节点j与sink节点之间的距离,n
j
代表节点j的邻居节点个数;状态s
i
是一个二维数组,每一行对应一个一共有|c
i
|行;深度强化学习智能体的动作定义为发送节点所采用的一种候选集排序结果,发送节点i采取的动作用a
i
表示,发送节点的动作空间是该节点候选集所有可能的排列顺序;对于发送节点i,可以选择的动作有|c
i
|!种;奖励函数的定义根据下一时刻转发节点和状态的不同可以分为三种情况(1)当下一时刻转发节点j是sink节点时,此时获得r
sink
奖励;(2)当下一时刻转发节点j的候选集信息为空,j不能将数据包转发出去,此时获得r
null
奖励;(3)当下一时刻转发节点j可以转发数据包,此时如果j是优先级最高的节点,则获取的这种情况下最大的奖励值r
max
;如果j是优先级最低的节点,则获取的这种情况下最小的奖励值r
mi
;否则获取的奖励值根据节点j所在候选集结果中的序号以及候选集节点的个数在r
max
和r
min
之间呈等差数列的形式下降;步骤2:建立候选集排序深度强化学习算法模型,其中包括策略网络和价值网络;所述的策略网络将t时刻的状态s
t
作为输入,计算并输出所有候选集节点优先级的概率分布p
t
,然后根据概率分布生成候选集排序结果即动作a
t
;所述的价值网络根据输入的t时刻状态s
t
,计算并输出该状态对应的价值估计v
t
;步骤3:对来自水下机会路由网络模型的数据进行解析,得到当前t时刻的候选集节点信息s
t
、候选集节点序号列表clist
t
、奖励值r
t
以及此时发送数据包节点的序号id
t
;对候选集节点信息s
t
中每个特性进行归一化;步骤4:利用深度强化学习智能体与水下机会路由网络模型进行交互,采取迭代试错的学习方法训练并保存深度强化学习算法模型;步骤4.1:深度强化学习智能体与水下机会路由网络模型交互生成决策序列,深度强化学习智能体根据t时刻候选集节点信息s
t
计算得到候选集节点转发优选级分布p
t
,并且根据p
t
生成候选集排序结果a
t
,发送节点将排序结果添加到包头中并广播数据包,水下机会路由网络模型根据候选集节点转发情况,反馈给智能体id
t 1
、r
t 1
、s
t 1
和clist
t 1
信息;深度强化学习智能体通过上述交互方式得到决策序列o
t
=<s
t
,p
t
,a
t
,id
t 1
,r
t 1
,s
t 1
>;其中,id
t 1
表示候选集中负责实际转发数据包的节点序号;r
t 1
是在状态s
t
时执行动作a
t
转移到状态s
t 1
获取的奖励;s
t 1
表示转发数据包节点id
t 1
的候选集信息;clist
t 1
表示
s
t 1
对应候选集节点序号的列表;步骤4.2:深度强化学习智能体根据一个完整的决策序列o
t
,计算t时刻的时序差分误差δ
t
=r
t 1
v
t 1
‑
v
t
,根据价值网络的损失函数l
c
计算的误差值使用梯度下降算法更新价值网络的参数;其中,v
t
和v
t 1
分别是将s
t
和s
t 1
输入到价值网络中得到的价值估计;价值网络的损失函数l
c
为:l
c
=δ
t
*δ
t
步骤4.3:根据策略网络的损失函数l
a
计算的误差值使用梯度下降算法更新策略网络的参数;策略网络的损失函数l
a
为:其中,|a
t
|为t时刻候选集排序结果中节点的个数;yk为根据实际候选集节点转发情况生成的节点k的标签值,是1*|a
t
|维独热编码形式的向量,在y
k
中实际转发节点id
t 1
对应的下标为1,其余的下标为零;步骤4.4:重复步骤4.1到步骤4.3,深度强化学习算法每经过固定次数的更新保存一次算法模型,直到满足预设的最大训练次数或收敛条件,最终得到训练完毕的深度强化学习算法模型;步骤5:利用训练完毕的深度强化学习算法模型对机会路由候选集节点排序;深度强化学习智能体从水下机会路由网络模型获取当前发送节点的候选集信息s
t
,然后将s
t
输入到训练完毕的深度强化学习算法模型中的策略网络,策略网络计算得到候选集排序结果a
t
,机会路由网络模型中的发送节点将a
t
添加到数据包包头中并广播数据包,候选集节点根据自己在a
t
的中排序进行机会转发,负责转发数据包的候选集节点同样将自己的候选集信息s
t 1
传输给深度强化学习模型并获取对应的候选集排序结果a
t 1
,如此不断的重复上述过程,最终得到所有水下机会路由网络模型中发送节点的候选集排序结果。
技术总结
本发明属于水下声学传感器网络技术领域,具体涉及一种深度强化学习的机会路由候选集节点排序方法。本发明克服了现有机会路由候选集节点排序算法存在考虑因素单一和适应性差等问题,利用深度强化学习智能体与水下机会路由网络模型进行交互,使用深度神经网络拟合候选集节点信息与节点转发优先级的关系。本发明结合了深度学习和强化学习的优势,智能体通过与水下机会路由网络模型交互来自动学到一个机会路由候选集节点排序算法,此过程极少依赖人工经验和外部数据信息。本发明使得候选集节点排序更加智能,且适应性更好。且适应性更好。且适应性更好。
技术研发人员:冯晓宁 刘朋 曲立平 兰海燕
受保护的技术使用者:哈尔滨工程大学
技术研发日:2021.09.09
技术公布日:2021/12/11
再多了解一些
本文用于企业家、创业者技术爱好者查询,结果仅供参考。