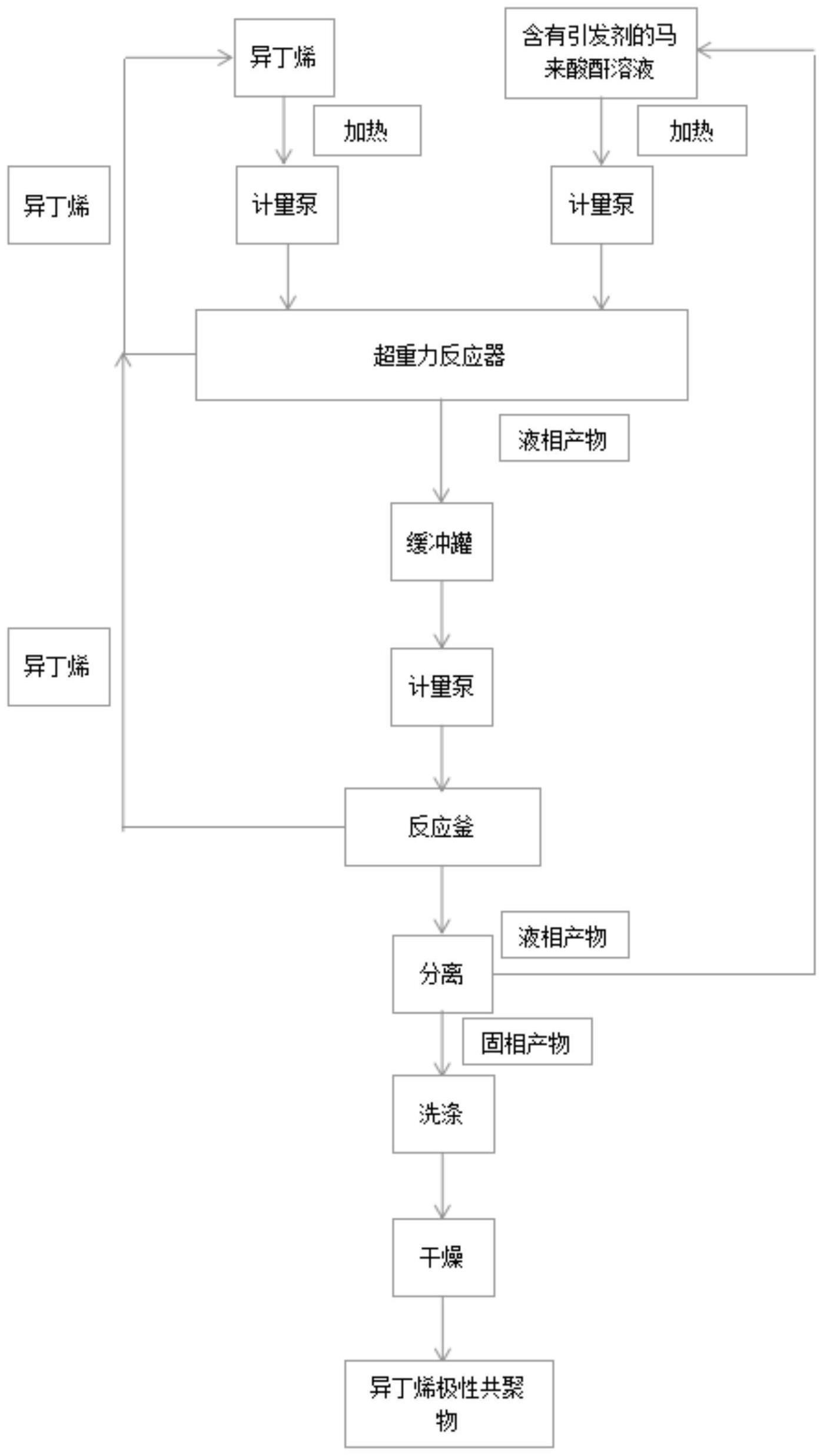
trc的肽底物文库,并通过samdi-ms进行分析。显示了肽修饰的热图(右下),其中在x-1
和x
1
位置处的氨基酸的平均修饰的降序分别与apq相同。生成了-ln(1-y)的新热图(左下),其中y是肽修饰。由于本发明人使用的肽浓度远低于km,可以使用热图中的平均-ln(1-y)(以粗体灰色正方形中的0.36,),用公式k
cat
/km=-ln(1-y)/c/t计算每个ssvl的平均k
cat
/km。相对于apq的平均k
cat
/km如(c)所示。所有ssvl显示降低的平均k
cat
/km。(d)将每个ssvl的每一行x-1
氨基酸和每一列x
1
氨基酸中-ln(1-y)的平均值与apq的平均值进行比较,apq选择具有与ssvl相同的整个文库的平均-ln(1-y)值,以使用等式2*|ave(x)-ave(apq)|/(ave(x) ave(apq))显示百分比差异。x-1
(左)和x
1
(右)位置的平均百分比差异分别使用所有行和列的百分比差的平均值表示。高于20%和30%的值分别以浅灰色条和箭头突出显示。所有实验均以n=1完成。
7.图2a-c。筛选对x-1
和x
1
受体肽位置具有独特特异性的apq突变体。(a)针对x-1-n-x
1-trc肽文库,与apq相比,来自t438、a469和h219的单个突变体的相对平均k
cat
/km。只有t438s显示相对活性的略有增加(1.1倍),而t438d/e/k/r/w和h219r显示较差活性,低于apq的0.001倍(未用整个文库筛选h219r,筛选了t438d/d/k/r/w,但修饰较差,见图22)。(b)与apq相比,每个突变体的x-1
(上)、x
1
(中)和整个文库(下)的平均百分比差异。整个库的平均百分比差异是x-1
和x
1
值的平均值。高于75%的值用箭头表示。(c)针对在apq的x-1
和x
1
位置处氨基酸以及三个所选残基(t438、a469和h219)的所有个体突变体的相对选择性的热图。相对特异性定义为每个氨基酸泳道的平均-ln(1-y)与所有19个x-1
或x
1
泳道的最大值之比。在x-1
和x
1
位置处的氨基酸以与修饰热图相同的顺序组织,并且在每个残基处的单个突变体的顺序与a和b相同。图25中还显示了带数值的热图。这些数据清楚地表明,对于x-1
位置的t438突变体、对于x
1
的h219f/w以及对于x-1
和x
1
两者的a469突变体表现出较大的特异性差异。所有实验均以n=1完成。
8.图3a-d。可用于通过工程化的ngt进行糖基化的肽序列的扩大集。(a-b)对于apq的肽文库x-1-n-x
1-t(a)或x-1-n-x
1-s(b)的修饰热图(左)和来自14个所选ngt(apq、h219f、h219w、t438s、t439e、a469g、a469i、h495d、h219f-t438s、h219f-h495d、h219w-t438s、h219wh495d和a469i-h495d)的最大修饰(右)。所有ngt均使用相同的条件进行测试:在let-cfps中产生0.545μm ngt,30℃进行3h。对于apq无效修饰的肽有显著改善。具体而言,与单独的apq相比,具有在x
1
位置处的asn、asp以及在x-1
位置处的lys、arg的肽通过14个ngt的组以高得多的效率进行修饰。用每个肽底物的数值和最佳ngt进行注释的热图如图32所示。所有实验均以n=1完成。(c-d)典型糖基化基序(在c中x-1-n-x
1-t,x
1
≠p)或x-1-n-x- 1-s(在d中x 1≠p)内的所有肽底物的比较,其通过apq在a-b中的修饰效率超过80%(左)和14个选择的ngt的最大值(右)。对于x-1-n-x
1-t文库,具有超过80%修饰的肽的百分比(以蓝色突出显示)从56%增加到80%,对于x-1-n-x
1-s文库,从33%增加到51%。
9.图4a-c。选择的ngt突变体能够对治疗蛋白进行更优异的修饰。(a)与apq相比,当被纯化的突变体糖基化时,具有经批准的治疗蛋白序列的肽被证实具有更大的修饰性。每个肽都呈现相对apq的数倍修饰。所有实验均以n=3次ivg反应完成。实验条件:1μm(tnys)、0.05μm(lnls)或0.2μm(ynst)纯化的ngt,30℃进行3h。在图中,apq和a469i是第一组柱:apq和t438s是第二组柱;apq和h495是第三组柱。(b)与apq相比,当被所选突变体糖基化时,纯化的经批准的治疗蛋白表现出增强的修饰。每个蛋白质糖基化位点都呈现相对apq的数倍
修饰。ivg后,对溶液进行透析,胰蛋白酶化,并用lc-qtof进行分析。apq没有显示出对ifnγ可检测修饰(标记为“nd”)。所有实验均以n=2或n=3个单独的ivg反应完成(如图所示)。实验条件:5μm纯化的ngt,5mm udp-glc,30℃,12h。在图中,a469i为第一个柱;apq是第二个柱;t438s是第三个柱。(c)对于h495d比apq,fc显示在cfps表达中的修饰增加。存在相对apq的数倍修饰。具有6xhis标签的fc由补充有纯化的ngt和udp-glc的let-cfps表达。cfps反应后,用磁珠纯化fc,透析,胰蛋白酶化,并用lc-qtof进行分析。在图中,apq是第一个柱,h495d是第二个柱。所有实验均以n=3个单独的cfps反应完成。实验条件:2μm纯化的ngt,5mm udp-glc,30℃let-cfps,6h。所有蛋白质修饰效率可见于图12。所有p值均来自双尾t检验,p《0.01(**)或p《0.001(***)。
10.图5a-b。在x
2
位置处针对扩大的特异性筛选ngt突变体。(a)所有r177和d215个体突变体在x
2
处的非s/t氨基酸的平均-ln(1-y)热图(t/s值如下所示)。apq优选的六个x-1-n-x
1-t肽序列在x
2
处被18个氨基酸(cys除外)取代,并针对所有单独的r177和d215突变体进行筛选。所有热图均显示来自n=1个实验的结果。所有反应均使用0.545μm在let-cfps中产生的ngt在30℃进行12h。x
2
氨基酸泳道按与apq相同的降序排列,如图18所示。图36中显示了用apq和所有个体突变体对x
2
的修饰热图。(b)基于a中数据的x
2
的相对氨基酸选择性,除以每个突变体的所有x
2
(s/t除外)的最大值。s/t的相对选择性也如下显示在相同的最大值上,并且可以高于100%。当在x
2
处存在asn时,如果对于w-n-i/v-n-rc的修饰比a-n-i/v-n-1rc更优选,则修饰可以来自在nrc处的第二asn,而不是n-x-n。
11.图6。提供列出实施例1中使用的菌株和质粒的表。
12.图7。提供显示实施例1中使用的apq的单突变体和双突变体的表。
13.图8。提供显示实施例1中使用的肽文库的平均相对电离因子(rif)的表。对于每个肽文库,分析六到十二个代表性肽以计算平均rif。根据公式i(p)/(i(s)*rif i(p))计算肽修饰,其中i(p)是质谱中糖基化的肽的强度,i(s)是质谱中糖基化的肽的强度。
14.图9。提供显示ssvl和具有肽文库的个体单个突变体的反应条件的表。指示浓度的在let-cfps中产生的ngt与50μm肽和2.5mm udp-glc在100mm hepes缓冲液(ph 8)和500mm nacl中反应。反应在30℃孵育指定的反应时间。
15.图10。提供显示了在相同反应条件下apq突变体以显著更高的效率糖基化的本工作中发现的肽序列的表。总共,与apq相比,来自722个成员x-1
nx
1s/trc肽文库的227个肽被选择的ngt突变体糖基化至少20%更有效。反应条件:0.545μm在let-cfps中产生的ngt,30℃进行3h。“y”表示所选突变体的修饰效率,“apq的y”表示apq的效率,并且“δy”表示与apq相比,用所示apq突变体处理时观察到的修饰增加。
16.图11。提供显示了本工作中发现的肽序列的表,所述肽与突变体表现出显著更高的近似k
cat
/km。从由apq修饰的每个x-1
nx
1
trc肽文库和具有不同反应条件的所选突变体中,发明人计算了每个肽的近似k
cat
/km(参见方法)。总的来说,在图3a中,发现通过apq以》75%的效率糖基化的33个肽,与apq相比,与在本研究中开发的apq突变体显示出两倍以上的活性。
17.图12。提供显示来自胰蛋白酶处理的糖基化蛋白治疗剂的肽的lc-qtof分析结果的表。未观察到(即未检测到)的肽种类用
“‑”
标记。在标记为“纯化”的部分中,将10μm纯化的蛋白底物与5μm纯化的酶在30℃反应12h。在“cfpse”部分中,在let-cfps中,在2μm apq、2
μm h495d或5μm h495 d(标记为h495d')浓度的纯化酶存在下,在30℃进行6小时产生fc。对于“cfps之后”部分下的fc样品,首先在let-cfps中在30℃进行20小时,然后补充2μm纯化的apq并在30℃孵育6小时产生fc。
18.图13。提供显示用于pcr诱变的引物的表。重叠的序列用下划线指示,突变位点用粗体突出显示,并用于计算tm1。延伸的序列为斜体,并用于计算tm2(见方法)。
19.图14a-e。let-cfps反应以相似的水平表达apq、ssvl和个体突变体。(a)通过pcr扩增apq和26个ssvl线性表达模板的dna凝胶。该线性表达模板包含编码序列以及启动子和终止子。在所有泳道中观察到约2.2kb的条带,表明apq和ssvl的扩增。pcr产物直接用于ngt的let-cfps。(b)可溶性cfps级分的sds-page。apq和所有26个ssvl在大肠杆菌bl21 star(de3)裂解物中以相似的水平通过let-cfps表达。(c)apq和19个个体t438突变体的可溶性cfps级分的sds-page。ngt突变体以相似的水平表达。使用sfgfp作为对照。(d)具有类似结果的n=2个实验的代表性放射自显影图证实,cfps反应主要产生相等全长的ngt,而在可溶性片段中没有大的截短。放射自显影是通过将cfps中产生的ngt的sds-page凝胶暴露
14
c亮氨酸48小时而产生的。b-d中的所有sds-page凝胶均使用4-12%的bis-tris凝胶,在150v下使用mops缓冲液和seeblue plus2预染色阶梯进行,然后用instantblue coomassie染料(expedeon)进行染色。(e)使用
14
c亮氨酸掺入测定cfps反应中ngt的总产率和可溶性产率(n=3个实验)。观察到所有ngt的总表达水平以及可溶性级分的表达水平相等。所有cfps反应在22℃孵育20小时。在4℃以12,000xg离心15分钟后,分离a-e中的可溶性级分。本发明人对let-cfps中表达的所有ngt(包括apq、ssvl以及个体单个和双ngt突变体)使用平均浓度10.9μm。
20.图15。跨x-1-n-x
1-trc肽文库中筛选的ssvl的修饰效率热图。x-1
nx
1
trc和x-1
nx
1
src文库热图中的所有x-1
和x
1
氨基酸泳道按照与在通过0.0218μm apq修饰的x-1
nx
1
trc文库热图中观察到的从左到右和从上到下的平均修饰的相同降序排列(图16)。所有实验均以n=1进行。反应条件如图9所示。
21.图16a-d。apq参考热图和肽选择性百分比差异的计算。(a)在cfps中合成的六种浓度的apq与肽文库x-1-n-x
1-trc在30℃反应1h,以生成具有各种平均-ln(1-y)值的参考热图,用于计算突变体和apq之间的百分比差异(见下文和方法)。反应后,分析葡萄糖修饰并生成修饰热图。所有x-1
和x
1
氨基酸泳道的安置与在用0.0218μm apq修饰的x-1
nx
1
trc文库热图中观察到的从左到右和从上到下的平均修饰的降序相同。本工作中,所有x-1
nx
1
trc和x-1
nx
1
src热图均采用该相同的顺序。(b)相应的apq参考热图的值为-ln(1-y),其中y是修饰产量。(c)a469x和apq之间百分比差异的示例计算。在两个相近浓度的热图之间进行了线性假设。对于通过a469x修饰的x-1
nx
1
trc文库的平均-ln(1-y)值为0.36,介于0.0142μm apq(0.23)和0.0218μm apq(0.39)的参考apq热图的值之间。然后,发明人使用这两个参考apq热图的线性插值来生成平均-ln(1-y)为0.36的apq的理论热图。然后,发明人计算了该理论apq热图和a469x热图中每个x-1
和x
1
泳道的平均-ln(1-y)值之间的百分比差异。所有x-1
泳道的平均百分比差异为0.29,所有x
1
泳道的平均比率差异为0.50。(d)基于参考热图,平均k
cat
/km对apq平均ln(1-y)的依赖性。当计算与apq相比的每个突变体(或ssvl)的相对k
cat
/km时,发明人还使用线性插值调整apq的k
cat
/km以匹配突变体热图的平均-ln(1-y)。所有实验以n=1进行。
22.图17。对于x-1
(顶部)和x
1
(底部),26个ssvl和apq中任何一个的平均百分比差异。基于图15所示的x-1
nx
1
trc热图,发明人根据每个ssvl和apq之间的平均百分比差异计算了26个ssvl中的任意两个与apq之间平均百分比差异(参见方法)。高于20%和40%的值分别以蓝色和红色突出显示。ssvl按照与所有其他的平均差异降序排列。与所有其他ssvl相比,t438x和a469x显示出特异性的最大变化。基于它们在晶体结构中的位置,发明人认为t438和a469都与受体肽的x-1
位置相互作用。发明人随后得出结论,r177、m218和h219可能与受体肽的x
1
位置相互作用。虽然h214也影响特异性,但与其他假定的结合残基相比,其在晶体结构中的位置不支持与肽的x
1
位置的直接相互作用。
23.图18。ssvl筛选以确定对于x
2
特异性的重要残基。基于晶体结构以及对于x-1
和x
1
的可能结合残基,被鉴定为与受体肽的x
2
位置相互作用的候选ssvl跨(x-1
nx
1
)x
2
rc文库进行筛选。所有x
2
氨基酸泳道以与apq相同的降序排列。已知与受体肽的x-1
位置相互作用的残基的ssvl,t438x和a469x也被筛选为阴性对照。r177x和d215x对除典型s/t外在x
2
处的其他氨基酸表现出偏好。基于数据、晶体结构和在x
2
处s/t对修饰的重要性,发明人假设d215在x
2
处与s/t形成氢键。虽然发明人不确定r177如何与x
2
位置相互作用,但这表明r177在确定酶特异性方面起着重要作用。所有实验均以n=1进行。反应条件如图9所示。
24.图19。ssvl筛选以确定对于x-2
特异性的重要残基。基于晶体结构以及对于x-1
和x
1
的可能结合残基被鉴定为与受体肽的x-2
位置相互作用的候选ssvl跨x-2
(x-1
nx
1
)trc文库进行筛选。所有x-2
氨基酸泳道以与apq相同的降序排列。h277x显示了在x-2
处用ile和gln对肽的增加修饰,而pro减少修饰。当在x-1
处存在trp残基时,h277x也显示出减少的修饰,这与x-1
nx
1
trc筛选中对于h277x的结果一致(图15)。所有实验以n=1进行。反应条件如图9所示。
25.图20。ssvl筛选以确定对于x
3
特异性的重要残基。基于晶体结构以及对于x
1
和x
2
的可能结合残基被鉴定为与受体肽的x
3
位置相互作用的候选ssvl跨(x-1
nx
1
)tx
3
rc文库进行筛选。所有x
3
氨基酸泳道以与apq相同的降序排列。h214x显示在x
3
处用pro、asp和glu对肽的增加修饰。r177x还显示了在x
3
处用arg、lys和his对肽的增加修饰,这可能是这些氨基酸与残基r177之间的静电排斥。所有实验均以n=1进行。反应条件如图9所示。
26.图21。基于筛选结果的假设肽结合残基。基于apngt晶体结构和图15和17-20中的筛选结果,发明人提出了酶残基和受体肽的位置之间的以下相互作用:h277结合x-2
;t438和a469结合x-1
;r177、m218和h219结合x
1
;r177和d215结合x
2
;h214结合x
3
。还显示了影响在x-1
处对于k/r的选择性的另一个残基h495(数据如图29a-c所示)。虽然需要进一步的结构研究来确认这些相互作用,但这为了解哪些残基将对ngt的特异性产生最严重的影响提供了模型。这是基于apngt2(pdb#3q3h)的结构,因此图中的残基469是gln。基于晶体结构以及针对x
1
和x
2
的可能结合残基鉴定为与受体肽的x
3
位置相互作用的候选ssvl跨(x-1
nx
1
)tx
3
rc文库进行筛选。所有x
3
氨基酸泳道以与apq相同的降序排列。h214x显示在x
3
处用pro、asp和glu对肽的增加修饰。r177x还显示在x
3
处用arg、lys和his对肽的增加修饰,这可能是这些氨基酸与残基r177之间的静电排斥。所有实验均以n=1进行。反应条件如图9所示。
27.图22。针对跨x-1-n-x
1-trc肽文库筛选的个体t438突变体的修饰效率热图。所有实验以n=1进行。反应条件如图9所示。
28.图23。针对跨x-1-n-x
1-trc肽库筛选的个体a469突变体的修饰效率热图。所有实
验以n=1进行。反应条件如图9所示。
29.图24。针对跨x-1-n-x
1-trc肽文库筛选的个体h219突变体的修饰效率热图。所有实验以n=1进行。反应条件如图9所示。
30.图25。apq和个体t438、a469和h219突变体对在x-1
和x
1
位置处的氨基酸的相对选择性用数值进行注释。图2c显示了无数值的热图。
31.图26。跨整个x-1
nx
1
trc文库的个体t438(顶部)、a469(中部)和h219(底部)突变体以及apq的平均百分比差异热图。发明人计算了跨整个x-1
nx
1
trc文库对于t438(顶部)、a469(中部)和h219(底部)突变体以及apq的任意两个ngt之间的平均百分比差异(参见方法)。突变体以对所有其他突变体的平均差异的降序排列。大于0.40和0.80的值分别以蓝色和红色突出显示。t438h/l/q/p/f/y/n/g、a469e/p/r/y/n/h/f/d/g/m/l/k和h219w/f具有比apq更高的平均差异。
32.图27。跨x-1
nx
1
trc肽文库的apq和所选个体突变体的修饰效率热图。所有实验均以n=1进行。反应条件:0.545μm cfps ngt,30℃进行3h。
33.图28。跨x-1
nx
1
src肽文库的apq和所选个体突变体的修饰效率热图。所有实验以n=1进行。反应条件:0.545μm cfps ngt,30℃进行3h。
34.图29a-c。鉴定对在x-1
处具有lys或arg的肽具有增加的特异性的突变体。(a)显示相对高活性并具有预测在x-1
位置附近的突变残基的ssvl用k/r-n-x
1-trc针对增加的修饰进行筛选。h495x和t439x对某些肽显示出比apq更多的修饰,以红色突出显示。(b)对于具有肽k/r-n-y-trc的t439x ssvl的糖基化增加主要来自t439d/e突变体。用肽筛选所有19个单独的h495突变体。h495d显著改善了大多数肽的修饰。(c)用k/r-n-x
1-src筛选b中显示增加的修饰的突变体。所有实验以n=1进行。所有反应条件:0.545μm cfps ngt,30℃进行3h。
35.图30。对于代表性突变体t439e、h495d和h495q的整个x-1
nx
1
trc文库的修饰效率热图。t439e和h495d显示在x-1
处具有k/r的肽之间增加的选择性,而h495q没有。所有实验以n=1进行。反应条件如图9所示。
36.图31a-b。双突变体的修饰效率热图。(a)用k/r-n-x
1-s/t-rc筛选了具有h495d的4个双突变体。(b)用x-1-n-n/d-s/t-rc筛选了具有h219f/w的四个双突变体。所有实验以n=1进行。所有反应条件:0.545μmcfps ngt,30℃进行3h。
37.图32。每个典型糖基化序列的最佳ngt突变体的图谱。该肽图显示了通过apq和本工作中发现的13个选定的单或双突变体(中心列出)跨典型糖基化序列(x-1
nx
1
src和x-1
nx
1
src)实现的最大修饰效率。这与图3a-b中发现的数据相同,并源自图27和29-31。大于0.05的修饰以灰色突出显示,并被视为可以修饰的序列(典型序列的93%)。肽修饰值由产生最大修饰的ngt进行颜色编码。
38.图33a-c。经批准的治疗蛋白内靶向胰蛋白酶化肽的lc-qtof ms/ms。通过ms/ms进行的肽测序证实了胰蛋白酶化肽以及具有几乎相同ms/ms光谱的糖肽的身份。这些胰蛋白酶化肽的ms1的提取离子色谱图用于图4中糖基化的定量。(a)ifnγ靶肽:ltnysvtdlnvqr,在ms1中 2带电m/z为761.90;glc肽,ms1中 2带电m/z为842.92。(b)gm-csf靶肽:llnlsr,在ms1中 1带电m/z为715.45;glc肽,在ms1中 1带电m/z为877.50。(c)fc靶肽:eeqynstyr,在ms1中 2带电m/z为595.26;glc肽,在ms1中 2带电m/z为676.29。使用50ev的碰撞能量。
39.图34a-b。具有预先存在的ngt或cfps后添加的ngt的let-cfps中的fc表达。(a)在
let-cfps中fc的20h表达并离心以分离可溶性级分后,添加2μm纯化的apq和5mm udp-glc,并在30℃孵育反应6h。与在cfps反应开始时添加纯化的apq时的46%相比,实现了15%的修饰(如图4c和图12所示)。(b)fc的let-cfps表达期间(在30℃持续6h)存在5μm纯化的h495d和5mm udp glc,fc以80%进行修饰。所有实验以n=2个单独的ivg反应完成。
40.图35。(x-1
nx
1
)x
2
rc肽文库中单独r177和d215突变体的修饰效率热图。x
1
氨基酸以与图18相同的降序排列。所有实验以n=1进行。反应条件:0.545μm cfps ngt,30℃进行12h。
41.图36。跨x-1-n-x
1-trc肽文库库针对单独r177突变体的修饰效率热图。r177个体突变体在x-1
和x
1
选择性方面显示差异。该数据用于为每个突变体选择具有独特x
2
偏好的x-1
和x
1
组合。所有实验以n=1进行。反应条件如图9所示。
42.图37。apq和用udp-glcn和六种代表性肽筛选的四种高活性突变体的百分比强度热图。t438s和a469i在某些肽上显示出比apq更高的glcn修饰。所有实验以n=1进行。反应条件:1.09μm在let-cfps中产生的ngt,2.5mm udp glcn,30℃进行12h。
43.图38。提供编码由let-cfps表达的ngt、由大肠杆菌表达和纯化的ngt以及在let-cpfs中表达的底物蛋白的dna序列。关键点:翻译区(全部大写);突变位点(带下划线的大写字母);非翻译区域(小写);t7启动子(小写下划线);t7终止子(斜体,小写)。
44.图39。提供以下生物的ngt氨基酸序列:肠道沙门氏菌(salmonella enterica);金氏金格杆菌(kingella kingae);嗜沫聚集杆菌(aggregatibacter aphrophilus);伯克霍尔德氏菌属物种(burkholderia sp);海藻百伯史坦菌(bibersteinia trehalosi);大肠杆菌(escherichia coli);杜克雷嗜血杆菌(haemophilus ducreyi);溶血性曼氏杆菌(mannheimia haemolytica);流感嗜血杆菌(haemophilus influenzae);小肠结肠炎耶尔森氏菌(yersinia enterocolitia);鼠疫耶尔森氏菌(yersinia pestis);和胸膜肺炎放线杆菌(actinobacillius pleuropneumoniae)。
45.图40。提供以下生物的ngt氨基酸序列的clustal omega比对:金氏金格杆菌;流感嗜血杆菌;嗜沫聚集杆菌;溶血性曼式杆菌;海藻百伯史坦菌;杜克雷嗜血杆菌;胸膜肺炎放线杆菌;伯克霍尔德氏菌属物种;小肠结肠炎耶尔森氏菌;鼠疫耶尔森氏菌;肠道沙门氏菌;和大肠杆菌。
46.图41。提供显示蛋白质序列同一性百分比的表。表左上部分所示的金氏金格杆菌、流感嗜血杆菌、嗜沫聚集杆菌、溶血性曼式杆菌、海藻百伯史坦菌、杜克雷嗜血杆菌和胸膜肺炎放线杆菌的氨基酸同一性百分比为62.5%至76.25%。
47.图42a-b。提供由phyre2蛋白质折叠识别引擎(http://www.sbg.bio.ic.ac.uk/~phyre2/html/page.cgiid?id=index)生成的结构比对表明大肠杆菌ngt(ecngt)、嗜沫聚集杆菌ngt(aangt)、胸膜肺炎放线杆菌ngt(apngt)(发现它们具有不同的序列)实际上具有相似的结构,因此可以以与apngt相似的方式进行工程化。phyre2使用所有目前已知的晶体结构来基于它们的序列预测未结晶蛋白质的最可能折叠。a)显示了ecngt(红色)和apngt(蓝色)的比对。活性位点中的udp配体显示为绿色球体。b)显示了aangt(红色)和apngt(蓝色)的比对。活性位点中的udp配体显示为绿色球体。
48.图43。提供以下生物的氨基酸序列的clustal omega比对:金氏金格杆菌、流感嗜血杆菌、嗜沫聚集杆菌、溶血性曼式杆菌、海藻百伯史坦菌、杜克雷嗜血杆菌和胸膜肺炎放
线杆菌。
49.图44a-b。提供了由phyre2蛋白质折叠识别引擎生成的结构比对,表明金氏金格杆菌ngt(kkngt)、溶血性曼氏杆菌(mhngt)和apngt实际上具有相似的结构,并因此可以以与apngt相似的方式进行工程化。在图43中提供的ngt序列中,kkngt与apngt最为不同;mhngt为中间发散型。a)显示了kkngt(红色)和apngt(青色)的比对。活性位点中的udp配体显示为绿色球体。b)显示了mhngt(红色)和apngt(青色)的比对。活性位点中的udp配体显示为绿色球体。
50.图45。提供以下生物的ngt氨基酸序列的clustal omega比对:溶血性曼氏杆菌(mh)、杜克雷嗜血杆菌(hd)和胸膜肺炎放线杆菌(ap)。粗体的氨基酸对应于apngt氨基酸f39、r177、h214、d215、m218、h219、y222、h272、h277、s278、i279、r281、m349、g370、h371、t438、t439、m440、k441、q469、h495、p497、y498、f517、n521、d525。
51.图46a-b。提供了由phyre2蛋白质折叠识别引擎生成的结构比对,表明杜克雷嗜血杆菌ngt(hdngt)、溶血性曼氏杆菌ngt(mhngt)和apngt具有相似的结构,并因此可以以与apngt相似的方式进行工程化。a)显示了hdngt(红色)与apngt(青色)的比对。活性位点中的udp配体用绿色球体表示。b)显示了mnngt(红色)与apngt(青色)的比对。活性位点中的udp配体显示为绿色球体。发明详述
52.定义和术语
53.所公开的用于糖蛋白和重组糖蛋白蛋白质合成的组分、系统和方法可以使用如下定义和术语进一步描述。本文中使用的定义和术语仅用于描述特定实施方案的目的,并不旨在进行限制。
54.如在本说明书和权利要求中使用的,单数形式“一个”、“一种”和“该”包括复数形式,除非上下文另有明确规定。例如,术语“一个/一种寡糖”或“一个/一种n-糖基转移酶”应分别解释为是指“一个或多个/一种或多种寡糖”和“一个或多个/一种或多种n-糖基转移酶”,除非上下文另有明确规定。如本文所用,术语“多个/多种”是指“两个或更多个/两种或更多种”。
55.如本文所用,“约”、“大约”、“基本上”和“显著”将被本领域普通技术人员理解并且将在它们使用的上下文中在一定程度上变化。如果考虑到使用它的上下文,该术语的使用对于本领域的普通技术人员来说是不清楚的,则“约”和“大约”将意味着特定术语的多至正负10%,并且“基本上”和“显著”将意味着超过特定术语的正负10%。
56.如本文所用,术语“包括”和“包括的”与术语“包含”和“包含的”具有相同的含义。术语“包括”和“包含”应被解释为“开放”过渡性术语,其允许进一步包括在权利要求中记载的那些组分之外的附加组分。术语“组成”和“由
……
组成”应被解释为“封闭式”过渡性术语,其不允许包括除权利要求中记载的组分之外的附加组分。术语“基本上由
……
组成”应被解释为部分封闭,其仅允许包含不会根本上改变要求保护的主题的性质的附加组分。
57.短语“诸如”应被解释为“例如,包括”。此外,任何和所有示例性语言的使用,包括但不限于“诸如”,仅意在更好地阐明本发明而不对本发明的范围构成限制,除非另有声明。
58.此外,在其中使用类似于“a、b和c等中的至少一个”的常规表述的那些情况下,一般而言,这样的造句意在具有本领域普通技术人员将理解该常规表述的意义(例如,“具有
a、b和c中的至少一个的系统”将包括但不限于具有单独的a、单独的b、单独的c、a和b一起、a和c一起、b和c一起和/或a、b和c一起的系统)。本领域技术人员将进一步理解,呈现两个或更多个备选项目的实际上任何分离词和/或短语(无论是在说明书还是附图中)都应该被理解为考虑包括该项目中的一个、该项目中的任一个或该项目中的两者的可能性。例如,短语“a或b”将被理解为包括“a”或“b”或“a和b”的可能性。
59.诸如“多至”、“至少”、“大于”、“小于”等的所有语言包括所列举的数字并且指的是随后可以被分解为多个范围和子范围的范围。范围包括每个个体成员。因此,例如,具有1-3个成员的组是指具有1、2或3个成员的组。类似地,具有6个成员的组是指具有1、2、3、4或6个成员的组,以此类推。
60.情态动词“可以”是指在几个所描述的实施方案或包含在其中的特征中的一个或多个选项或选择的优选使用或选择。当没有公开关于特定实施方案或其中包含的特征的选项或选择时,情态动词“可以”是指关于如何制作或使用所描述的实施方案或包含在其中的特征的方面的肯定行为,或使用关于所描述的实施方案或包含在其中的特征的特定技能的最终决定。在后一种情况下,情态动词“可以”与助动词“能够”具有相同的含义和内涵。
61.如本文所用,术语“结合”、“结合的”、“相互作用”、“相互作用的”、“占据”和“占据的”是指共价相互作用、非共价相互作用和立体相互作用。共价相互作用是两个原子或自由基之间的化学键联,通过共享一对电子(单键)、两对电子(双键)或三对电子(三键)形成。共价相互作用在本领域中也称为电子对相互作用或电子对键。非共价相互作用包括但不限于范德华相互作用、氢键、弱化学键(通过短程非共价力)、疏水相互作用、离子键等。非共价相互作用的综述可以参见alberts等人,molecular biology of the cell,第3版,garland publishing,1994。立体相互作用通常被理解为包括化合物的结构使得其能够凭借其三维结构占据位点的那些,而不是化合物和位点之间的任何吸引力。
62.多核苷酸和合成方法
63.如本文所用,术语“核酸”和“寡核苷酸”是指聚脱氧核糖核苷酸(含有2-脱氧-d-核糖)、聚核糖核苷酸(含有d-核糖),以及作为嘌呤或嘧啶碱基的n糖苷的任何其他类型的多核苷酸。术语“核酸”、“寡核苷酸”和“多核苷酸”之间在长度上没有有意的区别,并且这些术语将互换使用。这些术语仅指分子的一级结构。因此,这些术语包括双链和单链dna,以及双链和单链rna。为了在本方法中使用,寡核苷酸还可以包括其中碱基、糖或磷酸主链被修饰的核苷酸类似物以及非嘌呤或非嘧啶核苷酸类似物。
64.寡核苷酸可以通过任何合适的方法制备,包括通过诸如narang等人,1979,meth.enzymol.68:90-99的磷酸三酯方法;brown等人,1979,meth.enzymol.68:109-151的磷酸二酯方法;beaucage等人,1981,tetrahedron letters22:1859-1862的二乙基亚磷酰胺方法;和美国专利号4,458,066的固体支持方法(每个都通过引用并入本文)的方法直接化学合成。goodchild,1990,bioconjugate chemistry 1(3):165-187中提供了寡核苷酸和修饰的核苷酸的缀合物的合成方法的综述,该文献通过引用并入本文。
65.术语“扩增反应”是指任何化学反应,包括酶促反应,其导致模板核酸序列的增加的拷贝或导致模板核酸的转录。扩增反应包括逆转录、聚合酶链式反应(pcr),包括实时pcr(参见美国专利号4,683,195和4,683,202;pcr protocols:a guide to methods and applications(innis等人编,1990)),和连接酶链式反应(lcr)(参见barany等人,美国专利
号5,494,810)。示例性的“扩增反应条件”或“扩增条件”通常包括两步或三步循环。两步循环具有高温变性步骤,接着是杂交/延伸(或连接)步骤。三步循环包括变性步骤,接着是杂交步骤,接着是单独的延伸步骤。
66.如本文所用,术语“靶标”、“靶序列”、“靶区域”和“靶核酸”是同义词,并且是指待扩增、测序或检测的核酸的区域或序列。
67.如本文所用,术语“杂交”是指由于互补碱基配对由两条单链核酸形成双链体结构。杂交可发生在完全互补的核酸链之间或包含少量错配区域的“基本互补”核酸链之间。其中完全互补的核酸链的杂交是强烈优先的条件称为“严格杂交条件”或“序列特异性杂交条件”。在不太严格的杂交条件下可以获得基本互补序列的稳定双链体;可以通过适当调整杂交条件来控制容许的错配程度。核酸技术领域的技术人员可以根据经验确定双链体稳定性,其中考虑许多变量,包括例如寡核苷酸的长度和碱基对组成、离子强度和错配碱基对的发生率,遵循本领域提供的指导(参见,例如,sambrook等人,1989,molecular cloning
–
alaboratory manual,cold spring harbor laboratory,cold spring harbor,new york;wetmur,1991,critical review in biochem.and mol.biol.26(3/4):227-259;和owczarzy等人,2008,biochemistry,47:5336-5353,其通过引用并入本文)。
68.如本文所用,术语“引物”是指在合适的条件下能够充当dna合成起始点的寡核苷酸。此类条件包括其中在四种不同的三磷酸核苷和用于延伸的试剂(例如,dna聚合酶或逆转录酶)的存在下在适当的缓冲液中并且在合适的温度下诱导与核酸链互补的引物延伸产物的合成的那些条件。
69.引物优选地是单链dna。引物的合适长度取决于引物的预期用途,但通常范围为约6至约225个核苷酸,包括中间范围,例如15至35个核苷酸、18至75个核苷酸和25至150个核苷酸。短引物分子通常需要较低的温度以与模板形成足够稳定的杂交复合物。引物不需要反映模板核酸的确切序列,但必须充分互补以与模板杂交。用于扩增给定靶序列的合适引物的设计是本领域众所周知的并且描述于本文引用的文献中。
70.引物可以包括允许检测或固定化引物但不改变引物的基本特性(即作为dna合成起始点)的附加特征。例如,引物可以在5’端包含额外的核酸序列,该序列不与靶核酸杂交,但其有助于扩增产物的克隆或检测,或其使得能够转录rna(例如,通过包含启动子)或翻译蛋白质(例如,通过包含5
’‑
utr,例如内部核糖体进入位点(ires)或3
’‑
utr元件,例如聚(a)n序列,其中n在约20至约200的范围内)。与模板充分互补以杂交的引物区域在本文中称为杂交区域。
71.如本文所用,如果在足够严格的条件下用于扩增反应中时,引物主要与靶核酸杂交,则引物对于靶序列是“特异性的”。通常,如果引物-靶标双链体稳定性大于引物与样品中发现的任何其他序列之间形成的双链体的稳定性,则引物对靶序列具有特异性。本领域技术人员将认识到各种因素(例如盐条件以及引物的碱基组成和错配的位置)将影响引物的特异性,并且引物特异性的常规实验确认将在很多情况下是需要的。可以选择杂交条件,在该条件下引物可以仅与靶序列形成稳定的双链体。因此,在适当严格的扩增条件下使用靶特异性引物能够选择性扩增含有靶引物结合位点的那些靶序列。
72.如本文所用,“聚合酶”是指催化核苷酸的聚合的酶。“dna聚合酶”催化脱氧核糖核苷酸的聚合。已知的dna聚合酶包括例如激烈火球菌(pyrococcus furiosus)(pfu)dna聚合
酶、大肠杆菌dna聚合酶i、t7 dna聚合酶和水生栖热菌(thermus aquaticus)(taq)dna聚合酶等。“rna聚合酶”催化核糖核苷酸的聚合。dna聚合酶的上述实例也称为dna依赖性dna聚合酶。rna依赖性dna聚合酶也属于dna聚合酶的范围。逆转录酶,包括由逆转录病毒编码的病毒聚合酶,是rna依赖性dna聚合酶的一个实例。rna聚合酶(“rnap”)的已知实例包括例如t3 rna聚合酶、t7 rna聚合酶、sp6 rna聚合酶和大肠杆菌rna聚合酶等。rna聚合酶的上述实例也称为dna依赖性rna聚合酶。任何上述酶的聚合酶活性可以通过本领域公知的方法测定。
73.术语“启动子”是指顺式作用dna序列,其指导rna聚合酶和其他反式作用转录因子从包含顺式作用dna序列的dna模板起始rna转录。
74.如本文所用,术语“序列确定的生物聚合物”是指具有特定一级序列的生物聚合物。在基因编码具有特定一级序列的生物聚合物的情况下,序列确定的生物聚合物可以等同于基因编码的确定的生物聚合物。
75.本文考虑的多核苷酸序列可以存在于表达载体中。例如,载体可以包含:(a)编码蛋白质的orf的多核苷酸;(b)表达rna的多核苷酸,该rna指导靶dna序列的rna介导的结合、切口和/或裂解;以及(a)和(b)。载体中存在的多核苷酸可以与原核或真核启动子可操作地连接。“可操作地连接”是指其中将第一核酸序列放置于与第二核酸序列的功能关系中的情况。例如,如果启动子影响编码序列的转录或表达,则启动子与编码序列可操作地连接。可操作地连接的dna序列可以非常接近或连续并且在需要连接两个蛋白质编码区时处在同一阅读框中。本文考虑的载体可包含与编码蛋白质的多核苷酸可操作地连接的异源启动子(例如,真核或原核启动子)。“异源启动子”是指不是所表达的蛋白质或rna的天然或内源启动子的启动子。本文公开的载体可包括质粒载体。
76.如本文所用,“表达”是指多核苷酸从dna模板转录的过程(例如转录成mrna或其他rna转录物)和/或转录的mrna随后翻译成肽、多肽或蛋白质的过程。转录物和编码的多肽可以统称为“基因产物”。如果多核苷酸源自基因组dna,则表达可包括在真核细胞中mrna的剪接。
77.如本文所用,“表达模板”是指作为底物用于转录至少一种可以翻译成序列确定的生物聚合物(例如,多肽或蛋白质)的rna的核酸。表达模板包括由dna或rna组成的核酸。将核酸用于表达模板的dna的合适来源包括基因组dna、cdna和可以转化为cdna的rna。基因组dna、cdna和rna可以来自任何生物来源,例如组织样品、活组织检查、拭子、痰、血液样品、粪便样品、尿液样品、刮屑等。基因组dna、cdna和rna可以来自宿主细胞或病毒来源以及来自任何物种,包括现存和灭绝的生物体。如本文所用,“表达模板”和“转录模板”具有相同含义并可互换使用。
78.在某些示例性实施方案中,提供了包含编码本文所述的一种或多种rrna或报告多肽和/或蛋白质的核酸的载体,例如表达载体。如本文所用,术语“载体”是指能够运输与其连接的另一种核酸的核酸分子。一种类型的载体是“质粒”,它指的是环状双链dna环,其中可以连接额外的dna区段。此类载体在本文中称为“表达载体”。通常,可用于重组dna技术的表达载体通常是质粒形式。在本说明书中,“质粒”和“载体”可以互换使用。然而,所公开的方法和组合物旨在包括此类其他形式的表达载体,例如起到等效功能的病毒载体(例如复制缺陷型逆转录病毒、腺病毒和腺相关病毒)。
79.在某些示例性实施方案中,重组表达载体包含适合在本文所述的一种或多种方法中表达核酸序列的形式的核酸序列(例如编码本文所述的一种或多种rrna或报告多肽和/或蛋白质的核酸序列),这意味着重组表达载体包括与待表达的核酸序列可操作地连接的一种或多种调节性序列。在重组表达载体内,“可操作地连接”旨在意指编码一种或多种rrna或报告多肽和/或本文所述的蛋白质的核苷酸序列以允许表达核苷酸序列(例如,在体外转录和/或翻译系统中)的方式连接至一种或多种调节序列。术语“调节序列”旨在包括启动子、增强子和其他表达控制元件(例如,聚腺苷酸化信号)。例如,在goeddel;gene expression technology:methods in enzymology 185,academic press,sandiego,calif.(1990)中描述了这样的调节序列。
80.寡核苷酸和多核苷酸可以任选地包括一种或多种非标准核苷酸、核苷酸类似物和/或修饰的核苷酸。修饰的核苷酸的实例包括但不限于二氨基嘌呤、s2t、5-氟尿嘧啶、5-溴尿嘧啶、5-氯尿嘧啶、5-碘尿嘧啶、次黄嘌呤、黄嘌呤、4-乙酰胞嘧啶、5-(羧基羟甲基)尿嘧啶、5-羧甲基氨基甲基-2-硫尿苷、5-羧甲基氨基甲基尿嘧啶、二氢尿嘧啶、β-d-半乳糖基q核苷(galactosylqueosine)、肌苷、n6-异戊烯基腺嘌呤、1-甲基鸟嘌呤、1-甲基肌苷、2,2-二甲基鸟嘌呤、2-甲基腺嘌呤、2-甲基鸟嘌呤、3-甲基胞嘧啶、5-甲基胞嘧啶、n6-腺嘌呤、7-甲基鸟嘌呤、5-甲基氨基甲基尿嘧啶、5-甲氧基氨基甲基-2-硫尿嘧啶、β-d-甘露糖基q核苷(mannosylqueosine)、5
’‑
甲氧基羧甲基尿嘧啶、5-甲氧基尿嘧啶、2-甲硫基-d46-异戊烯基腺嘌呤、尿嘧啶-5-羟乙酸(v)、wybutoxosine、假尿嘧啶、q核苷(queosine)、2-巯基胞嘧啶、5-甲基-2-硫尿嘧啶、2-硫尿嘧啶、4-硫尿嘧啶、5-甲基尿嘧啶、尿嘧啶-5-羟乙酸甲酯、尿嘧啶-5-羟乙酸(v)、5-甲基-2-硫尿嘧啶、3-(3-氨基-3-n-2-羧丙基)尿嘧啶、(acp3)w、2,6-二氨基嘌呤等。核酸分子也可以在碱基部分(例如,在通常可用于与互补核苷酸形成氢键的一个或多个原子处和/或在通常不能与互补核苷酸形成氢键的一个或多个原子处)、糖部分或磷酸主链处进行修饰。
81.术语“多核苷酸”、“多核苷酸序列”、“核酸”和“核酸序列”是指核苷酸、寡核苷酸、多核苷酸(这些术语可以互换使用)或其任何片段。这些短语也指基因组、天然或合成来源的dna或rna(其可以是单链或双链,并且可以代表有义链或反义链)。
82.关于多核苷酸序列,术语“同一性百分比”和“%同一性”是指使用标准化算法比对的至少两个多核苷酸序列之间的残基匹配的百分比。这样的算法可以以标准化和可重复的方式在被比较的序列中插入缺口以优化两个序列之间的比对,并因此实现两个序列的更有意义的比较。核酸序列的同一性百分比可以如本领域所理解的那样确定。(参见,例如,美国专利号7,396,664,其通过引用整体并入本文)。美国国家生物技术信息中心(ncbi)基本局部比对搜索工具(blast)提供了一套常用且可免费获得的序列比较算法,其可从多个来源获得,包括ncbi,bethesda,md.,在其网站上获得。blast软件套件包括各种序列分析程序,包括“blastn”,其用于将已知的多核苷酸序列与来自各种数据库的其他多核苷酸序列进行比对。还可用的是称为“blast 2sequences”的工具,其用于两个核苷酸序列的直接成对比较。“blast 2sequences”可以在ncbi网站上以交互方式访问和使用。“blast 2sequences”工具可用于blastn和blastp(如上所讨论的)。
83.关于多核苷酸序列,同一性百分比可以在整个确定的多核苷酸序列(例如,如由特定的seq id号确定的)的长度上测量,或者可以在较短的长度上测量,例如,在取自更大的、
确定的序列的片段的长度(例如至少20、至少30、至少40、至少50、至少70、至少100或至少200个连续核苷酸的片段)上测量。此类长度仅是示例性的,并且应理解,本文在表格、附图或序列表中所示序列支持的任何片段长度可用于描述在其上可测量同一性百分比的长度。
84.关于多核苷酸序列,“变体”、“突变体”或“衍生物”可以定义为使用美国国家生物技术信息中心网站上提供的blastn和“blast 2sequences”工具在核酸序列之一的特定长度上与特定核酸序列具有至少50%序列同一性的核酸序列。(参见tatiana a.tatusova,thomas l.madden(1999),"blast 2sequences-a new tool for comparing protein and nucleotide sequences",fems microbiol lett.174:247-250)。此类核酸对可在某个确定的长度上显示例如至少60%、至少70%、至少80%、至少85%、至少90%、至少91%、至少92%、至少93%、至少94%、至少95%、至少96%、至少97%、至少98%或至少99%或更高的序列同一性。
85.由于遗传密码的简并性(其中多个密码子可以编码单一氨基酸),因此不显示高度同一性的核酸序列仍然可以编码相似的氨基酸序列。应当理解,可以使用这种简并性来改变核酸序列以产生全部编码基本相同蛋白质的多个核酸序列。例如,本文考虑的多核苷酸序列可以编码蛋白质并且可以针对在特定宿主中的表达进行密码子优化。在本领域中,已经为包括人、小鼠、大鼠、猪、大肠杆菌、植物和其他宿主细胞在内的许多宿主生物制备了密码子使用频率表。
[0086]“重组核酸”是非天然存在的序列或具有通过人工组合序列的两个或更多个另外分离的区段而制成的序列。这种人工组合通常通过化学合成来实现,或者更常见的通过人工操作核酸的分离的区段(例如通过本领域已知的基因工程技术)来实现。术语重组体包括仅通过添加、取代或缺失一部分核酸而改变的核酸。通常,重组核酸可包括与启动子序列可操作地连接的核酸序列。这样的重组核酸可以是用于例如转化细胞的载体的一部分。
[0087]
本文公开的核酸可以是“基本上分离的或纯化的”。术语“基本上分离或纯化”是指从其天然环境中去除的核酸,并且至少60%不含,优选至少75%不含,以及更优选至少90%不含,甚至更优选至少95%不含与它天然相关的其他组分。
[0088]
肽、多肽、蛋白质和合成方法
[0089]
如本文所用,术语“肽”、“多肽”和“蛋白质”是指包含通过酰胺键连接的氨基酸残基的聚合物链的分子。术语“氨基酸残基”包括但不限于包含在由丙氨酸(ala或a)、半胱氨酸(cys或c)、天冬氨酸(asp或d)、谷氨酸(glu或e)、苯丙氨酸(phe或f)、甘氨酸(gly或g)、组氨酸(his或h)、异亮氨酸(ile或i)、赖氨酸(lys或k)、亮氨酸(leu或l)、甲硫氨酸(met或m)、天冬酰胺(asn或n)、脯氨酸(pro或p)、谷氨酰胺(gln或q)、精氨酸(arg或r)、丝氨酸(ser或s)、苏氨酸(thr或t)、缬氨酸(val或v)、色氨酸(trp或w)和酪氨酸(tyr或y)残基组成的组中的氨基酸残基。术语“氨基酸残基”还可包括非标准或非天然氨基酸。术语“氨基酸残基”可包括α-、β-、γ-和δ-氨基酸。
[0090]
在一些实施方案中,术语“氨基酸残基”可包括包含在由高半胱氨酸、2-氨基己二酸、n-乙基天冬酰胺、3-氨基己二酸、羟赖氨酸、β-丙氨酸、β-氨基丙酸、别羟赖氨酸、2-氨基丁酸、3-羟脯氨酸、4-氨基丁酸、4-羟脯氨酸、哌啶酸、6-氨基己酸、异锁链素、2-氨基庚酸、别异亮氨酸、2-氨基异丁酸、n-甲基甘氨酸、肌氨酸、3-氨基异丁酸、n-甲基异亮氨酸、2-氨基庚二酸、6-n-甲基赖氨酸、2,4-二氨基丁酸、n-甲基缬氨酸、锁链素、正缬氨酸、2,2
’‑
二氨
基庚二酸、正亮氨酸、2,3-二氨基丙酸、鸟氨酸和n-乙基甘氨酸组成的组中的非标准或非天然氨基酸残基。术语“氨基酸残基”可包括任何上述氨基酸的l异构体或d异构体。
[0091]
非标准或非天然氨基酸的其他实例包括但不限于对-乙酰基-l-苯丙氨酸、对-碘-l-苯丙氨酸、o-甲基-l-酪氨酸、对炔丙氧基苯丙氨酸、对-炔丙基-苯丙氨酸、l-3-(2-萘基)丙氨酸、3-甲基-苯丙氨酸、o-4-烯丙基-l-酪氨酸、4-丙基-l-酪氨酸、三-o-乙酰基-glcnacpβ-丝氨酸、l-多巴、氟化苯丙氨酸、异丙基-l-苯丙氨酸、对-叠氮基-l-苯丙氨酸、对-酰基-l-苯丙氨酸、对-苯甲酰基-l-苯丙氨酸、l-磷酸丝氨酸、磷酸丝氨酸、磷酸酪氨酸、对溴苯丙氨酸、对-氨基-l-苯丙氨酸、异丙基-l-苯丙氨酸、酪氨酸氨基酸的非天然类似物;谷氨酰胺氨基酸的非天然类似物;苯丙氨酸氨基酸的非天然类似物;丝氨酸氨基酸的非天然类似物;苏氨酸氨基酸的非天然类似物;甲硫氨酸氨基酸的非天然类似物;亮氨酸氨基酸的非天然类似物;异亮氨酸氨基酸的非天然类似物;烷基、芳基、酰基、叠氮基、氰基、卤素、肼、酰肼、羟基、烯基、炔基、醚、硫醇、磺酰基、硒基、酯、硫代酸、硼酸盐、硼酸酯、26ufa26hor、膦酰基、膦、杂环、烯酮、亚胺、醛、羟胺、酮或氨基取代的氨基酸,或其组合;具有可光活化交联剂的氨基酸;自旋标记的氨基酸;荧光氨基酸;金属结合氨基酸;含金属的氨基酸;放射性氨基酸;光笼罩的和/或光致异构化氨基酸;含生物素或生物素类似物的氨基酸;含酮的氨基酸;包含聚乙二醇或聚醚的氨基酸;重原子取代的氨基酸;可化学裂解或可光裂解的氨基酸;具有延长侧链的氨基酸;含有毒性基团的氨基酸;糖取代的氨基酸;碳连接的含糖氨基酸;具有氧化还原活性的氨基酸;含α-羟基的酸;麦角氨酸(amino thio acid);α,α双取代氨基酸;β-氨基酸;γ-氨基酸,脯氨酸或组氨酸以外的环状氨基酸,苯丙氨酸、酪氨酸或色氨酸以外的芳香族氨基酸。
[0092]
如本文所用,“肽”被定义为氨基酸的短聚合物,其长度通常为20个或更少氨基酸,更通常长度为12个或更少氨基酸(garrett&grisham,biochemistry,第2版,1999,brooks/cole,110)。在一些实施方案中,如本文所考虑的肽可包括不超过约2、3、4、5、6、7、8、9、10、11、12、13、14、15、16、17、18、19或20个氨基酸。多肽,也称为蛋白质,通常具有≥100个氨基酸的长度(garrett&grisham,biochemistry,第2版,1999,brooks/cole,110)。如本文所考虑的多肽可包含但不限于100、101、102、103、104、105、约110、约120、约130、约140、约150、约160、约170、约180、约190、约200、约210、约220、约230、约240、约250、约275、约300、约325、约350、约375、约400、约425、约450、约475、约500、约525、约550、约575、约600、约625、约650、约675、约700、约725、约750、约775、约800、约825、约850、约875、约900、约925、约950、约975、约1000、约1100、约1200、约1300、约1400、约1500、约1750、约2000、约2250、约2500个或更多氨基酸残基。
[0093]
如本文所考虑的肽或多肽可以被进一步修饰以包括非氨基酸部分。修饰可以包括但不限于酰化(例如,o-酰化(酯)、n-酰化(酰胺)、s-酰化(硫酯))、乙酰化(例如,在蛋白质的n-末端或在赖氨酸残基处添加乙酰基)、甲酰化脂酰化(例如,附接硫辛酸酯,一种c8官能团)、肉豆蔻酰化(例如,附接肉豆蔻酸酯,一种c14饱和酸)、棕榈酰化(例如,附接棕榈酸酯,一种c16饱和酸)、烷基化(例如,烷基的添加,例如在赖氨酸或精氨酸残基处添加甲基)、异戊二烯化或戊二烯化(例如,添加类异戊二烯基团,例如法呢醇或香叶基香叶醇)、在c-末端的酰胺化、糖基化(例如,在天冬酰胺、羟赖氨酸、丝氨酸或苏氨酸上添加糖基,产生糖蛋白)。不同于糖化,被认为是糖的非酶促附接、聚唾液酸化(例如,添加聚唾液酸)、糖基磷脂
酰肌醇化(glypiation)(例如,糖基磷脂酰肌醇(gpi)锚形成)、羟基化、碘化(例如甲状腺激素的)和磷酸化(例如,添加磷酸基团,通常添加到丝氨酸、酪氨酸、苏氨酸或组氨酸)。
[0094]
本文公开的修饰的氨基酸序列可以包括一个或多个氨基酸的缺失。如本文所用,“缺失”是指相对于天然氨基酸序列去除一个或多个氨基酸。本文公开的修饰的氨基酸序列可以包括一个或多个氨基酸的插入。如本文所用,“插入”是指向天然氨基酸序列添加一个或多个氨基酸。本文公开的修饰的氨基酸序列可以包括一个或多个氨基酸的取代。如本文所用,“取代”意指用对氨基酸序列而言非天然的氨基酸替换天然氨基酸序列的氨基酸。
[0095]
例如,本文公开的修饰的ngt可以包括一个或多个缺失、插入和/或取代,以便修饰酶的天然氨基酸序列以增强功能。
[0096]
作为另一个实例,“受体肽”或“受体肽序列”被修饰为包括一个或多个被n-糖基转移酶糖基化的异源氨基酸基序。如本文所用,术语“受体肽”或“受体肽序列”是指被ngt靶向用于糖基化的肽序列。示例性受体肽序列是[x-1
]-[n]-[x
1
]-[s/t],其中x是任何典型氨基酸,任选地,其中[x
1
]不是p。受体肽序列的另一个实例是[x-1
]-[n]-[x
1
]-[x
2
],其中x是任何典型氨基酸,任选地,其中[x
1
]不是p,并且任选地,[x
2
]不是s或t。受体肽序列的另一个实例是[x-2
]-[x-1
]-[n]-[x
1
]-[x
2
]-[x
3
],其中x是任何典型氨基酸,任选地,[x
1
]不是p,并且任选地其中[x
2
]不是s和t。如本文所用,术语“靶多肽”是指可以被修饰、纯化、分离或进一步研究的多肽。在一些实施方案中,靶多肽包含受体肽序列并被ngt糖基化。
[0097]
关于蛋白质,“缺失”是指导致一个或多个氨基酸残基的不存在的氨基酸序列的变化。缺失可以去除至少1、2、3、4、5、10、20、50、100、200或更多个氨基酸残基。缺失可包括内部缺失和/或末端缺失(例如,参考多肽的n-末端截短、c-末端截短或两者)。参考多肽序列的“变体”、“突变体”或“衍生物”可以包括相对于参考多肽序列的缺失。
[0098]
关于蛋白质,“片段”是与参考序列在序列上相同但长度比参考序列短的氨基酸序列的一部分。片段可以包含多至参考序列的整个长度,减去至少一个氨基酸残基。例如,片段可分别包含参考多肽的5至1000个连续氨基酸残基。在一些实施方案中,片段可包含参考多肽的至少5、10、15、20、25、30、40、50、60、70、80、90、100、150、250或500个连续氨基酸残基。片段可以优先选自分子的某些区域。术语“至少一个片段”包括全长多肽。相对于全长蛋白质,片段可以包括n-末端截短、c-末端截短或这两种截短。参考多肽序列的“变体”、“突变体”或“衍生物”可以包括参考多肽序列的片段。
[0099]
关于蛋白质,词语“插入”和“添加”是指导致一个或多个氨基酸残基的添加的氨基酸序列的变化。插入或添加可指1、2、3、4、5、10、20、30、40、50、60、70、80、90、100、150、200或更多个氨基酸残基。参考多肽序列的“变体”、“突变体”或“衍生物”可以包括相对于参考多肽序列的插入或添加。蛋白质的变体可具有n-末端插入、c-末端插入、内部插入或n-末端插入、c-末端插入和内部插入的任意组合。
[0100]
关于蛋白质,短语“同一性百分比”和“%同一性”是指使用标准化算法比对的至少两个氨基酸序列之间的残基匹配的百分比。氨基酸序列比对的方法是众所周知的。一些比对方法考虑了保守氨基酸取代。下文更详细解释的此类保守取代通常保留取代位点处的电荷和疏水性,从而保留多肽的结构(并因此保留功能)。氨基酸序列的同一性百分比可以如本领域所理解的那样确定。(参见,例如,美国专利号7,396,664,其通过引用整体并入本文)。国家生物技术信息中心(ncbi)基本局部比对搜索工具(blast)提供了一套常用且可免
费获得的序列比较算法,其可从多个来源获得,包括ncbi,bethesda,md.,在其网站上获得。blast软件套件包括各种序列分析程序,包括“blastp”,其用于将已知氨基酸序列与来自各种数据库的其他氨基酸序列进行比对。
[0101]
关于蛋白质,同一性百分比可以在整个确定的多肽序列(例如,如由特定的seq id号确定的)的长度上测量,或可以在较短的长度上测量,例如,在取自更大的、确定的多肽序列的片段的长度(例如至少15、至少20、至少30、至少40、至少50、至少70或至少150个连续残基的片段)上测量。此类长度仅是示例性的,并且应理解,本文在表格、附图或序列表中所示序列支持的任何片段长度可用于描述在其上可测量同一性百分比的长度。
[0102]
关于蛋白质,如本文所考虑的变体、突变体或衍生物的氨基酸序列可以包括相对于参考氨基酸序列的保守氨基酸取代。例如,变体、突变体或衍生物蛋白质可以包括相对于参考分子的保守氨基酸取代。“保守氨基酸取代”是将氨基酸取代为不同氨基酸的那些取代,其中预测该取代对参考多肽的特性干扰最少。换言之,保守氨基酸取代基本上保留了参考多肽的结构和功能。下表提供了本文考虑的示例性保守氨基酸取代的列表:
[0103]
保守氨基酸取代通常保持(a)取代区域中的多肽主链的结构,例如作为β片层或α螺旋构象,(b)在取代位点处分子的电荷或疏水性,和/或(c)大部分侧链。非保守氨基酸通常破坏(a)取代区域中的多肽主链的结构,例如,作为β片层或α螺旋构象,(b)在取代位点处分子的电荷或疏水性,和/或(c)大部分侧链。
[0104]
本文所述的公开的蛋白质、突变体、变体可以具有由参考多肽展示的一种或多种
功能或生物活性(例如,由野生型蛋白质展示的一种或多种功能或生物活性)。在一些实施方案中,变体或突变蛋白(例如,本文公开的修饰的ngt)的活性可具有与可比野生型或对照ngt酶相比增强的活性,或可具有与可比或野生型或对照ngt酶相比替代的活性或改变的活性。作为示例,但不作为限制,与野生型或对照ngt相比,本文公开的修饰的ngt具有糖基化独特或非典型靶肽序列的能力,和/或具有增加的糖基化效率。示例性野生型ngt是胸膜肺炎放线杆菌的ngt,其氨基酸序列如seq id no:1所示。
[0105]
胸膜肺炎放线杆菌ngt(seq id no:1)
[0106]
胸膜肺炎放线杆菌ngt(seq id no:1a)
[0107]
修饰的ngt
[0108]
氨基酸seq id no:1a(如上所示)与seq id no:1除q469a的单个氨基酸取代外相同。在一些实施方案中,参照seq id no:1a描述了修饰的ngt,氨基酸位置469处的变化称为“a469x”。如本领域所知,ngt的来源可以来源于多种细菌。作为示例,但不作为限制,示例性细菌包括放线杆菌属(actinobacillus)物种、大肠杆菌属(escherichia)物种、嗜血杆菌属(haemophilus)物种或曼氏杆菌属(mannheimia)物种。在一些实施方案中,ngt源自胸膜肺炎放线杆菌、流感嗜血杆菌、溶血性曼氏杆菌、杜克雷嗜血杆菌、鼠疫耶尔森氏菌或大肠杆菌。本文公开了修饰的n-糖基转移酶(ngt)、产生修饰的ngt的方法以及使用修饰的ngt在体外和体内制备糖蛋白和重组糖蛋白的方法。在一些实施方案中,本文公开的ngt包括一个或多个取代突变,并且与相同反应条件下的未修饰的ngt相比,通常糖基化更广泛的受体肽序列,和/或与相同反应状态下的未修饰的ngt相比对更广泛的受体肽序列具有亲和力。
0286637;2007-0026485;2007-0178551。还参见公开的pct国际申请号2003/056914;2004/013151;2004/035605;2006/102652;2006/119987;和2007/120932。还参见jewett,m.c.,hong,s.h.,kwon,y.c.,martin,r.w.,和des soye,b.j.2014,“methods for improved in vitro protein synthesis with proteins containing non-standard amino acids,”美国专利申请系列号:62/044,221;jewett,m.c.,hodgman,c.e.,和gan,r.2013,“methods for yeast cell-free protein synthesis,”美国专利申请系列号:61/792,290;jewett,m.c.,j.a.schoborg,和c.e.hodgman.2014,“substrate replenishment and byproduct removal improve yeast cell-free protein synthesis,”美国专利申请系列号:61/953,275;和jewett,m.c.,anderson,m.j.,stark,j.c.,hodgman,c.e.2015,“methods for activating natural energy metabolism for improved yeast cell-free protein synthesis,”美国专利申请系列号:62/098,578。还参见guarino,c.,&delisa,m.p.(2012).a prokaryote-based cell-free translation system that efficiently synthesizes glycoproteins.glycobiology,22(5),596-601。所有这些参考文献的内容通过引用整体并入本技术。
[0115]
在一些实施方案中,“cfps反应混合物”通常可包含粗制或部分纯化的细胞提取物、rna翻译模板和用于促进从rna翻译模板的无细胞蛋白质合成的合适的反应缓冲液中的一种或多种。在一些方面,cfps反应混合物可以包括外源rna翻译模板。在其他方面,cfps反应混合物可以包括编码与dna依赖性rna聚合酶的启动子元件可操作地连接的开放阅读框的dna表达模板。在这些其他方面,cfps反应混合物还可包括dna依赖性rna聚合酶以指导编码开放阅读框的rna翻译模板的转录。在这些其他方面,cfps反应混合物中可以包含额外的ntp和二价阳离子辅因子。如果反应混合物包含实现反应所需的所有试剂,则称其为完全反应混合物,如果其仅包含一部分必需试剂,则称其为不完全反应混合物。本领域普通技术人员将理解,反应组分通常作为单独的溶液储存,每个溶液包含总组分的一个子集,这是出于方便、储存稳定性的原因,或以允许组分浓度的应用依赖性调整,并且在反应之前将反应组分合并以产生完全反应混合物。此外,本领域普通技术人员将理解,为了商业化,反应组分被分开包装,并且有用的商业试剂盒可以包含本发明的反应组分的任何子集。
[0116]
所公开的无细胞蛋白质合成系统可以利用粗制的和/或至少部分分离和/或纯化的组分。如本文所用,术语“粗制”可以指通过破碎和裂解细胞获得的组分,并且至多最低限度地纯化来自破碎和裂解的细胞的粗制组分,例如通过离心破碎和裂解的细胞并从离心后的上清液和/或沉淀收集粗制组分。术语“分离的或纯化的”是指从其天然环境中取出的组分,并且至少60%不含,优选至少75%不含,以及更优选至少90%不含,甚至更优选至少95%不含与它天然相关的其他组分。
[0117]
如本文所用,多肽的“翻译模板”是指来自表达模板的转录的rna产物,其可被核糖体用于合成多肽或蛋白质。
[0118]
如本文所用,术语“反应混合物”是指含有进行给定反应所需的试剂的溶液。如果反应混合物包含进行反应所需的所有试剂,则该反应混合物被称为完全反应混合物。反应混合物的组分可以分别储存在单独的容器中,每个容器包含全部组分中的一种或多种。组分可以单独包装用于商业化,并且有用的商业试剂盒可以包含反应混合物的反应组分中的一种或多种。
[0119]
反应混合物可以包括表达模板、翻译模板或表达模板和翻译模板两者。表达模板用作用于转录至少一种rna的底物,该rna可以翻译成序列确定的生物聚合物(例如,多肽或蛋白质)。翻译模板是一种rna产物,其可以被核糖体用来合成序列确定的生物聚合物。在某些实施方案中,平台包括表达模板和翻译模板。在某些特定实施方案中,反应混合物可包含偶联的转录/翻译(“tx/tl”)系统,其中从相同细胞提取物合成翻译模板和序列确定的生物聚合物。
[0120]
反应混合物可以包含能够从表达模板产生翻译模板的一种或多种聚合酶。聚合酶可以外源提供或可以从用于制备提取物的生物体提供。在某些特定实施方案中,聚合酶由存在于用于制备提取物的生物体中的质粒和/或用于制备提取物的生物体的基因组中的整合位点表达。
[0121]
改变cfps反应的物理化学环境以更好地模拟细胞质可以改善蛋白质合成活性。以下参数可以单独考虑或与一种或多种其他组分组合考虑以改善基于粗制细胞提取物(例如,s12、s30和s60提取物)的稳健cfps反应平台。温度可以是适合于cfps的任何温度。温度可在约10℃至约40℃的一般范围内,包括该一般范围内的中间特定范围,包括约15℃至约35℃、约15℃至约30℃,约15℃至约25℃。在某些方面,反应温度可以是约15℃、约16℃、约17℃、约18℃、约19℃、约20℃、约21℃、约22℃、约23℃、约24℃、约25℃。
[0122]
反应混合物可以包括适用于cfps的任何有机阴离子。在某些方面,有机阴离子可以是谷氨酸根、乙酸根等。在某些方面,有机阴离子的浓度独立地在约0mm至约200mm的一般范围内,包括该一般范围内的中间特定值,例如约0mm、约10mm、约20mm、约30mm、约40mm、约50mm、约60mm、约70mm、约80mm、约90mm、约100mm、约110mm、约120mm、约130mm、约140mm、约150mm、约160mm、约170mm、约180mm、约190mm和约200mm,等等。
[0123]
反应混合物可以包括适用于cfps的任何卤化物阴离子。在某些方面,卤化物阴离子可以来自氯化物、溴化物、碘化物等。优选的卤化物阴离子来自氯化物。通常,卤化物阴离子(如果存在于反应中)的浓度在约0mm至约200mm的一般范围内,包括该一般范围内的中间特定值,例如本文一般公开的用于有机阴离子的那些。
[0124]
反应混合物可以包括适用于cfps的任何有机阳离子。在某些方面,有机阳离子可以来自多胺,例如亚精胺或腐胺等。优选地多胺存在于cfps反应中。在某些方面,反应中有机阳离子的浓度通常可为约0mm至约3mm、约0.5mm至约2.5mm、约1mm至约2mm。在某些方面,可以存在多于一种有机阳离子。
[0125]
反应混合物可以包括适用于cfps的任何无机阳离子。例如,合适的无机阳离子可包括一价阳离子,例如钠、钾、锂等阳离子;和二价阳离子,例如镁、钙、锰等阳离子。在某些方面,无机阳离子是镁离子。在这样的方面,镁离子浓度可以在约1mm至约50mm的一般范围内,包括在这个一般范围内的中间特定值,例如约1mm、约2mm、约3mm、约5mm、约6mm、约7mm、约8mm、约9mm、约10mm等。在优选的方面,无机阳离子的浓度可在约4mm至约9mm的特定范围内,更优选在约5mm至约7mm的范围内。
[0126]
反应混合物可以包括内源性ntp(即,存在于细胞提取物中的ntp)和/或外源性ntp(即,添加到反应混合物中的ntp)。在某些方面,反应使用atp、gtp、ctp和utp。在某些方面,个体ntp的浓度在约0.1mm至约2mm的范围内。
nat.chem.biol.,2012,8,769-773;ban等人,“on-chip synthesis and label-free assays of oligosaccharide arrays,”chem.int.ed.,2008,47(18),3396-3399;houseman等人,“maleimide-functionalized self-assembled monolayers for the preparation of peptide and carbohydrate biochips,”langmuir,2003,19(5),1522-1531;su等人,“using mass spectrometry to characterize self-assembled monolayers presenting peptides,proteins and carbohydrates,”angew.chem.int.ed.,2002,41,4715-4718;houseman等人,“toward quantitative assays with peptide chips:a surface engineering approach,”trends biotech.,2002,20(7),279-281;houseman等人,“carbohydrate arrays for the evaluation of protein binding and enzyme activity,”chem.biol.,2002,9,443-454);和laurent,n.,等人(2008)."enzymatic glycosylation of peptide arrays on gold surfaces."chembiochem 9(6):883-887);其全部内容通过引用并入本文)。
[0135]
优点
[0136]
下文提供了本文公开的组合物和方法的示例性、非限制性优点。
[0137]
大多数糖蛋白合成方法使用真核生物。目前批准的糖蛋白治疗剂是在哺乳动物或酵母细胞内使用基于ost的糖基化系统生产的。细菌和体外糖基化系统为更密切地控制糖基化模式和更快速地开发更多样的糖基化体系提供了机会。大多数现有的方法使用膜结合的寡糖基转移酶(ost)将脂质连接的糖供体整体转移到蛋白质上。
[0138]
ngt是一种可溶性酶,它将糖从激活的供体直接转移到蛋白质上,而不使用膜结合的组分。然而,它们尚未被广泛用于异源蛋白的修饰,这可能是由于与人基于ost的糖基化系统相比,它们的肽受体和糖供体特异性存在差异。迄今为止,ngt用于修饰重组蛋白通常需要对靶序列进行工程化,因此无法设计有效修饰的糖基化位点。这项工作的广泛目标是开发一系列能够糖基化任何目标序列的工程化的ngt,减轻或消除改变天然存在糖基化位点的靶蛋白的一级氨基酸序列的需要。
[0139]
naegali等人2014年的两项研究表明,ngt可以有效地用葡萄糖、半乳糖、木糖或甘露糖修饰某些n-x-s/t基序,并在活细胞中显示出修饰趋势。这项研究还表明,apngt可以修饰大肠杆菌细胞质中的野生型人促红细胞生成素(尽管蛋白质溶解度和糖基化效率尚未确定)。aebi实验室在一项专利中披露的其他工作表明,野生型细菌自体转运蛋白(ngt的天然底物)在细胞中的修饰及其作为疫苗的潜在用途。
[0140]
2017年,qitao song等人的一项题为“production of homogeneous glycoprotein with multisite modifications by an engineered n-glycosyltransferase mutant”的研究发现,与野生型相比,apngt(q469a)突变体表现出增加的混杂性(promiscuity)和活性。不幸的是,本发明人发现,该突变体仍然只能有效地修饰45%的x-n-x-s/t形式的可能的4-mer糖基化序列(》80%修饰)和对80%的序列无效(》5%修饰)。在本工作中,本发明人对apngt(q469a)酶(seq id no:1a)进行了进一步的工程化,并发现本发明人引入的额外突变允许超过66%的可能的4-mer糖基化序列有效(》80%修饰)和93%的序列无效(》5%)。
[0141]
通过发现具有新特异性的ngt,本发明克服的另一个问题是独特糖在单个重组蛋白内不同n-连接糖基化位点处的位点特异性安装。已经有许多在肽上安装独特聚糖的实
例,因为它们可以通过使用糖基化的氨基酸作为底物的fmoc固相合成来组装。然而,事实证明,在生物生产的蛋白质内多个位点上特异性控制糖基化的位点更为困难。这一领域的大部分工作由牛津大学的benjamin davis教授和同事引领,他们专注于使用双正交或半双正交化学方法对蛋白质内天然存在的氨基酸或非典型氨基酸进行化学修饰。马里兰大学lai-xi wang教授领导的另一组该领域的论文证明了糖苷酶用于指导抗体(pnas,2018)和赤藓素(acs chem biol,2017)的位点特异性糖基化。
[0142]
本研究中所述的ngt将提供一组大大增加的酶特异性,从而实现连续糖基化策略的潜在正交性。
[0143]
本文公开的组合物和方法的其他非限制性优点包括下述:
[0144]
ngt糖基化系统允许多肽的有效修饰,而无需真核宿主、脂质结合的底物和酶,或无需转运至细菌的细胞周质(如使用现有的低聚糖基转移酶糖基化方法所需)。以前,该系统只能修饰有限的一组受体肽序列,并且通常需要修饰天然蛋白质序列以实现有效修饰。目前的发现增加了一组可以有效修饰的序列,使得天然蛋白质序列不需要改变。这些工程化的ngt可以应用于在体外或活细胞中实现糖基化。
[0145]
通过使用工程化的ngt,证明了几种治疗蛋白(包括ifn-γ、gm-csf和人igg fc片段)在大肠杆菌细胞质中和体外通过其天然糖基化序列的改善的糖基化。
[0146]
使用不同的n-糖基转移酶特异性证明了两种不同的聚糖在单个蛋白质上的安装。
[0147]
使用线性模板进行无细胞蛋白质合成,然后进行samdi-ms分析的方法允许快速合成和表征具有》50,000个反应的许多酶变体和变体库。目前对糖基转移酶特异性的研究需要通过亲和纯化、通过结合放射性或化学标记的糖或液相色谱(lc)方法进行筛选以及通过质谱(通常为lc-ms)进行验证,从细胞中表达和纯化酶。这些方法将研究限制在10-100个肽。
[0148]
本文公开的发现允许通过使用工程化的n-糖基转移酶在体外和在细菌细胞质中对天然治疗性蛋白质进行位点特异性和有效的酶促n-连接糖基化。这项技术可以加快糖蛋白治疗剂的开发并降低生产成本。本发明人使用samdi-ms和cfps开发的方法可以快速概括其他目标酶同源物或酶变体的这些结果。
[0149]
应用
[0150]
本文公开的组合物和方法的非限制性应用包括下述:
[0151]
在体外或在细胞中通过工程化的n-糖基转移酶对于改善糖基化的治疗性多肽氨基酸序列的设计;
[0152]
用于替代糖供体或受体肽特异性的高通量工程化糖基转移酶;
[0153]
在工业细菌宿主生物体中产生高滴度的蛋白质(如治疗剂),其在细菌细胞质中是糖基化位点特异性的,无需改变一级氨基酸序列;
[0154]
活细胞中产生的蛋白质的体外糖基化,无需改变其一级氨基酸序列;
[0155]
天然不含典型n-糖基化序列的蛋白质(如治疗剂)的细菌生产或体外糖基化,无需改变其一级氨基酸序列;
[0156]
工程化的n-糖基转移酶在真核细胞胞质内糖基化蛋白质或作为真核n-连接糖基化的正交糖基化方法的用途;
[0157]
我们的工程化的ngt具有比自然界中发现的那些更广泛的肽受体特异性。这可用
于糖基化在细菌或体外系统中无法被糖基化的蛋白质。ngt特异性之间的差异和正交性也可用于通过用工程化的或天然n-糖基转移酶进行连续处理,并通过中间的细化步骤,将不同的聚糖定点特异性地安装到单个蛋白质内的多个位置;
[0158]
分离使用工程化的或天然n-糖基转移酶在所有典型糖基化位点的子集修饰的蛋白质。
[0159]
本发明允许在体外或在细菌系统内生产糖基化的蛋白质,而不修饰其天然氨基酸序列。糖基化的蛋白质,包括蛋白质治疗剂和疫苗。该系统的脂质非依赖性使其对蛋白质治疗剂的体外修饰和细菌细胞质中的糖基化具有吸引力。这些高滴度、快速表达的系统可以使糖蛋白治疗剂更快速、成本更低地开发和生产。
[0160]
本发明还允许在单个蛋白质内的多个位置处位点特异性地安装不同的聚糖。例如,这可以用于将免疫调节聚糖安装到糖缀合疫苗中,或者简单地优化在多个位置处的糖基化结构(例如igg抗体的fab或fc区)。
[0161]
本发明鉴定了用于位点特异性糖基化的酶,特别是工程化的酶,以及序列。
[0162]
其他非限制性应用还包括:
[0163]
修饰的酶(工程化的n-糖基转移酶(ngt)突变体)用于修饰靶蛋白的用途。
[0164]
活细胞中多肽和修饰的酶(工程化的n-糖基转移酶(ngt)突变体)的共表达。
[0165]
多肽序列和修饰的酶(工程化的n-糖基转移酶(ngt)突变体)作为体外糖基化手段的用途。
[0166]
使用用于解吸附电离质谱的自组装单层(samdi-ms)来快速工程化突变的n-糖基转移酶肽和糖特异性的肽和糖特异性的方法。
[0167]
如上所述修饰的酶(工程化的n-糖基转移酶(ngt)突变体)的用途和快速工程化的方法,其中通过无细胞蛋白质合成来合成ngt。
[0168]
如上所述修饰的酶(工程化的n-糖基转移酶(ngt)突变体)的用途和快速工程化的方法来表征和获得具有新特异性的酶。
[0169]
修饰的酶(工程化的n-糖基转移酶(ngt)突变体)来安装替代单糖例如葡萄糖、半乳糖和n-葡糖胺的用途。
[0170]
使用天然存在或工程化的ngt的独特肽受体特异性对蛋白质进行顺序修饰,以在单个蛋白质上安装多个不同的聚糖,或直接修饰所有存在的n-糖基化位点的子集。
[0171]
其他
[0172]
除非本文另有说明或与上下文明显矛盾,否则本文描述的方法的步骤可以以任何合适的顺序执行。除非本文另有说明或与上下文明显矛盾,否则这些步骤可以重复或反复任意次数以实现期望的目标。
[0173]
本文描述了本发明的优选方面,包括发明人已知的用于实施本发明的最佳模式。在阅读上述描述后,那些优选方面的变化对于本领域普通技术人员来说将变得明显。发明人期望本领域的普通技术人员适当地采用这种变化,并且发明人打算以不同于本文具体描述的方式来实践本发明。因此,本发明包括在适用法律允许的情况下在所附权利要求中记载的主题的所有修改和等效物。此外,除非本文另有说明或与上下文明显矛盾,否则本发明涵盖其所有可能变化形式的上述要素的任何组合。示例说明的实施方案
[0174]
以下实施方案是说明性的,并且不应解释为限制所要求保护的主题的范围。
[0175]
实施方案1.一种修饰的n-糖基转移酶(ngt),其选自以下组或其同源物:(i)在氨基酸位置f39、r177、h214、d215、m218、h219、y222、h272、h277、s278、i279、r281、m349、g370、h371、t438、t439、m440、k441、a469(q469)、h495、p497、y498、f517、n521和d525处包含一个或多个取代的放线杆菌属物种(任选地修饰的seq id no:1的胸膜肺炎放线杆菌的ngt);(ii)在氨基酸位置f42、r181、h218、d219、m222、h219、y223、h276、h281、s282、i283、r285、m354、g375、h376、t443、t444、m445、k446、a474(q474)、h500、p502、y503、f522、n526和d530处包含一个或多个取代的金氏菌属物种(任选地修饰的seq id no:2的金氏金格杆菌的ngt);(iii)在氨基酸位置f68、r204、h241、d242、m245、h246、y249、h298、h303、s304、i305、r307、m375、g396、h397、t464、t465、m466、k467、a495(q495)、h521、p523、y524、f543、n547和d551处包含一个或多个取代的嗜血杆菌属物种(任选地修饰的seq id no:3的肺炎嗜血杆菌的ngt);(iv)在氨基酸位置f39、r177、h214、d215、m218、h219、y222、h270、h275、s276、i277、r279、m348、g369、h370、t437、t438、m439、k440、a468(q468)、h494、p496、y497、f516、n520和d524处包含一个或多个取代的聚集杆菌属物种(任选地修饰的seq id no:4的嗜沫聚集杆菌的ngt);(v)在氨基酸位置f39、r177、h214、d215、m218、h219、y222、h272、h277、s278、i279、r281、m349、g370、h371、t438、t439、m440、k441、a469(q469)、h495、p497、y498、f517、n521和d525处包含一个或多个取代的曼氏杆菌属物种(任选地修饰的seq id no:5的溶血性曼氏杆菌的ngt);(vi)在氨基酸位置f40、r180、h217、d218、m221、h222、y225、h274、h279、s280、i281、r283、m351、g372、h373、t440、t441、m442、k443、a471(q471)、h497、p499、y500、f519、n523和d527处包含一个或多个取代的百伯史坦菌属物种(任选地修饰的seq idno:6的海藻百伯史坦菌的ngt);和(vii)在氨基酸位置f38、r176、h213、d214、m217、h218、y221、h271、h276、s277、i278、r280、m348、g369、h370、t437、t438、m439、k440、a468(q468)、h494、p496、y497、f516、n520和d524处包含一个或多个取代的嗜血杆菌属物种(任选地修饰的seq id no:7的杜克雷嗜血杆菌的ngt)。
[0176]
实施方案2.实施方案1的修饰的ngt,其中参考seq id no:1,氨基酸取代位于选自由h219、t438、a696和h495或其同源位置组成的组的一个或多个位置。
[0177]
实施方案3.实施方案1的修饰的ngt,其中参考seq id no:1,氨基酸取代位于选自由以下组成的组的一个或多个位置:h219f或h219w;t438s或t438e;a696g或a696i;和h495d或其同源位置。
[0178]
实施方案4.实施方案1的修饰的ngt,其中野生型ngt包含seq id no:1-7中的任何一个,并且参考seq id no:1,修饰的ngt在选自由以下组成的组的位置处包含至少一个取代突变:h219f、h219w、t438s、t439e、a469g、a469i、h495d、h219f-t438s、h219f-h495d、h219w-t438s、h219w-h495d、a469g-h495d和a469i-h495d或其同源位置;其中h219f-t438s、h219f-h495d、h219w-t438s、h219w-h495d、a469g-h495d和a469i-h495d是两个取代突变的组合。
[0179]
实施方案5.前述实施方案中任一项的修饰的ngt,其中与相同反应条件下的未修饰的ngt相比,修饰的ngt糖基化更广泛的受体肽序列。
[0180]
实施方案6.前述实施方案中任一项的修饰的ngt,其中与相同反应条件下的未修饰的ngt相比,修饰ngt对更广泛的受体肽序列具有亲和力。
[0181]
实施方案7.前述实施方案中任一项的修饰的ngt,其中受体肽序列包含氨基酸序列[x-2-]-[x-1-]-[n]-[x
1
]-[x
1
]-[x
2
]-[x
3
],其中x是任何典型氨基酸,并且任选地其中[x
1
]不是p。
[0182]
实施方案8.前述实施方案中任一项的修饰的ngt,其中受体肽序列包含氨基酸序列[x-2
]-[x-1-]-[n]-[x
1
]-[x
1
]-[x
2
]-[x
3
],其中x是任何典型氨基酸,并且任选地其中[x
1
]不是p,并且任选地其中[x
2
]不是s或t。
[0183]
实施方案9.一种多核苷酸序列,其编码前述实施方案中任一项的修饰的ngt。
[0184]
实施方案10.一种表达载体,其包含实施方案9的多核苷酸序列。
[0185]
实施方案11.一种细菌细胞,其包含实施方案1-8中任一项的修饰的ngt、实施方案9的多核苷酸序列或实施方案10的表达载体。
[0186]
实施方案12.实施方案11的细菌细胞,进一步包含靶多肽。
[0187]
实施方案13.一种真核细胞,其包含实施方案1-8中任一项的修饰的ngt、实施方案9的多核苷酸序列或实施方案10的表达载体。
[0188]
实施方案14.实施方案13的真核细胞,进一步包含靶多肽。
[0189]
实施方案15.一种用于糖基化靶多肽的方法,其中靶多肽包含受体肽序列,所述方法包括:在合适的反应条件下使靶多肽与实施方案1-8中任一项的修饰的ngt和聚糖接触。
[0190]
实施方案16.实施方案15的方法,其中靶多肽包括治疗性多肽。
[0191]
实施方案17.实施方案15或16的方法,其中方法在体内进行。
[0192]
实施方案18.实施方案15或16的方法,其中方法在体外进行。
[0193]
实施方案19.实施方案15-18中任一项的方法,其中靶多肽是原核蛋白质。
[0194]
实施方案20.实施方案15-18中任一项的方法,其中靶多肽是真核蛋白质。
[0195]
实施方案21.实施方案15-20中任一项的方法,其中靶多肽包含受体肽序列,所述受体肽序列包含氨基酸序列[x-2
]-[x-1-]-[n]-[x
1
]-[x
1
]-[x
2
]-[x
3
],其中x是任何典型氨基酸,并且任选地其中[x
1
]不是p,并且任选地其中[x
2
]不是s或t。
[0196]
实施方案22.实施方案15-21中任一项的方法,其中ngt用一种或多种聚糖来糖基化靶多肽。
[0197]
实施方案23.实施方案15-22中任一项的方法,其中聚糖包含一种或多种选自由葡萄糖、半乳糖和n-葡糖胺组成的组的单糖。
[0198]
实施方案24.一种修饰的n-糖基转移酶(ngt),其包含在对应于seq id no:1的胸膜肺炎放线杆菌ngt的下述氨基酸位置处的一个或多个取代:f39、r177、h214、d215、m218、h219、y222、h272、h277、s278、i279、r281、m349、g370、h371、t438、t439、m440、k441、a469、h495、p497、y498、f517、n521和d525。
[0199]
实施方案25.实施方案24的修饰的ngt,其中ngt衍生自选自以下组成的组的生物体:金氏金格杆菌;流感嗜血杆菌;嗜沫聚集杆菌;溶血性曼氏杆菌;海藻百伯史坦菌;杜克雷嗜血杆菌;伯克霍尔德氏菌属物种;小肠结肠炎耶尔森氏菌;鼠疫耶尔森氏菌;肠道沙门氏菌;和大肠杆菌。
[0200]
实施方案26.实施方案24的修饰的ngt,其中ngt衍生自选自由溶血性曼氏杆菌和杜克雷嗜血杆菌组成的组的生物体。
[0201]
实施方案27.实施方案24-26中任一项的修饰的ngt,其中与相同反应条件下的未
修饰的ngt相比,修饰的ngt糖基化更广泛的受体肽序列。
[0202]
实施方案28.实施方案24-26中任一项的修饰的ngt,其中与相同反应条件下的未修饰的ngt相比,修饰的ngt对更广泛的受体肽序列具有亲和力。
[0203]
实施方案29.一种治疗组合物,其包含实施方案16的治疗肽。
[0204]
实施方案30.实施方案29的治疗组合物,其中组合物包含疫苗。
实施例
[0205]
以下实施例是示例说明性的,并不旨在限制所请求保护的主题的范围。
[0206]
实施例1
–
使用高通量分析以工程化具有改变特异性的n-糖基转移酶
[0207]
a.引言
[0208]
n-连接蛋白质糖基化是用复合寡糖修饰天冬酰胺侧链,是自然界中最常见和最复杂的翻译后修饰(ptm)之一1。在真核生物中,n-聚糖安装在典型序列基序n-x-s/t(其中x≠p)处2。大多数蛋白质治疗剂是n-糖基化的3,并且已知糖基化模式的差异对生物活性
4,5
、蛋白质稳定性6和血清半衰期7有强烈影响。也已经证明在治疗性蛋白质中引入额外的n-糖基化位点可以改善治疗特性,包括延长血清半衰期
8,9
。尽管使用具有内源性n-糖基化途径的哺乳动物细胞系是生产糖蛋白治疗剂的最常见方法,但这些组成系统限制了可以构建的聚糖结构的多样性
10,11
,并且常常受到糖蛋白产物的异质性的影响
3,12,13
。这些限制促使开发在大肠杆菌(e.coli)中或在体外的合成糖基化系统,以安装
10,14-18
或重塑
12,16
定义的聚糖,以精确控制糖蛋白的结构和性质。
[0209]
在这些合成糖基化系统中,一类被称为n-糖基转移酶(ngt)的细菌胞质酶对糖工程化很重要,因为它们可以有效地将尿嘧啶-二磷酸-葡萄糖(udp-glc)糖供体的单个葡萄糖残基转移到某些天然真核序列上
19,20
。然后可以使用糖基转移酶
21
或内切糖苷酶化学酶聚糖重塑
22,23
将该葡萄糖残基延伸成全长聚糖。对ngt特异性的严格分析表明,ngt只能修饰所有可能的真核n-糖基化序列的一部分
19,22
。由于存在一组不断扩大的可通过糖工程化进行优化的潜在治疗性蛋白质靶标,包括不含典型n-x-s/t糖基化序列的蛋白质,因此显然需要工程化或发现能够修饰一组扩大的受体序列的ngt。这项工作的广泛目标是开发一系列能够糖基化任何目标序列的ngt,减轻改变靶蛋白用于天然存在的糖基化位点的一级氨基酸序列或引入新糖基化位置的需要。
[0210]
基于传统定向进化的方法对于将酶活性工程化至单一底物是有效的,但还不适合开发显示多种功能(即,不同的肽特异性)的酶。wells和合作者通过开发一种方法来解决这一限制,该方法通过使用液相色谱串联质谱(lc-ms/ms)蛋白质组学方法从大肠杆菌蛋白质组中鉴定修饰的底物来工程化肽连接酶
24
。虽然蛋白质组学鉴定对连接酶和蛋白酶很有效
25
,但很难应用于糖基化酶,因为糖肽的富集方法不可推广,底物肽长度的差异强烈影响糖基化效率
19
。此外,蛋白质组学鉴定提供了一些关于底物偏好的信息,但不直接测量活性。本发明人已经开发了一种称为用于基质辅助激光解吸/电离质谱的自组装单层(samdi-ms)的通用和多用途测定法,其可以快速和定量地测量大量底物上的酶特异性和活性,而无需纯化酶或底物
19,26,27
。发明人最近将该方法与酶的无细胞蛋白质合成(cfps)相组合,以创建glycoscores工作流程,发明人将其用于分析几种ngt的特异性
19,22
。
[0211]
在此,本发明人公开了利用glycoscores工作流程和来自pcr衍生的线性表达模板
的高通量cfps反应(let-cfps)
28
来开发一组ngt,其显著扩大了可直接糖基化的序列范围。开发该组的并行工作流程依赖于两个关键步骤。首先,发明人在亲本ngt的26个位点饱和变体文库(ssvl)的池中筛选受体序列特异性。每个ssvl由在特定残基处的19个突变体组成,所述特定残基是基于ngt晶体结构和与底物肽的预期相互作用的检查而被靶向诱变的。通过在底物肽文库上筛选这些ssvl,本发明人分别鉴定了相对于糖基化的天冬酰胺在底物肽的x-2
、x-1
、x
1
、x
2
和x
3
位置处决定特异性的残基。其次,本发明人产生并严格表征了精确的单或双突变体,它们共同扩大了与单独的亲本ngt相比可以有效修饰的典型(n-x-s/t,其中x≠p)和非典型(n-x-z,其中x≠p和z≠s/t)肽序列的集合。除了亲本ngt之外,本发明人发现了13个ngt突变体,其显著增加了所有x-1
和x
1
典型序列组合(总共684个)的比例,这些组合可以以约45%至65%的产率进行高效修饰。另一组ngt允许修饰具有x
2
位置(除s/t之外,17个氨基酸中的10个,例如ala、asp、met和val)的多种序列。此外,与亲本ngt相比,本发明人通过提高经批准的治疗性蛋白质的修饰效率,而不修饰其氨基酸序列,证明了ngt突变体组的效用。本发明人预期该方法将有助于开发具有改变的特异性的额外酶,并且本发明人预期在此发现的ngt突变体将显著扩大细菌和体外糖工程的应用领域。
[0212]
b.结果
[0213]
1.通过位点饱和文库筛选来鉴定特异性决定残基
[0214]
为了开发一组突变ngt酶,其能够有效地修饰广泛的所定义蛋白质糖基化位点,发明人首先着手鉴定直接决定底物特异性的残基。虽然ngt复合物与底物的晶体结构可以提供这一信息,但来自胸膜肺炎放线杆菌(apngt)的ngt
29
的已知晶体结构不提供受体肽的位置,仅显示udp-glc糖供体的尿嘧啶-二磷酸(udp)部分。因此,有必要首先通过直接筛选酶突变体来鉴定决定特异性的残基。为此,本发明人选择了apngt的udp结合口袋周围的26个残基进行诱变(图1a)。然后,本发明人使用先前报道的apngt的q469a突变体(我们将该亲本突变体称为apq)
20,30
作为起点(因为其对于肽底物的活性远高于野生型apngt),为这些残基中的每一个订购了完全饱和的文库作为线性dna。这些ssvl中的每一个含有dna编码酶,所述酶为在26个靶向残基中的一个残基处具有19个非野生型氨基酸(由“x”表示)的近似相等的混合物。通过这种方式,本发明人将每个文库作为一个池而不是单个克隆进行测试,以确定对活性和肽特异性具有最大影响的残基。
[0215]
本发明人对这些ssvl中的每一个进行pcr,并直接使用所得的线性表达模板(let)来驱动cfps中蛋白质ssvl的表达(图1b)。与apq相比,所有26个ssvl的表达水平相似(图14a-e)。所有26个蛋白质ssvl以及亲本apq直接用于具有基序x-1-n-x
1-trc的361个成员底物文库中每个肽的糖基化测定法,其中x-1
和x
1
是19个氨基酸之一(cys除外)。体外糖基化(ivg)后,肽和糖肽通过与c-末端半胱氨酸反应共价地下拉到马来酰亚胺官能化的自组装单层上,然后用samdi-ms分析肽修饰(修饰热图如图15所示)。
[0216]
为了比较apq和每个ssvl之间的差异,本发明人首先计算了整个肽文库的平均活性。本发明人使用的肽底物浓度通常比大多数肽和ngt组合的km低10倍
19,20
,并因此能够使用等式-ln(1-y)=k
cat
/km*c*t来比较每个反应的近似k
cat
/km,其中c是酶浓度,t是反应时间,y是修饰的产率。本发明人转换了26个蛋白质ssvl的每个热图内的每个修饰数据点,以生成显示-ln(1-y)的热图(图1b),并然后获得了所有361个肽中每个ssvl近似的平均k
cat
/km值。虽然这种定量方法不能为每种酶-底物组合提供精确的k
cat
/km值(这样做需要对每种
底物进行数十次单独的测量),但它确实允许基于文库中每种肽底物的361个数据点来呈现和比较每种ssvl的平均k
cat
/km的一个近似值。为了进行比较,然后将每个ssvl的平均k
cat
/km针对apq的平均k
cat
/km归一化(图1c,详见方法)。正如可以预期的,没有ssvl(测量为所有361个肽的平均值)显示出比亲本apq更大的活性。本发明人观察到,r177x、d215x、r281x和m440x ssvl具有最差的平均活性(相对于apq小于2%),表明这些ssvl中没有个体突变体提供接近apq的活性,并且这些残基可能对apq的催化或底物(肽受体或糖供体)结合很重要。
[0217]
接下来,为了确定在底物肽的每个位置处强烈影响特异性的残基,本发明人定量地比较了每个ssvl与apq的底物特异性差异。本发明人首先测量了不同浓度apq下x-1-n-x
1-trc肽文库的修饰,以生成具有平均-ln(1-y)的不同水平的apq的一系列热图。通过这种方式,本发明人可以选择适当的热图,以便使用具有相同值的平均-ln(1-y)的热图来比较apq和26个蛋白质ssvl中的每一个的肽选择性差异(图16)。然后,本发明人使用等式2*|ave(x)-ave(apq)|/(ave(x) ave(apq)),从该x-1
氨基酸内所有19个肽的平均-ln(1-y)值计算出相比于apq,每个ssvl的每个x-1
氨基酸(热图的每行)的百分比差异,其中ave(x)和ave(apq)分别是每个ssvl和apq的平均-ln(1-y)。x-1
氨基酸行中所有19个百分比差异的平均值给出了x-1
位置的平均百分比差异(图1d)。本发明人进行了类似的分析,以确定每个ssvl的x
1
位置的平均百分比差异(图1d)。apq和所有ssvl之间的平均百分比差异热图如图17所示。基于这些数据,本发明人得出结论,在决定酶对受体肽的x-1
位置的特异性方面发挥最强作用的残基从最强到最弱依次为:t438、a469、y498、h214和i279。类似地,本发明人发现,对于x
1
位置,残基a469、h214、r177、h219和t438对特异性的影响最大。本发明人发现,残基469在确定x-1
和x
1
位置两者以及先前报道的udp糖供体的酶特异性方面发挥了相对强大的作用
29、30
。
[0218]
在鉴定了在决定apq对受体肽的x-1
和x
1
位置的多肽特异性方面发挥最强作用的残基之后,本发明人接下来进行了类似的实验,以鉴定影响对于x
2
、x-2
和x
3
位置的特异性的残基。在此,本发明人选择了apq优选的六个代表性x-1-n-x
1-trc肽序列,并产生了新的肽文库,该肽文库分别在x
2
位置用其他18个氨基酸取代thr,添加19个x-2
氨基酸,或插入19个x
3
氨基酸(同样,在所有肽中排除cys)。然后,本发明人筛选了对早期实验表明在特异性中具有重要作用的每个位置进行选择ssvl的特异性。本发明人发现,d215和r177对于决定x
2
位置的特异性、h277对于决定x-2
和h214对于决定x
3
位置的特异性是重要的(图18-20)。这些观察结果鉴定了与受体肽相互作用并决定其特异性的那些残基(如图21所示);然而,他们并没有严格地确定相互作用是直接的。
[0219]
2.筛选具有独特底物特异性的单个ngt突变体
[0220]
在鉴定特异性决定残基后,本发明人试图筛选在这些残基处的个体突变体,以了解哪些肽序列优选作为底物。基于他们的分析,本发明人决定使用x-1-n-x
1-trc肽文库对26个ssvl中的三个(h219、t438和a469)内的每个突变体的活性进行去卷积(deconvolute)(图22-24)。本发明人首先通过线性dna的环化和所得质粒的转化从ssvl中分离个体突变体(参见方法)。本发明人发现,每个个体变体的表达水平相似(图14a-e)。只有t438s显示平均糖基化活性的增加超过apq(图2a),而t438d/e/k/r/w和h219r的活性最差(相对于apq小于0.1%)。t438处的突变体(根据筛选,t438可能是肽结合的重要残基)的活性在19个突变体中显著变化。本发明人还分析了针对这些个体突变体的肽选择性(图2b)。大多数t438突变
csf)和人免疫球蛋白抗体(igg1)的恒定区(fc)。在肽水平上,发明人发现纯化的a469i突变体对ifnγ中的序列tnys糖基化比apq更有效(图4a)。类似地,t438s糖基化gm-csf的lnls序列比apq更有效,并且h495d糖基化fc的ynst序列比apq更有效(图4a)。然后,本发明人使用纯化的ifnγ和gm-csf作为底物在蛋白质水平上证实了这些相对活性。糖基化后,用胰蛋白酶消化靶蛋白,并通过液相色谱四极飞行时间(lc-qtof)质谱进行分析(图4b)。使用整合提取离子色谱图的面积百分比(面积%)进行的相对修饰表明,ngt突变体比apq更有效地实现糖基化(图4b)。本发明人还使用ms2来确认靶向肽的身份(图33a-c)。值得注意的是,折叠的完整蛋白质内的序列的糖基化效率低于那些作为游离肽的序列。使用fc作为实例,本发明人表明,通过在cfps反应开始时补充ngt以同时表达和糖基化底物蛋白,可以改善蛋白质的修饰。通过在cfps反应中fc表达之前而不是之后添加2μm apq,本发明人发现fc的糖基化效率从15%增加到46%(图34a-b和图12)。在cfps之前补充2μm h495d突变体而不是apq显著地增加fc的修饰至60%或1.3倍(图4c和图12)。通过补充5μm的h495d,可以实现fc的80%修饰(图34a-b)。总之,这些数据表明,具有典型糖基化序列n-x-s/t的天然氨基酸序列可以用我们高通量实验鉴定的突变ngt更有效地修饰。
[0228]
5.将x
2
选择性扩展到典型糖基化基序之外
[0229]
到目前为止,靶蛋白的酶促n-糖基化需要典型的n-x-s/t糖基化基序,该基序要么自然存在,要么通过改变一级氨基酸序列引入。这一要求对推广蛋白质糖基化的酶提出了重大限制。然而,在不修饰一级氨基酸序列的情况下引入新的糖基化位点也可以通过工程化的ngt来实现,所述工程化的ngt具有超过典型糖基化基序n-x-s/t的序列偏好。因此,开发在x
2
位置处不需要ser或thr的ngt将显著扩大适合糖基化的序列和蛋白质的范围。基于他们先前的特异性筛选和假设的肽结合残基(图18和21),本发明人试图通过在(x-1
nx
1
)x
2
rc形式的肽文库中筛选r177和d215的所有个体突变体,来发现可以糖基化在x
2
位置处不含ser或thr的肽的突变体(图35)。正如预期的那样,本发明人发现大多数突变体耐受在x
2
位置处的s/t。然而,本发明人还发现,在x
2
位置,r177个体突变体耐受a/r/p/v,d215个体突变体耐受a/d/e/v/i/l,apq耐受a/g(图5a)。d215g对x
2
氨基酸表现出最广泛的杂合性,可以用a/m/d/v/i/l以相对较高的效率修饰序列,以及用g/q/w/e/n/f/y以中等效率修饰序列。有趣的是,本发明人发现d215f/i/l/v失去了其对在x
2
处具有s/t的肽的偏好(图5b)。该信息可用于指导选择ngt突变体以靶向具有给定x
2
氨基酸的序列(图5a)或选择性地靶向具有一个x
2
氨基酸而非另一个的序列(图5b)。
[0230]
最后,本发明人试图探索哪些非典型序列可能被他们新发现的r177和d215突变体所靶向,这些突变体针对x
2
位置处表现出扩大的特异性。在之前的ssvl筛选中,d215x在x-1
和x
1
特异性方面几乎没有变化。因此,d215x的x-1-n-x
1-trc筛选(图15)可用于近似所有d215突变体对x-1
和x
1
组合的特异性。然而,本发明人还观察到r177x显著改变了对x-1
位置的酶选择性。因此,本发明人用x-1-n-x
1-trc筛选了所有r177突变体,以确定哪些x-1
和x
1
组合可以与在x
2
位置处的非s/t氨基酸一起使用(图36)。总体而言,本发明人发现在x
2
位置处的10个非s/t氨基酸(a/g/m/r/d/e/p/v/i/l)可以在肽水平上以相对高的效率被修饰。然而,本发明人注意到,非典型序列的修饰仍然不如典型序列的修饰有效。需要对靶向非典型肽序列的ngt进行进一步的工程化或进化,以实现治疗性蛋白质中非典型序列的高效修饰。
[0231]
c.讨论
[0232]
在这项工作中,发明人提出了一种系统的方法来鉴定决定对肽底物的每个氨基酸位置的特异性的酶残基,并且本发明人使用这些位点作为起点来开发一组特异性不同的ngt,其能够修饰底物序列的独特集合。他们的高通量glycoscores表征技术能够通过52,894个独立反应筛选123个个体ngt。据发明人所知,这是迄今为止完成的最详细的糖基转移酶工程化和表征工作,超过了现有技术的水平近四倍
19
。通过对工作流程的轻微调整,这种开发用于修饰整个底物文库的酶库的方法应适用于其他糖基转移酶
19
、蛋白酶
26
、磷酸酶
31
、脱乙酰酶
32
和其他酶
33,34
。
[0233]
两个关键特征使该方法变得重要。首先,严格的表征使得能够开发14个ngt的组,显著扩大了可用于细菌酶糖基化的序列集。在本发明人调查的典型真核糖基化基序(x-1-n-x
1-s/t,其中x
1
≠p)内的684个肽中,发现与apq相比,13个ngt突变体之一以显著更高的效率修饰了260个肽(图10-11)。这些变体将可以被ngt高效糖基化的序列的百分比从45%提高到66%(~0.5μm ngt和3h反应的修饰率超过80%)。通过从图32中报告的热图中鉴定最佳ngt,该扩大的ngt组允许目标序列的合理糖基化。本发明人成功地应用该策略以分别使用apq的a469i、t438s和h495d突变体来增加治疗性蛋白质ifnγ、gm-csf和fc的修饰。本发明人还开发了ngt,其可以糖基化甚至优选在x
2
位置处具有非s/t氨基酸的典型n-x-s/t基序之外的序列。这一发现拓宽了糖工程化的范围,使研究人员能够研究如何使用聚糖来改善更多样组别的蛋白质的性质,而无需修饰其天然氨基酸序列。值得注意的是,在这项工作中发现的许多突变体具有非常不同的底物特异性,这可能通过顺序修饰在单个蛋白质的多个序列上实现糖基化结构的位点特异性控制
22
,从而实现协同聚糖相互作用的精确工程化。
[0234]
其次,这项工作很重要,因为它突出了高通量实验的重要性。虽然典型的定向进化工作流程导致能够执行单个反应的酶,但这种方法可用于开发具有多种性质的酶。事实上,glycoscores(cfps和samdi-ms的组合)实现的活性监测的并行方法产生了具有独特特异性的变体,其在许多不同底物上实现了活性模式,并为糖工程化提供了新的可能性。
[0235]
虽然这项工作侧重于糖基化的起始步骤,但已经开发了许多酶和化学酶技术,以将ngt安装的单糖细化为类人或其他有用的聚糖。例如,使用内切糖苷酶和化学合成的噁唑啉供体的化学酶法可用于安装全长人聚糖
22,23
。这些全长人聚糖可增加蛋白质的血清半衰期
35
,或通过在人igg4的fc区上安装同质的n-聚糖来提供调节其他治疗效果的方法
4,12
。还开发了将ngt安装的葡萄糖扩展到多种有用聚糖(包括聚唾液酸)的生物合成方法
21
。值得注意的是,人n-聚糖的还原性末端糖是n-乙酰氨基葡萄糖(glcnac),而不是ngt安装的葡萄糖。这种差异对糖蛋白免疫原性和其他特性的影响尚不清楚,需要对每种应用进行评估。已经开发了使用apq安装n-葡糖胺(glcn)和乙酰转移酶glma的两步方法
30
,并且本发明人目前正在致力于发现可以更有效地转移glcn、甚至glcnac的ngt突变体。例如,本发明人发现a469i和t438s可以比apq更有效地用glcn修饰某些肽(图37)。在这项工作中发现的几个其他高活性突变体也可以用glcn修饰肽(图37)。
[0236]
尽管显著增加了可被糖基化的序列范围,但本发明人确实认识到围绕靶向的糖基化序列的蛋白质结构会影响修饰的效率。ngt通常在翻译后作用于折叠的蛋白质,因此被掩埋或刚性锁定在二级或三级结构中的位点可能不可被ngt所修饰。因此,一些靶标可能需要使用其他现有的糖基化方法,该糖基化方法使用低聚糖基转移酶(ost)。虽然ost是复杂的整体膜蛋白,并需要脂质连接的寡糖(llo)底物,但它们能够在未折叠位点进行共翻译修
饰
36,37
。尽管最近努力工程化或发现具有扩大特异性的ost
38,39
,但通常仍需要通过延伸或以其他方式改变靶蛋白的一级氨基酸序列来安装糖基化标签(glycytag),以实现糖基化
17,40
。因此,也迫切需要对ost进行类似于本文针对ngt进行的工作的全面工程化,以扩大允许使用ost进行修饰的序列集。
[0237]
总之,本发明人通过使用let-cfps和samdi-ms在广泛的底物上并行生成和表征许多酶突变体,证明了高通量实验在工程化糖基转移酶方面的应用。使用该方法,本发明人开发了一组严格表征、易于表达、完全可溶的n-糖基化酶,其具有独特的活性,将作为糖工程化界的宝贵资源。本发明人预期,这组ngt将在蛋白质治疗剂的细菌或体外糖工程化中特别有用,因为它减轻了改变一级氨基酸序列以实现许多蛋白质治疗剂的糖基化的需要。最终,本发明人的方法有望促进对糖科学的基本理解,并实现糖工程化的新应用。
[0238]
e.方法
[0239]
1.肽文库合成和samdi筛选
[0240]
如前所述,使用n-乙酰基和c-酰胺合成所有肽文库
19
。每个肽文库的平均浓度也如前所述进行确定
19
,以及平均相对电离因子(rif)的计算。如前所述,制备samdi平板,并将其用于肽筛选
19
。
[0241]
对于肽筛选,将50μm肽与指定浓度的ngt(在let-cfps中纯化或生产)以及在100mm hepes(ph 8.0)和500mm nacl中的2.5mm udp-glc于30℃反应指定时间。类似地,使用50μm肽和1.09μm ngt(在let-cfps中产生)以及在100mm hepes(ph 8.0)和500mm nacl中的2.5mm udp glcn(在chemically glycoscience中定制合成)于30℃进行12h来完成对肽的udp-glcn修饰的筛选。ivg反应后,加入tcep树脂(pierce),并于37℃孵育1h。将这些还原的ivg的2μl溶液添加到384孔的马来酰亚胺官能化samdi平板的岛上并于室温孵育0.5h。由于在1-h tcep还原和0.5-hsamdi孵育步骤期间反应未被淬灭,因此本发明人将此时间近似为额外的1h反应,用于近似k
cat
/km计算。然后用水、乙醇、水和乙醇洗涤samdi平板,然后用氮气流进行干燥。将在丙酮中的10mg/ml 2’,4’,6
’‑
三羟基苯乙酮一水合物(thap;sigma aldrich)作为基质施加到samdi平板上。然后,使用ab sciex 5800tof/tof仪器,用基质辅助激光解吸电离飞行时间(maldi-tof)质谱法分析平板。光谱使用applied biosystems sciex time of flight series explorer软件4.1.0版进行处理。所有肽文库筛选均以n=1完成。使用由相对电离因子(rif)调整的光谱峰比来确定修饰效率
19
(图8),除了udp-glcn的数据,其显示了糖肽(产物峰)与所有肽(底物和产物峰)的相对强度。
[0242]
2.线性和质粒ssvl的合成。twist bioscience在卡那霉素抗性基因内开放的pjl1无细胞表达骨架的线性化形式内合成了apq ssvl的26个的线性dna,从而使安装在5'和3'端的sapi限制性酶位点再环化将产生pjl1.apq。ssvl的质粒形式是通过使用有sapi限制酶的golden gate组装方法环化这些线性文库而产生的
41
。将30ng(6μl)的每个线性文库与1μl的每种10,000u/ml sapi限制酶、10mm atp、10x cutsmart缓冲液和2,000,000 t4连接酶(所有产品均来自new england biolabs)孵育。环化反应进行30个循环,于37℃进行1min,于16℃进行1min和随后于65℃进行5min。然后将完成的环化反应转化到dh5α电感受态细胞中,并铺板在lb(kan )上。所有平板均产生100多个菌落(确保文库覆盖率为5倍)。过夜生长后,用5ml的lb培养基洗涤这些lb(kan )平板,并进行小型制备以生成质粒文库。
[0243]
3.从ssvl中分离单个ngt突变体
[0244]
通过热激将选择的残基r177、d215、h219、t438、a469和h495的质粒ssvl转化到dh5α高效化学感受态细胞(new england biolabs)中,然后在lb琼脂平板(kan )上孵育。从每个ssvl转化中挑选50多个克隆,在lb(kan )培养基中培养,进行小型制备并测序,以分离所有19个个体突变体。
[0245]
4.单突变体和双突变体的构建
[0246]
使用先前报道的pjl1.apq模板的单位点pcr诱变产生apq的单突变体
42
。简而言之,进行了25μl pcr反应,其包含12.5μl q5热启动高保真2x主混合物(new england biolabs)、1ng模板、500nm引物对。用于这些pcr的引物和tm温度如图13所示。pcr于98℃启动30s;随后是15个循环:于98℃进行10秒、tm2进行30秒和72℃进行2min;于tm1进行1min和于72℃进行4min以结束。pcr后,加入2.5μl 10x cutsmart缓冲液和0.5μl dpni(new england biolabs),并于37℃孵育2h。使用琼脂糖凝胶电泳确认产生全长pcr产物(~3.5kb)。pcr溶液(经dpni处理后)通过热激转化dh5α高效化学感受态细胞中,并铺板在lb琼脂平板(kan )上。每个平板的两个克隆被挑取、培养、小型制备和测序。除了使用单个突变体作为初始质粒模板外,类似地产生了双突变体。
[0247]
5.let-cfps
[0248]
如前所述使用源自大肠杆菌菌株bl21 star(de3)的粗制裂解物进行cfps反应
22,43
,其中使用pcr产生的线性dna表达模板而非质粒
28
。如前所述通过bl21 star(de3)大肠杆菌细胞的生长、收获和裂解来制备cfps的粗制裂解物
43
,其中使用总能量输入为640j,用于裂解1ml细胞悬浮液。let-cfps反应在含有1.2mm atp(ph 7.2),0.85mm gtp、utp和ctp(ph 7.2);34μg/ml亚叶酸;171μg/ml大肠杆菌-trna混合物;2mm的20个标准氨基酸;0.33mm烟酰胺腺嘌呤二核苷酸(nad);0.27mm辅酶a(coa);1.5mm精胺;1mm腐胺;4mm草酸钠;130mm谷氨酸钾;10mm谷氨酸铵;8mm谷氨酸镁;57mm hepes(ph 7.2);33mm磷酸烯醇式丙酮酸盐(pep,ph 7);20%v/v ngt线性模板;以及27%v/v的bl21粗提取物的2.0ml离心管内以50μl进行。在pcr反应中生成ngt线性模板,并直接使用,无需纯化。60μl pcr反应包含30μl q5热启动高保真2x主混合物、1.2ng模板(由twist合成的线性ssvl或单个突变质粒)、500nm引物对(ccaccctgactgagtgagcgttc和gcagttcattgatgctcgatg)。pcr于98℃启动30s;然后是36个循环:于98℃进行10s、于65℃进行30s和于72℃进行1min;于72进行2min来结束。除来自菌株mre600和pep(roche applied science)的大肠杆菌总trna混合物外,cfps中使用的所有试剂均购自sigma-aldrich。所有cfps反应均于22℃进行20h。反应后,向cfps溶液中加入1:1v/v的2x roche完全蛋白酶抑制剂混合物和5mm edta,将溶液在液氮中快速冷冻,并储存于-80℃以备将来使用。
[0249]
6.肽文库x-1-n-x
1-trc的近似k
cat
/km计算
[0250]
根据先前的研究,apngt的x-2-x-1-n-x
1-t-x
3-rc形式的优化肽的km大于0.5mm
19
,并且长肽底物通常表现出比短肽更低的km值
20
。先前的报告还发现,与apngt相比,apq的km相差约1.5倍
20
。基于这些发现,本发明人使用的肽浓度(50μm)远小于本研究中使用的ngt变体的km。因此,本发明人使用方程k
cat
/km=-ln(1-y)/c/t来近似k
cat
/km的值,其中y是肽的修饰,c是所用酶的浓度,并且t是糖基化的反应时间。从修饰热图产生热图,显示了-ln(1-y)的值,其与肽的k
cat
/km、c(ngt)和t成正比。
[0251]
虽然近似,但这一计算使我们能够比较所有肽-酶组合的活性,其反应比严格确定kcat
/km值所需的反应少10倍以上。本发明人还注意到,来自361个条件的完整文库的平均k
cat
/km值将比单个k
cat
/km近似值更准确。本发明人使用平均k
cat
/km来比较不同酶浓度和反应时间下每个突变体或ssvl之间的活性。由于表观平均k
cat
/km受平均-ln(1-y)值的影响(图16a-d),突变体的相对平均k
cat
/km与产生相同平均-ln(1-y)值的apq筛选进行比较。通过计算每个肽-ngt组合的近似k
cat
/km并选择提供最高值的ngt突变体,确定了为全套典型真核糖基化序列(x-1-n-x
1-t/s-rc)的糖基化选择的最佳ngt(图27-28)。选择的ngt(包括apq)在相同条件下进行筛选。具体而言,在let-cfps中产生0.545μm ngt,并于30℃孵育3h前与2.5mm udp-glc和50μm肽组合。
[0252]
7.ssvl或单个突变体与apq之间的平均百分比差异分析
[0253]
为了作为比较ssvl或单个突变体的特异性与apq的特异性的参考,在使用不同量apq进行ivg后,分析了几个x-1-n-x
1-trc热图,产生了具有不同-ln(1-y)平均值的热图,其中y是修饰。使用这些apq参考热图中的两个之间的线性插值,生成了具有与给定ssvl或单个突变体的测量热图相同的平均-ln(1-y)的理论apq热图(图16a-d中的参考apq热图和计算过程描述)。然后,本发明人使用方程2*|ave(x)-ave(apq)|/(ave(x) ave(apq))计算了理论apq热图中具有给定x-1
氨基酸泳道的所有19个肽的-ln(1-y)值的平均值(定义为ave(apq))与测量突变体热图中的具有给定x-1
氨基酸泳道的所有19个肽的-ln(1-y)值的平均值(定义为ave(x))。并且,所有19个x-1
氨基酸行的百分比差异平均值提供x-1
的平均百分比差异。相似地计算x
1
平均百分比差异值。整个x-1-n-x
1-trc文库的平均百分比差异是所有x-1
和x
1
泳道的平均百分比差异的平均值。该计算方法用于生成图1a-d、-2a-c和图16a-d所示的平均百分比差异。
[0254]
8.通过平均百分比差异对ssvl和单个突变体特异性进行组合比较
[0255]
为了比较单个突变体或ssvl彼此之间的特异性,本发明人根据每个突变体与apq的平均百分比差异计算了任意两个突变体之间的平均百分比差异。每个x-1
或x
1
泳道的2*(ave(x)-ave(apq))/(ave(x) ave(apq))的数值,而不是绝对值,如上所述针对每个突变体进行计算,并定义为突变体1的pd1和突变体2的pd2。然后使用方程|pd
1-pd2|/(1-pd1*pd2)计算每个x-1
或x
1
泳道处突变体1和2之间的百分比差异。使用该方法,本发明人分别计算了x-1
、x
1
或整个文库的每个残基处所有ssvl或分离的突变体之间的平均百分比差异。该计算基于这样的假设:当从具有不同-ln(1-y)平均值的热图进行确定时,两个ngt之间的每个x-1
和x
1
泳道的百分比差异保持不变。该计算方法用于生成图17和26中的平均百分比差异。
[0256]
9.apq和突变质粒的构建、在大肠杆菌中的表达和纯化
[0257]
apq突变体构建体在pet21b载体中产生,用于体内表达和纯化。对pjl1载体中的体外构建体,以与上述相同的方式进行诱变。所用的引物和tm如图13所示。ngt如前所述进行了纯化,并进行了少量修饰
19
。简言之,通过热激,用pet21b.apq或突变质粒转化bl21star(de3)化学感受态细胞。在lb(carb )培养基中接种过夜培养物。新鲜lb(carb )以初始od600=0.08接种,细胞于37℃、在250rpm下生长至0.6
–
0.8od,并于30℃用1mm异丙基β-d-1-硫代吡喃半乳糖苷(iptg)诱导6h。通过于4℃以5000
×
g离心10min将细胞成团,再悬浮于缓冲液3(20mm tris-hcl和250mm nacl,ph 8.0)中,通过于4℃以8000
×
g离心10min再次成团,并于-80℃快速冷冻。然后将团粒解冻并以每克湿团粒重量5ml缓冲液3重新悬浮在缓冲液3中,并补充1mg/ml溶菌酶(sigma)、1μl苯并酶(benzonase,millipore)和1
×
halt蛋白酶
抑制剂(thermo fisher scientific)。然后通过在21,000psig(avestin)下的单通匀浆化裂解细胞,并于4℃以13000
×
g离心20min。向上清液中加入咪唑至终浓度为20mm。将上清液施加到1ml ni-nta琼脂糖树脂(qiagen)中(树脂用含有20mm咪唑的缓冲液3进行平衡)。1-h孵育后,用5个柱体积的含有20mm咪唑的缓冲液3洗涤树脂一次,用5个柱体积的含有30mm咪唑的缓冲液3洗涤两次,再用5个柱体积的含有40mm咪唑的缓冲液3洗涤一次。用1个柱体积的含有500mm咪唑的缓冲液3中洗脱蛋白质。洗脱液针对50mm hepes、200mm nacl、ph 7.0进行透析,并于-80℃快速冷冻。使用以下参数用nanodrop uv-vis分光光度计(thermo fisher)定量蛋白质浓度:分子量:71502.50da,消光系数:63260m-1
cm-1
。
[0258]
10.胰蛋白酶化糖肽的体外蛋白质糖基化和lc-qtof分析。
[0259]
10μm ifnγ(millipore)或gm-csf(r&d systems)与缓冲液1(50mm nah2po4(ph 8)和300mm nacl)中的5μm纯化apq或突变体和5mm udp-glc反应。反应于30℃进行12h。反应后,将10μl溶液稀释至30μl,并于室温用pierce 96孔微透析平板(3.5k mwco)针对1:4稀释的缓冲液1进行透析8h。将1μl 0.5mg/ml胰蛋白酶(pierce,在1mm hcl中)加入透析的溶液中,并于37℃孵育16h。向反应物中加入1μl的0.25mm dtt,然后在冰上静置1h。如前所述分析胰蛋白酶化糖肽
22
。简言之,将5-10μl胰蛋白酶消化的样品注入配备acquity uplc肽beh c18柱的bruker elute uplc系统,c18柱为1.7μm,2.1mm x 100mm(waters corporation的186003686),带有10mm保护柱(186004629waters corporation),连接到impact-ii uhr tof质谱仪(bruker daltonics,inc.)。色谱分离方法使用100%水和0.1%甲酸作为溶剂a,100%乙腈和0.1%甲酸作为溶剂b。使用100%a进行1min,0%至50%b的梯度进行4min来完成色谱。流速保持在0.5ml/min。以8hz收集100~3000da范围内的质谱。对所有光谱进行了外部校准。本发明人使用ms/ms以监测碰撞能量为50ev的靶肽和糖肽(图33a-c所示的光谱)。bruker compass数据分析软件4.1版用于分析数据。将靶肽和糖肽质量的提取离子色谱图中的目标峰进行积分,以使用%面积、面积(p)/(面积(s) 面积(p))计算修饰。结果如图12所示。
[0260]
11.let-cfps蛋白表达和糖基化
[0261]
pjl1.fc以与ngt相同的方式在let-cfps中表达,添加2或5μm纯化的apq或h495d突变体和5mm udp-glc。于30℃的6-h cfps孵育后,将70μl缓冲液1(含有5mm咪唑)加入50μl cfps溶液中。反应物于4℃以12000xg离心15min,上清液与30μl his dynabeads(invitrogen)混合用于10-min孵育。珠粒用120μl缓冲液1(含有5mm咪唑)洗涤三次,并用80μl缓冲液1(含有500mm咪唑)进行洗脱。洗脱溶液用pierce 96孔微透析板(3.5k mwco)于室温针对1:4稀释的缓冲液1透析8h。将1μl 0.5mg/ml胰蛋白酶(pierce,在1mm hcl中)加入40μl透析溶液中,并于37℃孵育16h。向反应中加入1μl 0.25mm dtt,然后将其置于冰上1h。如上所述进行lc-qtof分析。
[0262]
当注意到fc的糖基化在cfps(折叠后)后完成时,fc在let-cfps中在30℃和20-h孵育进行表达,然后离心并补充2μm纯化的apq和5mm udp-glc。然后将该ivg反应于30℃孵育6h。如上所述进行这些反应物的纯化、透析、胰蛋白酶化和lc-qtof分析。
[0263]
12.t检验和数据分析
[0264]
双尾学生t检验和所得p值在microsoft excel 2016中计算。对于所有肽文库筛选,仅使用n=1个实验。对于靶蛋白序列的肽ivg,进行n=3个独立反应。对于治疗性蛋白质
glycoproteins with eukaryotic n-glycosylation.nat.chem.biol.6,264-266(2010).
[0281]
16.guarino,c.&delisa,m.p.a prokaryote-based cell-free translation system that efficiently synthesizes glycoproteins.glycobiology 22,596-601(2012).
[0282]
17.schoborg,j.a.et al.a cell-free platform for rapid synthesis and testing of active oligosaccharyltransferases.biotechnol.bioeng.,739-750(2018).
[0283]
18.wacker,m.et al.n-linked glycosylation in campylobacter jejuni and its functional transfer into e.coli.science 298,1790-1793(2002).
[0284]
19.kightlinger,w.et al.design of glycosylation sites by rapid synthesis and analysis of glycosyltransferases.nat.chem.biol.14,627-635(2018).
[0285]
20.song,q.et al.production of homogeneous glycoprotein with multisite modifications by an engineered n-glycosyltransferase mutant.j.biol.chem.292,8856-8863(2017).
[0286]
21.keys,t.g.et al.a biosynthetic route for polysialylating proteins in escherichia coli.metab.eng.44,293-301(2017).
[0287]
22.lin,l.,kightlinger,w.,hockenberry,a.j.,jewett,m.c.&mrksich,m.sequential glycosylation of proteins with substrate-specificn-glycosyltransferases.acs cent.sci.in revision(2019).
[0288]
23.lomino,j.v.et al.a two-step enzymatic glycosylation of polypeptides with complex n-glycans.bioorg.med.chem.21,2262-2270(2013).
[0289]
24.weeks,a.m.&wells,j.a.engineering peptide ligase specificity by proteomic identification of ligation sites.nat.chem.biol.14,50-57(2018).
[0290]
25.schilling,o.&overall,c.m.proteome-derived,database-searchable peptide libraries for identifying protease cleavage sites.nat.biotechnol.26,685-694(2008).
[0291]
26.wood,s.e.et al.a bottom-up proteomic approach to identify substrate specificity of outer-membrane protease ompt.angew.chem.int.ed.129,16758-16762(2017).
[0292]
27.gurard-levin,z.a.,kim,j.&mrksich,m.combining mass spectrometry and peptide arrays to profile the specificities of histone deacetylases.chembiochem 10,2159-2161(2009).
[0293]
28.schinn,s.m.,broadbent,a.,bradley,w.t.&bundy,b.c.protein synthesis directly from pcr:progress and applications of cell-free protein synthesis with linear dna.new biotechnol.33,480-487(2016).
[0294]
29.kawai,f.et al.structural insights into the glycosyltransferase activity of the actinobacillus pleuropneumoniae hmw1c-like protein.j.biol.chem.286,38546-38557(2011).
cell-free transcription-translation system enriched with glycosylation machinery.nat.commun.9,2686(2018).
[0326]
ollis,anne a et al.“engineered oligosaccharyltransferases with greatly relaxed acceptor-site specificity.”nature chemical biology vol.10,10(2014):816-22.doi:10.1038/nchembio.1609.
[0327]
song,q.et al.production of homogeneous glycoprotein with multi-site modifications by an engineered n-glycosyltransferase mutant.journal of biological chemistry(2017).
[0328]
ollis,a.a.;chai,y.;natarajan,a.;perregaux,e.;jaroentomeechai,t.;guarino,c.;smith,j.;zhang,s.;delisa,m.p.,substitute sweeteners:diverse bacterial oligosaccharyltransferases with unique n-glycosylation site preferences.scientific reports 2015,5,15237.
[0329]
van kasteren,s.i.;kramer,h.b.;gamblin,d.p.;davis,b.g.,site-selective glycosylation of proteins:creating synthetic glycoproteins.nat.protoc.2007,2(12),3185-3194.
[0330]
van kasteren,s.i.;kramer,h.b.;jensen,h.h.;campbell,s.j.;kirkpatrick,j.;oldham,n.j.;anthony,d.c.;davis,b.g.,expanding the diversity of chemical protein modification allows post-translational mimicry.nature 2007,446(7139),1105-1109.
[0331]
wright,t.h.;bower,b.j.;chalker,j.m.;bernardes,g.j.;wiewiora,r.;ng,w.l.;raj,r.;faulkner,s.;vallee,m.r.;phanumartwiwath,a.;coleman,o.d.;thezenas,m.l.;khan,m.;galan,s.r.;lercher,l.;schombs,m.w.;gerstberger,s.;palm-espling,m.e.;baldwin,a.j.;kessler,b.m.;claridge,t.d.;mohammed,s.;davis,b.g.,posttranslational mutagenesis:a chemical strategy for exploring protein side-chain diversity.science 2016,354(6312),aag1465.
[0332]
yang,q.;an,y.;zhu,s.;zhang,r.;loke,c.m.;cipollo,j.f.;wang,l.-x.,glycan remodeling of human erythropoietin(epo)through combined mammalian cell engineering and chemoenzymatic transglycosylation.acs chemical biology 2017,12(6),1665-1673.
[0333]
giddens,j.p.;lomino,j.v.;dilillo,d.j.;ravetch,j.v.;wang,l.-x.,site-selective chemoenzymatic glycoengineering of fab and fc glycans of a therapeutic antibody.proceedings of the national academy of sciences 2018,115(47),12023-12027.
[0334]
专利参考:us20140194345a1,us20180354997a1,cn 201610012793,us8703471,us8999668,us20050170452,us20060211085,us20060234345,us20060252672,us20060257399,us20060286637,us20070026485,us20070178551,wo2003056914a1,wo2004035605a2,wo2006102652a2,wo2006119987a2,wo2007120932a2。
[0335]
在上述描述中,本领域技术人员很容易理解,在不脱离本发明的范围和精神的情况下,可以对本文公开的发明进行各种替换和修改。本文中说明性描述的本发明可以在不
存在本文中未具体公开的任何一个或多个元素或限制的情况下适当地实践。已经使用的术语和表达被用作描述的术语而非限制性的术语,并且在使用这些术语和表达时无意排除所示出和描述的特征或其部分的任何等价物,但是应当认识到,在本发明的范围内可以进行各种修改。因此,应当理解,虽然本发明已经通过特定实施方案和可选特征来说明,但是本领域技术人员可以采用本文公开的概念的修改和/或变化,并且这种修改和变化被认为在本发明的范围内。
[0336]
本文中描述的所有方法都可以以任何合适的顺序执行,除非本文中另有说明或上下文中另有明确矛盾。本文中提供的任何和所有示例的应用仅旨在更好地说明本发明,并且除非另有要求,否则不对本发明的范围构成限制。说明书中的任何语言都不应被解释为将任何未要求保护的元素指示为本发明的实践所必需的。
[0337]
本文引用了许多专利和非专利参考文献。引用的参考文献通过引用全部并入本文。如果与引用的参考文献中的术语定义相比,说明书中的术语的定义不一致,则应根据说明书中的定义来解释该术语。
再多了解一些
本文用于创业者技术爱好者查询,仅供学习研究,如用于商业用途,请联系技术所有人。