1.本发明涉及慢性病风险评估技术领域,具体的涉及基于多模型算法的慢性病风险评估方法及其系统。
背景技术:
2.随着经济的快速发展,人们的生活节奏也明显加快,并随之产生了一系列的不健康生活方式,进而导致心脑血管疾病、糖尿病和恶性肿瘤等慢性病的发病率、患病率和死亡率持续上升。慢性病是一大类受环境因素和遗传因素共同影响的多因素疾病,是由多种危险因素综合作用产生的结果。慢性病起病隐匿,潜伏期长、病情进展快,很多患者难以及时发现及治疗。
3.慢性病的治疗需要在日常生活中控制生活习惯,降低慢性病的发病。对于慢性病的发展评估,基本上依靠医生的个人经验,但是慢性病的病情发展由多种因素造成,单纯依靠医生的个人经验,特别是在落后地区医疗资源相对较缺乏的情况下,医生难以对慢性病患者的病情给出较准确的判断并进行针对性的治疗,并且慢性病初期时,慢性病的症状有可能没有展现出来,导致患者对慢性病的风险认知并不清楚,不能及时到医院进行检查和接受治疗。
4.因此,如何便捷地检测出用户患慢性病的风险成为亟需解决的问题。
技术实现要素:
5.本发明的目的在于克服以上技术问题提出基于多模型算法的慢性病风险评估方法。
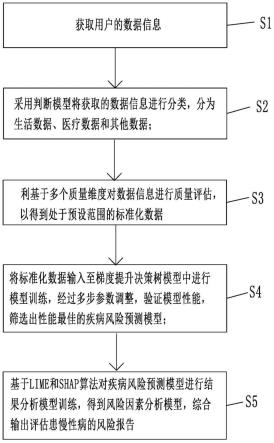
6.为实现上述目的,本发明采用的技术方案如下:基于多模型算法的慢性病风险评估方法,包括以下方法:
7.s1、获取用户的数据信息;
8.s2、采用判断模型将获取的数据信息进行分类,分为生活数据、医疗数据和其他数据;
9.s3、基于多个质量维度对数据信息进行质量评估,以得到处于预设范围的标准化数据;
10.s4、将标准化数据输入至梯度提升决策树模型中进行模型训练,经过多步参数调整,验证模型性能,筛选出性能最佳的疾病风险预测模型;
11.s5、基于lime和shap算法对疾病风险预测模型进行结果分析模型训练,得到风险因素分析模型,综合输出评估患慢性病的风险报告。
12.进一步的,所述基于多个质量维度对数据信息进行质量评估的方法包括:
13.s301、基于多个质量维度对数据信息进行质量评估,将数据质量分为待处理数据和可用数据两类;
14.s302、通过填补算法对所述待处理数据进行预处理,得到处于预设范围的标准化
数据。
15.进一步的,所述填补算法包括中位数填补、lstm和cnn时序填补、向后填补和随机森林填补中的一种或多种。
16.进一步的,利用smote算法对步骤s3中得到的标准化数据进行正负样本平衡处理。
17.进一步的,所述正负样本平衡处理包括用算法删除部分样本,使得数据集正负样本平衡。
18.进一步的,所述将标准化数据输入至梯度提升决策树模型中进行训练包括:
19.s401、将标准化数据通过梯度提升决策树算法进行维度重要性排序与筛选,并提取主要维度数据;
20.s402、将主要维度数据作为梯度提升决策树模型的输入,训练梯度提升决策树模型直至训练误差达到局部最优,得到疾病风险预测模型;
21.s403、基于lightgbm算法对疾病风险预测模型进行模型训练,获取慢性病风险概率;
22.s404、通过sigmoid概率映射方法将所述慢性病风险概率转化为患慢性病的风险等级。
23.进一步的,所述主要维度数据包括饮食组成维度、身体健康维度、运动情况维度和生活习惯维度中的一种或多种。
24.进一步的,还包括根据慢性病的风险等级和风险因素溯源推荐相关改善慢性病的健康信息。
25.基于多模型算法的慢性病风险评估系统,包括:
26.获取模块,用于获取用户的数据信息;
27.处理模块,用于将获取的数据信息基于多个质量维度进行质量评估,并输入至梯度提升决策树模型中进行训练,构建得到疾病风险预测模型;
28.评估模块,用于根据疾病风险预测模型输出结果,利用lightgbm算法评估慢性病的风险等级,利用lime和shap算法输出风险因素。
29.一种计算机可读存储介质,所述计算机可读存储介质存储有计算机程序,所述计算机程序被处理器执行时使所述处理器实现如上述的基于多模型算法的慢性病风险评估方法。
30.由上述对本发明的描述可知,与现有技术相比,本发明提供的一种基于多模型算法的慢性病风险评估方法具有的有益效果:本发明通过对获取的数据信息进行预处理,将处理后数据发送至梯度决策树模型内进行学习,得到初步的疾病风险预测模型,所得模型能对未知患者五年内慢性病发病情况进行预测,进一步通过lime算法对模型预测过程和输出结果进行解释,根据用户特征给出风险因素,以及相应健康建议,使用户对慢性病的风险认知更加清楚,疾病风险预测模型是实时动态变化的,会根据不同用户身体状况的不同情况做不同结果,能及时到医院进行检查和接受治疗。
附图说明
31.图1为本发明基于多模型算法的慢性病风险评估方法的流程框图;
具体实施方式
32.以下将结合本发明实施例中的附图对本发明中的技术方案进行清楚、完整地描述,显然,所描述的实施例仅是本发明的一部分实施例,而不是全部的实施例。基于本发明中的实施例,本领域普通技术人员在没有做出创造性劳动前提下所获得的所有其他实施例,都应当属于本发明保护的范围。
33.需要说明的是,本发明的说明书和权利要求书术语“包括”和“具有”以及他们的任何变形,意图在于覆盖不排他的包含,例如,包含了一系列步骤或单元的过程、方法、系统、产品或设备不必限于清楚地列出的那些步骤或单元,而是可包括没有清楚地列出的或对于这些过程、方法、产品或设备固有的其它步骤或单元。
34.如图1所示,基于多模型算法的慢性病风险评估方法,包括以下方法:
35.s1、获取用户的数据信息;
36.其中,所述数据信息包括性别、年龄、是否怀孕、直系亲属中是否有糖尿病患者、体质指数、睡眠时间、饮食习惯、每天运动时间、空腹血糖值、餐后血糖值、血脂值、耐糖量试验值中的一种或多种,根据不同慢病的情况会有收集不同慢病数据,可以是糖尿病、高血压、冠心病以及心力衰竭等不同的慢性疾病,
37.s2、采用判断模型将获取的数据信息进行分类,分为生活数据、医疗数据和其他数据;
38.其中,所述数据信息包括性别、年龄、是否怀孕、直系亲属中是否有糖尿病患者、体质指数、睡眠时间、饮食习惯、每天运动时间、空腹血糖值、餐后血糖值、血脂值、耐糖量试验值中的一种或多种,根据不同慢病的情况会有收集不同慢病数据,可以是糖尿病、高血压、冠心病以及心力衰竭等不同的慢性疾病。
39.s3、基于多个质量维度对数据信息进行质量评估,以得到处于预设范围的标准化数据;
40.其中,所述质量维度包括数据信息的准确性、完整性、合理性和可信度,所述基于多个质量维度对数据信息进行质量评估的方法包括:
41.s301、基于多个质量维度对数据信息进行质量评估,将数据质量分为待处理数据和可用数据两类;
42.s302、通过填补算法对所述待处理数据进行预处理,得到处于预设范围的标准化数据。
43.其中,所述填补算法包括中位数填补、lstm和cnn时序填补、向后填补和随机森林填补中的一种或多种,所述待处理数据进行合理填补前,要先判断预处理数据是否为时间序列,如果待处理数据是时间序列,可采用如下方法对数据进行数据填补:1)采用lstm和cnn相结合的方法,能根据历史时间数据对待处理数据中的缺失值进行较为合理的填补;2)对于多维度同时缺失的个体来说,利用随机森林填补能综合考虑多个维度信息对待处理数据进行数据填补;3) 对于缺失较少的数据,采用较为常规的中位数填补和向后填补相结合的方法对待处理数据进行数据填补。如果待处理数据不是时间序列,则采用知识图谱对待处理数据进行合理填补,可得到正确性和合理性均处于预设范围的标准化数据。
44.利用smote算法对步骤s3中得到的标准化数据进行正负样本平衡处理,所述正负样本平衡处理包括用算法删除部分样本,使得数据集正负样本平衡,可解决正负样本不平
衡的问题,利于提高模型区分少数类样本的能力。若不经过正负样本平衡处理,会造成模型倾向于对多数类的分类精度高,而少数类的分类精度低,如数据集中正常人比患者多很多,则模型会倾向于关注正常人的识别,对于关键的患者则识别能力较弱,因此将负类样本(即正常人)进行欠采样,即用算法删除部分样本,使得数据集正负样本平衡。
45.s4、将标准化数据输入至梯度提升决策树模型中进行模型训练,经过多步参数调整,验证模型性能,筛选出性能最佳的疾病风险预测模型;
46.其中,将标准化数据输入至梯度提升决策树模型中进行训练包括:
47.s401、将标准化数据通过梯度提升决策树算法进行维度重要性排序与筛选,并提取主要维度数据;
48.s402、将主要维度数据作为梯度提升决策树模型的输入,训练梯度提升决策树模型直至训练误差达到局部最优,得到疾病风险预测模型,所述主要维度数据包括饮食组成维度、身体健康维度、运动情况维度和生活习惯维度中的一种或多种,因此,所涵盖的评分维度更加全面,且所需维度数据较容易收集,方便用户操作;
49.s403、基于lightgbm算法对疾病风险预测模型进行模型训练,获取慢性病风险概率;
50.其中,训练时所用到损失函数:
[0051][0052]
s404、通过sigmoid概率映射方法将所述慢性病风险概率转化为患慢性病的风险等级,将所述风险等级定义为极低风险(0-5%)、低风险(5%-15%)、中低风险(15%-25%)、中风险(25-35%)、中高风险(35%-50%)、高风险(50%-65%) 和极高风险(65%-100%),使用户可一目了然自己的身体状况,及时就医。
[0053]
其中,所述疾病风险预测模型包括梯度决策树、输出映射函数和风险因素提示,所述梯度决策树用以给出患病概率,所述输出映射函数用以给出风险等级。
[0054]
所述输出映射函数公式:
[0055][0056]
其中,x为模型输出结果,a为矫正系数
[0057]
s5、基于lime和shap算法对疾病风险预测模型进行结果分析模型训练,得到风险因素分析模型,综合输出评估患慢性病的风险报告。
[0058]
其中,lime算法步骤为:用户将数据变体提供给机器学习模型时,lime预测会发生的疾病情况;lime生成一个新的数据集,该数据集由扰动的样本和已经训练好的黑箱模型生成的相应预测组成;在这个新数据集上,lime训练一个可解释的模型,该模型由采样实例与感兴趣实例的接近程度加权,所述模型可以是可解释模型中的任何一种,例如lasso回归。最终得到的模型应该是机器学习模型预测在本地的良好近似值,即:(1)选择一个样例x,进行可解释的 n次扰动,生成局部样本x';(2)使用复杂模型对x和x'进行预测;(3) 对采样后的样本,拟合一个简单的模型,如lasso回归得到模型的权重。
[0059]
公式如下:
[0060][0061]
x为模型解释样例,g为解释模型,f为原来的黑盒模型,ω(g)为模型复杂度,π
x
为近似度量(定义实例x周围的邻域有多大)
[0062]
shap算法是将通过特征值对输出的贡献,对所有可能的特征值组合进行加权与求和,计算相应的shapley值,其公式如下:
[0063][0064][0065]
其中s是模型中使用的特征的子集,x是要解释的实例的特征值的矢量,p是特征数,val(s)是对集合s中的特征值的预测。
[0066]
lime算法能输出针对单个患者的风险因素分支,通过排序算法确定前五个主要风险因素,shap算法可对患者的数据训练集能给出相应解释,帮助医生理解疾病风险预测模型的内在运作方式,确定模型可靠程度,两种算法结合可更加准确、合理地输出评估患慢性病的风险报告。
[0067]
还包括根据慢性病的风险等级和风险因素溯源推荐相关改善慢性病的健康信息。
[0068]
例如对于糖尿病患者用户,可以根据其当前状态实时更新风险因素,如糖尿病患者前一天血糖值较高,则疾病风险预测模型会给出当前血糖较高作为风险因素,并给出相应饮食建议,第二天血糖恢复正常,则相应风险因素就会消除。
[0069]
如发现患者为低风险等级,风险报告主要强调生活习惯及饮食健康部分,提出需要保持的生活习惯和健康建议;
[0070]
如为中风险等级,风险报告主要强调相应风险体检指标,需要去医院复查的项目,并提出风险指标的危害以及不良生活习惯的纠正建议;
[0071]
如为中高风险及高危风险等级,风险报告则发出健康警示,提出生活方式干预可能已经不适合用户,需要及时就医,以及相应的医疗指引。
[0072]
基于多模型算法的慢性病风险评估系统,包括:
[0073]
获取模块,用于获取用户的数据信息;
[0074]
处理模块,用于将获取的数据信息基于多个质量维度进行质量评估,并输入至梯度提升决策树模型中进行训练,构建得到疾病风险预测模型;
[0075]
评估模块,用于根据疾病风险预测模型输出结果,利用lightgbm算法评估慢性病的风险等级,利用lime和shap算法输出风险因素。
[0076]
一种计算机可读存储介质,所述计算机可读存储介质存储有计算机程序,所述计算机程序被处理器执行时使所述处理器实现如上述的基于多模型算法的慢性病风险评估方法。
[0077]
由上述对本发明的描述可知,与现有技术相比,本发明提供的一种基于多模型算法的慢性病风险评估方法,本发明通过对获取的数据信息进行预处理,将处理后数据发送至梯度决策树模型内进行学习,得到初步的疾病风险预测模型,所得模型能对未知患者五年内慢性病发病情况进行预测,进一步通过lime 算法和shap算法对模型预测过程和输出
结果进行解释,根据用户特征给出风险因素,以及相应健康建议,使用户对慢性病的风险认知更加清楚,能及时到医院进行检查和接受治疗。
[0078]
上述仅为本发明的若干具体实施方式,但本发明的设计构思并不局限于此,凡利用此构思对本发明进行非实质性的改动,均应属于侵犯本发明保护范围的行为。
再多了解一些
本文用于创业者技术爱好者查询,仅供学习研究,如用于商业用途,请联系技术所有人。
