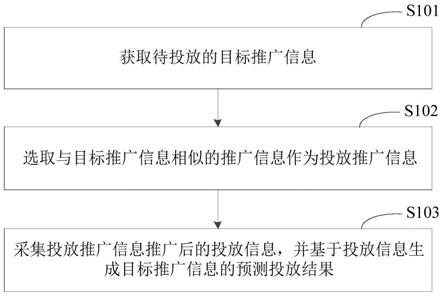
1.本发明涉及图纸识别技术,特别是涉及一种图纸自动识别系统及方法。
背景技术:
2.随着企业定制化需求订单成为部分企业的主要业务增长点,使得定制化产品图纸设计的需求量急剧增加,往往一个合同会产生海量的技术图纸,如何把海量图纸精确定位到企业的生产、采购、质量等系统的每个产品和零部件中,是一件极具费时和挑战的工作。
3.基于此背景,精准定位海量图纸库中特定图纸,并在生产、采购、质量、供应商等环节中按照需要及相应权限调取特定图纸是十分必要的。但目前的海量图纸还是采用人工录入,然后关联页码,再通过页码调动的方式,其效率低,而且容易造成录入信息错误,影响后续的生产、质检等流程。
技术实现要素:
4.有鉴于现有技术的上述缺陷,本发明所要解决的技术问题是提供一种图纸自动识别系统及方法,其通过在图纸上设置定位标识符,利用通过唯一码读取图纸页码,再通过图纸页码精确定位图纸。
5.为实现上述目的,本发明提供了一种图纸自动识别系统,包括:
6.图纸存储管理模块,用于存储、读取、下载图纸;
7.图纸识别及自动分配模块,在每页图纸上加入至少一个唯一码,然后将图纸按页拆分为单张图片,再提取每张图片的文字,通过文字获取唯一码,再将唯一码与页码绑定,然后图纸按照页码顺序依次排序,后续可通过唯一码访问相应页码的图纸;按照各个环节对不同图纸的需求,将每个环节需要的图纸按照页码的方式分配至各个环节,各个环节只能根据唯一码查看已经分配的图纸;
8.图纸识别应用模块,利用唯一码在数据库表中进行检索,获取唯一码对应的页码,根据页码提取相应的图纸,即可进行查看、下载。
9.进一步地,图纸存储管理模块中图纸采用数据库表存储加文件专属存储方式进行管理;数据库表每行存储了文件的保存路径、文件大小、文件原名称、文件保存后的名称;并生成图纸文件的链接地址,可通过链接地址读取、下载图纸文件。
10.进一步地,同一页的唯一码有两个及以上时,两个唯一码之间采用空格、回车、特殊字符隔开。
11.本发明还公开了一种图纸自动识别方法,包括:
12.s100、图纸存储管理,图纸上传并存储在图纸数据库中,图纸的存储采用数据库表存储加文件专属存储方式进行管理;
13.s200、图纸识别及自动分配,将图纸按页拆分为独立的图片,在每页图纸上附加至少一个唯一码,通过唯一码关联页码;根据每个环节需要的图纸对应的页码向每个环节分配可提取的图纸页码;
14.s300、图纸识别应用,通过唯一码识别页码,提取页码对应的图纸。
15.进一步地,s100还包括:
16.s110、创建文件列表,创建文件列表时,先获取数据库存储表;再把上传的文件列表信息会加入到数据表中,数据表每行存储了文件的保存路径、文件大小、文件原名称、文件保存后的名称;最后保存到数据库中;
17.s120、把上传列表文件根据数据库存储信息保存到文件服务器相应的目录中;
18.s130、网页显示文件列表,直接从数据库表中读取文件列表文件信息显示页面上,链接地址为文件服务器接口加文件参数信息;
19.s140、文件下载,通过下载接口传入文件信息,调取文件,从文件服务器中下载文件。
20.进一步地,s200还包括:
21.s210、图纸拆分,把图纸按页拆分为多张单一图片;
22.s220、显示图片处理,采用两种方式显示:标清模式和高清模式,高清模式的清晰度高于标清模式的清晰度;
23.s230、文本识别提取,提取每张图纸上的文本,并根据提取的文本获取唯一码,将唯一码与对应的图纸页码关联,并存储关联信息。
24.更进一步地,s210还包括:
25.s211、识别图纸格式;
26.s212、根据图纸格式属性先获取总页,再进行循环处理每一页,使得图纸按照每一页独立分割;
27.s213、把每页图纸转成位图;
28.s214、将位图生成图片,并保持图片,图片的名称以该图片的页码命名。
29.更进一步地,s220还包括:
30.s221、获取s210拆分后的图片文件名,按照图片文件名将图片进行从小到大的页码排序;
31.s222、组合需要在页面上显示的图片和附加内容;
32.s223、将组合内容转成字符串格式返回页面显示。
33.更进一步地,s230还包括:
34.s231、根据图片格式,利用能读取该格式的软件或方法读取图片;
35.s232、利用文字识别技术识别图片上的文字、字符,以获取页码、唯一码;
36.s233、循环页码,采用获取每张图片的文本,创建文本字典表,把页码、唯一码、文本加入到文本字典表中。
37.进一步地,s300还包括:
38.s310、获取图纸的页面采用循环清单列表,向后台传入唯一码,找到页码写入相应行内;
39.s320、后台循环文本字典表,对比文本中唯一码,取出相应的页码;
40.识别方法:对文本进行循环遍历字符,根据需要识别的头标记和结束标记进行过滤找到唯一码,取出页码。
41.本发明的有益效果是:
42.1、本发明通过对图纸上设置特定的“唯一码”读取图纸对应的页码,再通过图纸页码精确定位图纸,为生产、采购、质量系统提供精确的页码定位接口,使各物流环节能且只能读取需求的图纸,以达到既能满足各部门图纸需求,又能达到图纸保密的要求。
43.2、传统图纸类文档管理系统主要通过人工分配相应图纸,把一份几十页甚至上百页的图纸,手工拆分到生产、采购、质量等岗位的每个生产计划单的每个产品上,或采购计划的每种物料上。本发明只需要技术设计人员在图纸设计过程中把唯一码生成系统中自动产生的唯一码标识在每页图纸上,系统即可根据唯一码,自动读取每一页图纸的页码,并通过页码自动分配到后续系统对应的产生计划、采购计划、质量检验单等环节,其误差率极低,效率很高。
附图说明
44.图1是本发明的原理框图。
45.图2是图纸增加唯一码的示意图。
46.图3是文本识别提取识别的流程图。
47.图4是通过唯一码识别页码的流程图。
具体实施方式
48.下面将结合本发明实施例中的附图,对本发明实施例中的技术方案进行清楚、完整地描述。
49.在本发明的描述中,需要理解的是,术语“上”、“下”、“前”、“后”、“左”、“右”、“顶”、“底”、“内”、“外”等指示的方位或位置关系为基于附图所示的方位或位置关系,仅是为了便于描述本发明和简化描述,而不是指示或暗示所指的装置或元件必须具有特定的方位、以特定的方位构造和操作,因此不能理解为对本发明的限制。
50.本实施例的系统采用b/s结合架构,分为图纸存储管理模块、图纸识别及自动分配模块、图纸识别应用模块等主要功能。图纸识别系统前提必须是图纸符合特定格式的文件,并且能提取图纸中的“唯一码”,譬如pdf的文本格式,word格式,本实施例以pdf格式为例说明。
51.参见图1
‑
图2,一种图纸自动识别系统,包括:
52.图纸存储管理模块,用于存储、读取、下载图纸;图纸采用数据库表存储加文件专属存储方式进行管理;数据库表每行存储了文件的保存路径、文件大小、文件原名称、文件保存后的名称等一系列相关信息;并生成图纸文件的链接地址,可通过链接地址读取、下载图纸文件。
53.图纸识别及自动分配模块,在每页图纸上加入至少一个唯一码(详见图2),然后将图纸按页拆分为单张图片,再提取每张图片的文字,通过文字获取唯一码,再将唯一码与页码绑定,然后图纸按照页码顺序依次排序,后续可以通过唯一码访问相应页码的图纸;
54.按照整个研发、生产、质检、入库、销售等环节对不同图纸的需求,将每个环节需要的图纸按照页码的方式分配至各个环节,各个环节只能根据唯一码查看已经分配的图纸。本实施例中,同一页的唯一码可以有多个,有多个唯一码时,采用空格、回车、特殊字符等隔开。
55.图纸识别应用模块,利用唯一码在数据库表中进行检索,获取唯一码对应的页码,根据页码提取相应的图纸,然后可进行查看、下载。
56.参见图1
‑
图4,一种图纸自动识别方法,包括:
57.s100、图纸存储管理,图纸上传并存储在图纸数据库中,图纸的存储采用数据库表存储加文件专属存储方式进行管理;具体包括:
58.s110、创建文件列表时,先通过方法getrequestfileslist(type,sourcerequestid)获取数据库存储表usysfileupload;再把上传的文件列表信息会加入到数据表中,数据表每行存储了文件的保存路径、文件大小、文件原名称、文件保存后的名称等一系列相关信息;最后通过savefiles方法保存到数据库中;
59.s120、把上传列表文件根据数据库存储信息保存到文件服务器相应的目录中;
60.s130、网页显示文件列表,直接从数据库表中读取文件列表文件信息显示页面上,链接地址为文件服务器接口加文件参数信息;
61.s140、文件下载,通过接口dataservice.aspx传入文件信息,调取文件,从文件服务器中下载文件。
62.s200、图纸识别及自动分配,将图纸按页拆分为独立的图片,在每页图纸上附加至少一个唯一码,通过唯一码关联页码;根据每个环节需要的图纸对应的页码向每个环节分配可提取的图纸页码。具体包括:
63.s210、图纸拆分,把图纸按页拆分为多张单一图片,包括:
64.s211、引用pdfrender4net.dll文件;
65.s212、调用接口属性pagecount,先获取总页,再进行循环处理每一页;
66.s213、把pdf每页转成位图,采用方法:
67.public bitmap getpageimage(int pagenumber,float resolution)
68.其中需要参数:pagenumber
‑‑
传入页码,resolution
‑‑
pdf清晰度,返回:位图;
69.s214、生成图片,采用方法:
70.pageimage.save(pypath&"/"&页码&".jpg" >71.保存成jpg图片,图片的名称采用页码命名,以方便后期匹配使用。
72.s220、显示图片处理,采用两种方式显示:标清模式和高清模式,高清模式的清晰度高于标清模式的清晰度,具体包括如下步骤:
73.s221、获得拆分目录下的jpg图片文件名,进行从小到大页码排序;
74.s222、组合需要在页面上显示图片和附加内容;
75.s223、将组合内容转成字符串格式返回页面显示。
76.s230、pdf文本识别提取,参见图3,包括如下步骤:
77.s231、引用itextsharp.dll文件,创建pdfreader对象;
78.s232、采用numberofpages方法获取页码;
79.s233、循环页码,采用gettextfrompage方法获取每页文本,创建字典,把页码和文本加入到字典中。
80.s300、图纸识别应用,通过唯一码识别页码,参见图4,包括如下步骤:
81.s310、页面采用循环清单列表,向后台传入唯一码,找到页码写入相应行内;
82.s320、后台循环文本字典表,对比文本中唯一码,取出相应的页码。
83.识别方法:对文本进行循环遍历字符,根据需要识别的头标记和结束标记(空格或回车)进行过滤找到唯一码,取出页码。
84.调用方法:getnumberone(currenttext,dic,page,order),传入参数:pdf文本,字典,页码,唯一码。
85.本发明未详述之处,均为本领域技术人员的公知技术。
86.以上详细描述了本发明的较佳具体实施例。应当理解,本领域的普通技术人员无需创造性劳动就可以根据本发明的构思作出诸多修改和变化。因此,凡本技术领域中技术人员依本发明的构思在现有技术的基础上通过逻辑分析、推理或者有限的实验可以得到的技术方案,皆应在由权利要求书所确定的保护范围内。
再多了解一些
本文用于企业家、创业者技术爱好者查询,结果仅供参考。