1.本发明涉及音频信号处理技术领域,特别涉及一种适应复杂环境的语音预处理系统。
背景技术:
2.随着人工智能时代的到来,语音信号的预处理更加注重质量,对初始语音信号底噪平坦度的要求也越来越高。不同语音场景中对语音信号的处理要求不同,在很多语音识别应用中,需要事先滤除数字信号中的噪声和谐波,再根据后级语音识别算法提取特征值,最终完成语音识别。
3.现实环境中的情况复杂多变,往往充斥着噪音和各阶谐波,因此,如何实现对复杂环境中语音信号的滤波和提取有效信息,对语音识别应用至关重要。
技术实现要素:
4.本发明的目的在于提供一种适应复杂环境的语音预处理系统,以解决背景技术中的问题。
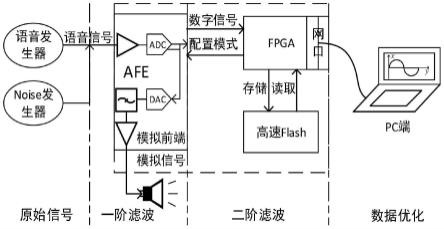
5.为解决上述技术问题,本发明提供了一种适应复杂环境的语音预处理系统,包括模拟前端电路、fpga、高速flash和pc端;
6.所述模拟前端电路接收来自信号源的模拟信号,通过配置内部寄存器进行高通滤波、抽取滤波和插值滤波,滤除高频噪声和信号采样率骤变带来的影响,然后将分析出的数字信号传输到fpga中;
7.所述fpga通过滤波算法硬件加速器进行处理,将中间关键数据存储到所述高速flash中,并通过网口电路传输到所述pc端进行优化处理,之后供后级用户层决策。
8.在一种实施方式中,所述模拟前端电路的输入信号由低衰减线缆接入,所述模拟前端电路的模拟输出可选择性接到外部的音频发生器上。
9.在一种实施方式中,所述fpga实时接收所述模拟前端电路的输出信号,并在下一帧信号到来之前同时将上一帧信号转存到高速flash中;
10.所述fpga通过低衰减高质量网口线将处理结果实时发送到所述pc端;所述pc端内置的数据处理模块根据输入音频信号的频段和特征点自适应分配对应最优语音处理算法。
11.在一种实施方式中,所述音频信号的频段分为人类听觉范围、人类发声范围和乐音范围;所述音频信号的特征分为时域特征、频域特征、乐音特征、感知特征和情绪特征;音频处理过程分为回音消除、声音增强、波束形成、啸声抑制和虚拟重建,对应的语音处理算法是深度学习aec算法、自动增益控制算法、空域滤波算法、傅里叶分析和倒频分析。
12.在一种实施方式中,所述fpga与所述高速flash之间的连接遵循一般高速并行线布线规则;所述fpga与网口电路之间的布线遵循一般高速布线规则;所述fpga适用于内部le单元数大于30000,内部运行速度大于200mhz。
13.在一种实施方式中,所述fpga的滤波算法硬件加速器所辅助的算法为有限脉冲响
应和无线脉冲响应。
14.在一种实施方式中,所述模拟前端电路的型号为ad73311,所述fpga的型号为xilinx系列kintex-7,所述高速flash的型号为sst38vf6404。
15.在本发明提供的适应复杂环境的语音预处理系统中,模拟前端电路接收来自信号源的模拟信号,通过配置内部寄存器进行高通滤波、抽取滤波和插值滤波,滤除高频噪声和信号采样率骤变带来的影响,然后将分析出的数字信号传输到fpga中;所述fpga通过滤波算法硬件加速器进行处理,将中间关键数据存储到高速flash中,并通过网口电路传输到pc端进行优化处理,之后供后级用户层决策。本发明对初始模拟信号进行三重处理,最大程度上还原初始语音信号,为语音识别以及类似应用提供一种参考,以提高整体系统的效率与可靠性。
附图说明
16.图1为本发明提供的一种适应复杂环境的语音预处理系统的结构框图;
17.图2为本发明提供的一种适应复杂环境的语音预处理系统的流程图。
具体实施方式
18.以下结合附图和具体实施例对本发明提出的一种适应复杂环境的语音预处理系统作进一步详细说明。根据下面说明,本发明的优点和特征将更清楚。需说明的是,附图均采用非常简化的形式且均使用非精准的比例,仅用以方便、明晰地辅助说明本发明实施例的目的。
19.本发明提供一种适应复杂环境的语音预处理系统,可以用于提取语音信号中的有效信息,对原始信号进行三重处理,最大程度上还原初始语音信号,为语音识别以及类似应用提供一种参考,以提高整体系统的效率与可靠性。
20.如图1所示,所述适应复杂环境的语音预处理系统包括模拟前端(analog front end,afe)电路、fpga、高速flash和pc端;所述模拟前端电路既能接收模拟音频信号又可产生模拟输出,所述pc端内置数据处理模块。
21.所述模拟前端电路接收到来自信号源的模拟信号后,可通过配置内部寄存器进行高通滤波、抽取滤波和插值滤波,以滤除高频噪音和信号采样率骤变带来的影响,然后将分析出的数字信号传输到fpga中;
22.所述fpga使用硬件滤波算法加速器进行处理,然后将部分中间关键数据存储到所述高速flash中,并传输到pc端进行优化处理,之后供后级用户层决策。所述模拟前端电路的型号可以使用ad73311,fpga的型号可以使用xilinx系列kintex-7型fpga,高速flash的型号可以使用sst38vf6404。
23.所述模拟前端电路的输入信号由低衰减线缆接入;所述模拟前端电路的模拟输出可选择性接到外部的音频发生器上;所述fpga可实时接收所述模拟前端电路的输出信号,并在下一帧信号到来之前同时将已经接收的上一帧信号转存到所述高速flash中;所述fpga还可通过低衰减高质量网口线实时地将处理结果发送到pc端;所述pc端内置的数据处理模块可根据输入音频信号频段和特征点自适应分配对应最优算法,如不收敛可自动切换次优算法。音频信号的频段不妨可分为:人类听觉范围(20hz-20000hz)、人类发声范围
(100hz-10000hz)和乐音范围(50hz-20000hz)。所述fpga的滤波算法硬件加速器所辅助的算法一般为有限脉冲响应(fir)和无线脉冲响应(iir),这里不妨使用fir滤波器,即有限脉冲响应滤波器。所述音频信号的频段一般分为人类听觉范围、人类发声范围和乐音范围;所述音频信号特征分为:时域特征、频域特征、乐音特征、感知特征和情绪特征;所述语音处理算法一般根据具体处理过程细分,音频处理过程一般分为回音消除、声音增强、波束形成、啸声抑制和虚拟重建等过程,对应的算法可以是深度学习aec算法、自动增益控制算法、空域滤波算法、傅里叶分析和倒频分析等。
24.所述适应复杂环境的语音预处理系统的工作流程如图2所示,包括如下步骤:
25.(1)系统上电或复位后初始化;
26.(2)配置模拟前端电路的工作模式,启动插值抽取滤波算法,回读寄存器,若配置成功,则继续步骤(3),否则回到步骤(1);
27.(3)启动fpga的硬件滤波加速器,然后内部自检状态信息,若执行成功则继续步骤(4),否则继续执行步骤(3);
28.(4)高速flash缓存fpga的处理结果,接着fpga将处理结构上传给pc端;
29.(5)pc端针对语音信息调取不同算法处理,并根据收敛效果,采取同类不同法算法处理。
30.上述描述仅是对本发明较佳实施例的描述,并非对本发明范围的任何限定,本发明领域的普通技术人员根据上述揭示内容做的任何变更、修饰,均属于权利要求书的保护范围。
再多了解一些
本文用于创业者技术爱好者查询,仅供学习研究,如用于商业用途,请联系技术所有人。