1.本发明属于语音识别技术领域,涉及语音合成技术,具体涉及一种语音合成用声学模型训练方法。
背景技术:
2.语音合成芯片常用于银行、医院、停车场等场景中的播报,不需要支持完整的中英文混合,但是需要对字母进行正确的发音。在中文语音合成系统中,通常需要对英文字母进行正确播报,而中英文作为不同的语系,其发音基础音素区别很大。
3.通常中文音素声韵母共47个,英文音素48个,如果想完成中文语音合成系统播报英文字母的功能,可以有以下处理方式:1)拼接法,直接根据字母插入语料库中提前录制好的音频数据进行播报;2)将英文字母发音音素按照中文音素进行标注后播报;3)设计两套发音音素,实现中英文混合合成播报。
4.第一种方法的拼接方法韵律感差,不能体现同一字母在不同文本中的合成差异;第二种方法合成的字母发音效果较差,中式英语发音明显;第三种方法需要增加一套语系的发音规则,语言学特征复杂,计算量大,对只要求字母发音的中文语音合成系统来说,消耗较大。
技术实现要素:
5.为克服现有技术存在的缺陷;本发明公开了一种语音合成用声学模型训练方法。
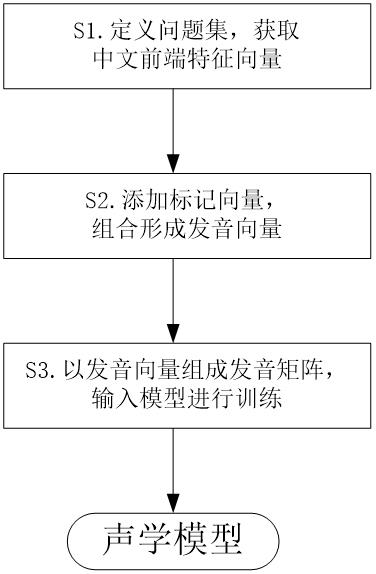
6.本发明所述一种语音合成用声学模型训练方法,包括以下步骤:s1. 根据汉语发音规则,制定问题集,以问题集定义文本中每个汉字的中文前端特征向量,以m维发音向量表示;s2.对字母的发音,以汉语语言发音规则定义,并以步骤s1制定的问题集,对文本中出现的字母,赋予该字母的中文前端特征向量;在文本中每个文字的中文前端特征向量后添加n维标记向量,所述文字包括汉字和字母,添加的n维标记向量用于区分文字是汉字还是英文字母,所述n远小于m;添加后的(m n)维向量,表示该文字的发音向量;s3.将文本中各个文字的发音向量组合形成文本的发音矩阵,作为声学模型的输入,进行声学模型的训练,训练得到的声学模型用于语音合成。
7.优选的,所述问题集均为判断类问题,所述中文前端特征向量的元素只有0,1两种。
8.优选的,所述问题集包括原始读音子集和所处文本环境子集,所述原始读音子集以遍历方式对汉语发音的全部声母和韵母进行提问。
9.优选的,所述n维标记向量的所有元素均相同。
10.优选的,其特征在于,n:m=1:50-100。
11.优选的,所述步骤s3中,训练时以梅尔频谱声学特征作为声学模型的输出。
12.优选的,所述声学模型使用隐马尔可夫或dnn模型框架。
13.采用本发明所述语音合成用声学模型训练方法, 可以在增加少量特征维度的情况下,提升中文语音合成系统中字母的发音效果,节约算力和存储消耗。
附图说明
14.图1为本发明所述声学模型训练方法的一种具体实施方式示意图;图2为本发明所述问题集的一种具体实施方式示意图;图3为本发明一个具体实施例得到的频谱图;图4为图3中具体实施例基于相同文本采用现有技术合成语音得到的频谱图。
具体实施方式
15.下面对本发明的具体实施方式作进一步的详细说明。
16.本发明所述提升语音合成中字母发音效果的方法,采用以下步骤实现:s1. 根据汉语语言发音规则,制定问题集,以问题集定义文本中每个汉字的中文前端特征向量,以m维发音向量表示;该中文前端特征向量用于描述文本中每个汉字的发音信息;每一维度表示该汉字在文本中发音时要考虑的一个因素;例如,发音信息包括该汉字的原始读音,由声母和韵母组成,确定汉字的声母和韵母后,确定汉字的原始读音;如文本:谢谢使用,其发音信息可以为: x ie4 x ie5 sh i3 y ong4;其中 x\ x \sh \ y\为声母, ie\ ie\i\ong为韵母,4、5、3、4为声调。
17.为得出一个文本的发音信息,一个典型实施方式为,罗列中文发音中的全部声母和韵母,分别设计一个维度,以遍历全部维度的方式确定声母和韵母;例如中文发音中声母有b、p、m、f等23个,韵母有a、o、e等24个,则共有47个维度用于表示该汉字的原始读音,如可用“当前音素是否为音素b”表示其中一个维度,该维度为1表示当前音素为b,否则不为b,其余维度类似。可以以上述47个维度作为问题集中的原始发音子集。
18.同时,根据中文阅读习惯,还需要考虑其他问题来最终确定发音,例如,该汉字是否为多音字,该汉字所处语境是否为叠音,该汉字的前一个字和后一个字的基础发音分别是什么,该汉字是否为问句中的关键字等。
19.例如“谢谢”,地道的发音中第二个“谢”应该发轻声,第二个“谢”也发四声则显得生硬。又例如“我不爱吃”和“我不可能”中的“不”,地道的发音中应该分别发二声和四声。
20.综合考虑包括但不限于上述规律在内的汉字在文本中的发音规律,可以作为问题集中的所处文本环境子集,即文字发音除原始发音以外的全部因素。
21.所处文本环境子集的设计可以参考现有技术中已整理出的汉语发音规则,如黄伯荣、廖序东编著的《现代汉语》进行问题设计和罗列。
22.设计一系列问题形成问题集用于定义文字在文本中的发音规则,以问题集的答案为是或否作为该汉字的维度形成m维发音向量,最终以该m维发音向量定义该汉字的发音。
23.问题集的优选实施方式为全部或大部分采用判断类问题,以减小中文前端特征向量的元素种类,可以提高后期训练速度。
24.例如问题集共10个问题,前7个问题为是,以1表示,后3个问题为否,以0表示,则该汉字在该问题集下的发音由中文前端特征向量(1,1,1,1,1,1,1,0,0,0)定义。
25.对于部分判断类问题无法涵盖的问题,也可以采用多个元素作为答案输入中文前端特征向量,例如问题“音素所处句子有多少字”这样的问题,可以不采用判断类问题。
26.以英文字母为例,对步骤s2进行说明。
27.s2.对英文字母的发音,以汉语语言发音规则定义,并以步骤s1制定的问题集,对文本中出现的英文字母,赋予该英文字母的中文前端特征向量;例如对英文字母a、b、c分别定义其原始发音为:a: ei1b :b i1c: s ei1则可以采用步骤1得到的问题集对全部英文字母进行中文前端特征向量定义。
28.对汉字和英文字母,在文本中每个文字的中文前端特征向量后添加n维标记向量,所述文字包括汉字和英文字母,添加的n维标记向量用于区分文字是汉字还是英文字母,所述n远小于m;添加后的(m n)维向量,表示该文字的发音向量。
29.n取值太小,在后续模型训练时,神经网络模型如dnn模型可能无法识别出标记向量,影响对英文字母的有效判断,n取值太大,则增加计算量和特征存储空间。一般n:m=1:50-100。
30.所述n维标记向量的所有元素均相同,例如,用10维全零向量作为汉字的标记向量,用10维全1向量作为英文的标记向量,所有元素相同,意味着中文和英文的标记向量每个元素均不相同,在训练时更容易识别。
31.s3.将文本中各个文字的发音向量组合形成文本的发音矩阵,作为声学模型的输入,进行声学模型的训练;训练好的声学模型用于合成语音的输出,输出语音时,可将待合成的文本送入声学模型输出即可得到文本所对应的音频数据。
32.如图3和图4所示给出,对含有英文字母的文本“陕e 0b25b”采用不同方法合成频谱对比,图4为采用拼接法的得到的频谱结果,图3和图4中,上层为时域波形,中间为频谱波形,下方为文本;图3为采用本发明所述训练方法训练得到的声学模型的合成结果,合成目标均为年轻女士发音。图4可见各个发音宽度近似,发音较为单一呆板,显示出拼接法整理韵律感不强,不能体现同一字母在不同文本中的发音差异;而图3所示的本发明得到的合成结果各个发音宽度差异较大;按照发音习惯,同一字母在文本中不同位置的发音会存在差异,包括时长、重音、分词停顿等,直接选择音频库里的音频进行拼接听感上不够连贯,影响音频的可理解性。由图3频谱可见拼接法生成的音频中不同位置字母b的发音相同,而本发明所述方法则体现出了字母b在文本中不同位置的发音区别;符合汉语对英文字母的发音习惯,本发明训练得到的声学模型合成音则更自然流畅。
33.前文所述的为本发明的各个优选实施例,各个优选实施例中的优选实施方式如果不是明显自相矛盾或以某一优选实施方式为前提,各个优选实施方式都可以任意叠加组合
使用,所述实施例以及实施例中的具体参数仅是为了清楚表述发明人的发明验证过程,并非用以限制本发明的专利保护范围,本发明的专利保护范围仍然以其权利要求书为准,凡是运用本发明的说明书及附图内容所作的等同结构变化,同理均应包含在本发明的保护范围内。
再多了解一些
本文用于创业者技术爱好者查询,仅供学习研究,如用于商业用途,请联系技术所有人。