1.本发明涉及一种基于硬件计算图的深度学习编译器,属于深度学习编译器的硬件资源利用技术领域,实现深度学习模型的自动化部署。
背景技术:
2.近些年来,深度学习在很多场景下得到了广泛的应用,例如:图像识别、目标检测、语义分割等等。与此同时,对深度学习模型进行高效地加速越来越受到学术界以及工业界的关注。因此,如何对模型进行高效且高性能的自动化部署变得尤其重要。对此,深度学习编译器被提出。在软件架构上,目前的主流方案是将外部框架定义的模型转换为编译器的内部表示,结合目标硬件平台的资源数量进行优化之后,生成硬件代码。
3.然而,随着深度学习的应用场景的不断扩张,以及社区对于模型精度的不断追求,模型拓扑变得越来越复杂。现有的编译器在面对复杂拓扑时,只能通过使用硬件资源更多且更昂贵的硬件平台进行有限的支持,极大地提高了部署成本。
技术实现要素:
4.发明目的:目前深度学习编译器在硬件资源利用率方面表现欠佳,只能通过使用硬件资源更多且更昂贵的硬件平台来提高性能。并且随着模型拓扑复杂度的不断提高,这些方式并不能保证部署的成功。本发明提供了一种基于硬件计算图的深度学习编译器,能够使用更少的硬件资源对复杂拓扑的模型进行部署,并有效提高了硬件资源的利用效率。
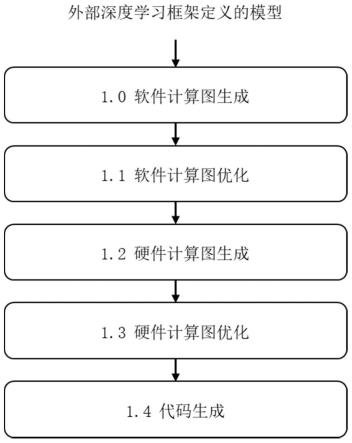
5.技术方案:一种基于硬件计算图的深度学习编译器,包括软件计算图生成模块,硬件计算图生成模块,软件计算图优化模块,硬件计算图优化模块,以及代码生成模块;
6.所述软件计算图生成模块用于将外部框架定义的深度学习模型转化为内部软件计算图;
7.所述软件计算图优化模块用于对软件计算图进行优化;
8.所述硬件计算图生成模块,在软件计算图的指导下,先生成基础节点集合,再使用贪心搜索对节点集合调整直到满足整个深度学习模型所需的计算要求,最后生成硬件计算图的边;
9.所述硬件计算图优化模块,用于对硬件计算图进行优化;
10.代码生成模块用于生成深度学习模型对应的硬件代码以及仿真代码。
11.所述软件计算图生成模块中,根据硬件的实现效率,定义软件计算图中的节点类型与边;对模型文件进行解析并转换;软件计算图中的节点为个深度学习模型的运算单元,包括填充、卷积、最大池化、平均池化、全局池化、加法、拼接等算子;软件计算图中的边代表节点之间传递的数据。
12.所述硬件计算图生成模块中,硬件计算图中的节点类型与软件计算图节点类型一一对应,但硬件计算图中的一个节点代表硬件平台上的一个处理单元,即节点和边分别代表芯片内部的模块与硬连线。并且在实际实现时,在节点的每个输入端口以及输出端口处
分别添加一个多路选择器和多路分配器。其中多路选择器用于选择当前硬件节点的前继节点,多路分配器用于选择当前硬件节点的后继节点。在硬件计算图生成模块中,软件计算图节点到硬件计算图节点的映射方式为:基于多核处理器的思想,本发明能够在二者之间进行一对多的映射。对于软件计算图中的某个卷积节点,当现有硬件计算图中的任一卷积节点都无法满足计算要求时,则对该软件计算图中的卷积节点权重的输出通道维度进行分割(ocp),将该卷积节点的权重数据分发到多个硬件节点(硬件计算图中的节点)进行计算;对于软件计算图中的某个池化节点,当现有硬件计算图中的任一池化节点都无法满足计算要求时,则对软件计算图中的所述池化节点的输入数据的宽度维度进行分割(iwp)。加上不需要对节点进行分割(np)的情况,提出了9种硬件计算图节点之间的连接方式,分别是:
13.np
→
np,当前软件计算图节点及其前继节点都不需要分割;
14.np
→
iwp,当前软件计算图节点需要在输入数据的宽度维度进行分割,前继节点不需要分割;
15.np
→
ocp,前继软件计算图节点不需要分割,当前软件计算图节点需要在权重数据的输出通道维度进行分割;
16.iwp
→
np,当前软件计算图节点不需要分割,前继软件计算图节点需要在输入数据的宽度维度进行分割;
17.iwp
→
iwp,当前软件计算图节点和前继软件计算图节点都需要在输入数据的宽度维度进行分割;
18.iwp
→
ocp,当前软件计算图节点在权重数据的输出通道维度进行分割,前继软件计算图节点都需要在输入数据的宽度维度进行分割;
19.ocp
→
np,当前软件计算图节点不需要分割,前继软件计算图节点需要在权重数据的输出通道维度进行分割;
20.ocp
→
iwp,当前软件计算图节点在权重数据的输出通道维度进行分割,前继软件计算图节点需要在权重数据的输出通道维度进行分割;
21.以及ocp
→
ocp,当前软件计算图节点和前继软件计算图节点都需要在权重数据的输出通道维度进行分割。
22.并且将这9种连接方式划分为2个步骤进行实现,例如对于ocp
→
iwp,在前继软件计算图节点所需要的所有硬件模块的输出端口添加ocp
→
iwp后端模块,在当前层所需要的硬件模块的输入端口添加ocp
→
iwp前端模块;其余连接方式按照相同的机制分别在相应的硬件模块的输入或输出端口添加前端模块或后端模块。
23.所述将外部框架定义的模型转化为内部的软件计算图的具体步骤为:输入由外部框架定义且训练完成的模型,解析其中的算子;基于深度优先的原则,对节点进行重排序。
24.所述软件计算图优化模块对软件计算图进行优化的具体步骤为:对软件计算图中含有超过2个输入端口的节点,分别使用多个2输入的节点进行实现并替换;对含有超过2个输出端口的节点,在其末端添加duplicate算子,用来进行数据的广播;对含有超过2个输出端口的duplicate算子,使用多个2输出的duplicate算子进行实现并替代。
25.所述生成硬件计算图的步骤具体为:根据软件计算图中节点的种类以及使用硬件资源的数量,对软件计算图的节点进行频度统计,根据频度对节点分配硬件资源(例如,内存大小,计算资源等)。随后基于贪心搜索的思想,综合考虑目标硬件平台的资源总数,并在
软件计算图的指导下,生成能够满足整个模型计算要求的硬件计算图节点集合,硬件计算图节点是对软件计算图节点分配的硬件资源,硬件计算图节点是用来表示硬件资源的一种数据结构。接着根据软件计算图与硬件计算图的节点集合,生成硬件计算图的边,用于体现硬件计算图节点之间的互联关系。在生成硬件计算图边的同时,将软件计算图分割成多个子图,子图之间通过片外存储器进行数据的通信;对这些子图之间的数据进行片外存储的资源分配,使用动态规划进行实现。硬件计算图中的每一个节点都代表一个处理单元,但每次运行时,部分处理单元需要从片外存储器获取数据。
26.所述硬件计算图优化模块中对硬件计算图进行优化的具体步骤为:遍历硬件计算图中的每一条边,对功能重复的边进行裁剪。
27.有益效果:与现有技术相比,本发明提供的基于硬件计算图的深度学习编译器,不但能够使用更少的硬件资源对复杂拓扑的模型进行部署,而且对拓扑复杂度不高的模型也能达到更好的性能。并且本发明能够应用于cpu、gpu、fpga以及人工智能专用芯片等多种硬件平台。
附图说明
28.图1为本发明实施例的工作流程图;
29.图2为本发明实施例的软件计算图的生成流程图;
30.图3为本发明实施例的软件计算图的优化流程图;
31.图4为本发明实施例的硬件计算图的第一阶段生成流程图;
32.图5为本发明实施例的硬件计算图的第二阶段生成流程图;
33.图6为本发明实施例的硬件计算图的边生成流程。
具体实施方式
34.下面结合具体实施例,进一步阐明本发明,应理解这些实施例仅用于说明本发明而不用于限制本发明的范围,在阅读了本发明之后,本领域技术人员对本发明的各种等价形式的修改均落于本技术所附权利要求所限定的范围。
35.当以fpga为目标硬件平台,基于硬件计算图的深度学习编译器,硬件计算图生成模块,软件计算图优化模块,硬件计算图优化模块,以及代码生成模块;工作流程为:软件计算图生成(图2),软件计算图优化(图3),硬件计算图生成(图4),硬件计算图优化(图5)以及代码生成。
36.软件计算图优化模块实现的软件计算图的生成流程如下:(步骤2.0)初始化当前外部深度学习框架定义的模型中算子索引cur为0,(步骤2.1)判断目前编译器是否支持第cur个算子的类型,(步骤2.2)如果编译器不支持当前算子则直接报错退出程序,(步骤2.3)反之根据系统所输入模型中的算子创建其编译器的内部表示节点(也即软件计算图的节点),(步骤2.4)cur递增指向下一个算子,(步骤2.5)重复步骤2.1-步骤2.4,直到模型中所有的算子都被遍历,(步骤2.6)在所输入模型的指导下,确定每个软件计算图节点的前继和后继节点,由此生成软件计算图的边。
37.软件计算图优化模块中,软件计算图的优化流程如下:(步骤3.0)初始化当前软件计算图中算子索引cur为0,(步骤3.1)统计当前节点输入边的数量n以及输出边的数量m,
(步骤3.2)当n小于或等于2时,不进行处理,(步骤3.3)当n大于2时,对输入进行拆分,通过(n-1)个2输入节点进行替换,(步骤3.4)当m小于2时,不进行处理,(步骤3.5)当m大于或等于2时,在当前节点的末端插入一个duplicate算子,该算子的输入为当前节点,输出为当前节点的所有输出边,同时删除当前节点原本的输出边,(步骤3.6)统计当前duplicate节点输出边的数量k,(步骤3.7)当k等于2时,不进行处理,(步骤3.8)当k大于2时,使用(k-1)个duplicate节点进行替换,(步骤3.9)cur递增指向下一个节点,(步骤3.10)重复步骤3.1-步骤3.9,直到软件计算图中所有的节点都被遍历,(步骤3.11)对所有的节点进行深度优先排序。
38.硬件计算图生成模块中,硬件计算图的生成流程包括基础节点生成、节点集合调整、边的生成以及片外存储的分配。
39.基础节点生成,实现根据频度对节点分配硬件资源,基础节点生成流程如下:(步骤4.0)初始化频次统计字典dict,key为节点对象,value为节点频度(即节点出现的次数),初始化当前软件节点(软件计算图中的节点)索引cur为0,(步骤4.1)计算第cur个软件节点所需要的片上存储器大小ram_size,(步骤4.2)通过存储器大小ram_size与当前软件节点的类型生成软件节点的key,(步骤4.3)key对应的频度递增,(步骤4.4)cur指向下一个软件节点,(步骤4.5)重复步骤4.1-步骤4.4,直到软件计算图中所有的节点都被遍历,(步骤4.6)通过将频次统计字典dict中的频度除以软件计算图节点的总数量,得到频率统计字典dict_freq,(步骤4.7)初始化当前key索引cur_k为0,(步骤4.8)获取dict_freq中的第cur_k个key k,(步骤4.9)使用当前key对应的频率dict_freq[k]乘以目标硬件平台的总资源数量,得到分配给当前key的硬件资源,(步骤4.10)cur_k指向下一个key,(步骤4.13)重复步骤4.8-步骤4.10,直到dict_freq中所有的key都被遍历,即得到所有的基础硬件节点。
[0040]
节点集合调整流程如下:(步骤5.0)初始化当前硬件计算图节点索引cur为0,(步骤5.1)从当前节点开始生成设定数量(为防止程序运行时间过长,最多为20)的软件计算子图候选项(也即软件计算图中的一段连续节点集合),(步骤5.2)根据本发明所提出的9种节点之间的连接方式,计算每个子图候选项在当前的硬件计算图节点集合下,所需要的硬件模块类型(例如,卷积,池化等)、配置以及数量,(步骤5.3)根据步骤5.2中的结果,将当前硬件计算图节点集合与输入模型实际需要的节点集合相减,得到二者之间的差距,(步骤5.4)在不超过目标硬件平台的资源总数量的情况,从候选子网络中选择长度最长的一项,(步骤5.5)cur增加到下一轮迭代的起始点,(步骤5.6)对现有的硬件节点集合进行补充,也即根据(步骤5.4)中所选择的子图候选项所需要的硬件节点构建新的硬件计算图节点,并添加到现有硬件节点集合中,(步骤5.7)重复步骤5.1-步骤5.6,直到完成整个软件计算图的遍历。
[0041]
边的生成流程如下:(步骤6.0)初始化软件计算图中当前子图索引cur_g为0以及当前子图中节点索引cur_n为0,(步骤6.1)找出第cur_g个子网络中的第cur_n个节点所需要的硬件计算图节点集合,(步骤6.2)初始化当前软件节点中的输入节点索引cur_input为0,(步骤6.4)若当前输入软件计算图节点同样包含在当前子图中,则为这两个软件计算图节点所需要硬件计算图节点添加边,(步骤6.5)若当前输入软件计算图节点不包含在当前子图中,则为fpga的片外存储通信模块的读端口与当前软件计算图节点所需要的硬件计算图节点之间添加边,(步骤6.6)cur_input递增指向下一个输入端口,(步骤6.7)重复步骤
6.3-步骤6.6,直到当前软件计算图节点所有的输入端口都被遍历,(步骤6.8)初始化当前软件计算图节点中的输入节点索引cur_output为0,(步骤6.10)若当前输出软件计算图节点同样包含在当前子图中,则为这两个软件计算图节点所需要硬件计算图节点添加边,(步骤6.11)若当前输出节点不包含在当前子图中,则为片外存储通信模块的写端口与当前节点之间添加边,(步骤6.12)cur_output递增指向下一个输出端口,(步骤6.13)重复步骤6.9-步骤6.12,直到当前节点所有的输出端口都被遍历,(步骤6.14)cur_n递增指向软件计算图的下一个节点,(步骤6.15)重复步骤6.1-步骤6.14,直到软件计算图中的所有节点都被遍历。
[0042]
硬件计算图优化模块中,硬件计算图的优化流程如下:(步骤7.0)对硬件计算图中的所有硬件节点进行遍历,(步骤7.1)对每个硬件节点的每个输出边进行遍历,(步骤7.2)统计当前硬件节点所有输出边中功能相同的边,(步骤7.3)删去功能重复的输出边。
再多了解一些
本文用于企业家、创业者技术爱好者查询,结果仅供参考。
