1.本公开涉及预测装置、预测方法以及程序。
背景技术:
2.以往,提出了一种在制造工艺中预测产物的质量或基于预测来进行动作的控制的技术。例如,提出了一种在制造工艺的制造中途预测产品的特性值,并基于该预测结果来计算后续工序的制造工艺的控制条件的预测系统(专利文献1)。本系统具备:数据库,储存按每个批次在制造工艺的工序中测定的数据和/或表示制造工艺的状态的数据;数式模型生成部,使用储存于数据库的数据来生成制造工艺的数式模型;产品特性预测部,对于制造中的批次,关于已处理的工序将实绩值输入数式模型,关于未处理工序将基于过去的批次而获得的代表值输入数式模型来预测产品的特性值;以及最优制造条件计算部,根据通过产品特性预测部得到的预测结果来计算未处理工序中的要控制的对象的工序的最优制造条件,该系统按每个规定的控制对象工序对制造中的批次实施通过产品特性预测部进行的预测和通过最优制造条件计算部进行的计算。
3.现有技术文献
4.专利文献
5.专利文献1:日本专利第6477423号公报
6.专利文献2:日本专利第5751045号公报
7.专利文献3:日本特开2018-120343号公报
8.专利文献4:日本特开2001-106703号公报
技术实现要素:
9.发明要解决的问题
10.然而,特别是在包括化学机组中的反应的工艺中,存在难以提高预测精度的问题。因此,本技术的目的在于,针对包括化学机组中的反应的工艺提高预测精度。
11.技术方案
12.本公开的预测装置具备:工艺数据加工部,对从化学机组获得的工艺数据进行规定的加工处理;以及预测模型生成部,生成基于因果关系信息对从化学机组获得的工艺数据的特征进行了学习的预测模型,其中,该因果关系信息对从化学机组获得的工艺数据或通过工艺数据加工部进行了加工的工艺数据中的作为说明变量的第一工艺数据与作为目的变量的第二工艺数据或与该第二工艺数据相应的值的组合进行定义。此外,工艺数据加工部使用工艺数据来求出与规定的期间内的处理对象的反应速度相应的值。
13.反应受温度等的影响,通常是非线性的,因此,例如难以基于工艺数据的峰值、差分值、积分值等来预测工艺数据的特征。与如上所述的反应速度相应的值例如是与每小时的反应量相关的说明变量。能通过使用与反应速度相应的值生成预测模型来针对包括化学机组中的反应的工艺提高预测精度。
14.此外,与反应速度相应的值也可以是反应速度的积分值。此外,也可以设为,与反应速度相应的值使用阿伦尼乌斯公式来计算,根据化学反应的类别和化学机组中的处理对象来决定反应速度常数的频率因子和活化能。具体而言,能采用这样的值。
15.此外,也可以设为,工艺数据加工部还根据工艺数据的类别来求出规定的期间内的工艺数据的积分值、微分值、平均值、最大值或最小值;或规定的时间点的工艺数据的瞬时值。能通过对工艺数据进行这样的加工来提高预测模型的预测精度。
16.此外,也可以是,预测模型是包括多个预测式的分级结构,具有将通过第一预测式计算出的预测值包括在说明变量中的第二预测式。例如,能如此通过函数表示多个因果关系。
17.此外,也可以设为,与第二工艺数据相应的值是通过缩分法对多个第二工艺数据进行采样而得到的值,预测模型生成部基于化学机组内的处理对象的停留时间,将化学机组中的第一工艺数据的获取定时的范围和与第二工艺数据相应的值的计算定时建立对应,生成预测模型。在化学机组中持续地对处理对象进行处理的情况下,能通过将作为说明变量的工艺数据的获取定时与作为目的变量的工艺数据的获取定时适当地建立对应来提高预测的精度。
18.此外,也可以设为,化学机组进行按每个规定的处理单位依次对处理对象进行处理的分批工序和之后连续地对处理对象进行处理的连续工序,预测模型生成部基于化学机组内的处理对象的停留时间,将分批工序的完成定时的范围和与第二工艺数据相应的值的计算定时建立对应,生成预测模型。在连续进行分批工序和连续工序的情况下,也能通过将作为说明变量的工艺数据与作为目的变量的工艺数据适当地建立对应来提高预测的精度。
19.需要说明的是,技术方案所述的内容可以在不脱离本公开的问题、技术思想的范围内尽可能地进行组合。此外,技术方案的内容可以作为计算机等装置或包括多个装置的系统、计算机所执行的方法或使计算机执行的程序而提供。需要说明的是,也可以设为提供保持程序的记录介质。
20.发明效果
21.根据公开的技术,能提高产物的特性值的预测精度。
附图说明
22.图1是表示实施方式的系统的一个例子的图。
23.图2是表示通过机组所具备的机器进行的工艺的一个例子的示意性的图。
24.图3是用于说明分批工序中的工艺数据的一个例子的图。
25.图4是表示预先登录到知识库的信息的一个例子的图。
26.图5是表示基于知识库而生成的分批工序的标签属性表的一个例子的图。
27.图6是表示基于知识库而生成的标签结合表的一个例子的图。
28.图7是表示预测模型的构成的逻辑树的一个例子的图。
29.图8是用于说明连续工序中的工艺数据的一个例子的图。
30.图9是用于说明连续工序的工序检查中的样本与分批工序中的生产编号建立对应的图。
31.图10是用于说明从连续工序中的传感器位置到工序检查中的采样位置为止的停
留时间的图。
32.图11是表示基于知识库而生成的连续工序的标签属性表的一个例子的图。
33.图12是表示预测模型的构成的逻辑树的一个例子的图。
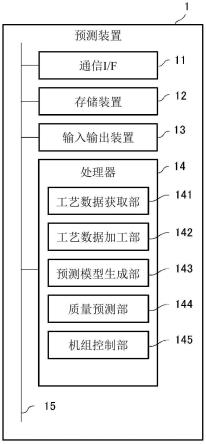
34.图13是表示预测装置的构成的一个例子的框图。
35.图14是表示预测装置所执行的预测处理的一个例子的处理流程图。
36.图15是表示分批工序用的写入用排列的一个例子的图。
37.图16是表示加工处理的一个例子的处理流程图。
38.图17是表示分批排列的一个例子的图。
39.图18是用于说明代入预测式的工艺数据或其预测值的图。
40.图19是表示用于说明代入预测式的工艺数据或其预测值的其他的例子的图。
41.图20是表示保持类别为“连续”的数据的写入用排列的一个例子的图。
42.图21是表示保持类别为“分批”的数据的写入用排列的一个例子的图。
43.图22是表示保持连续工序中的加工后的工艺数据的结合id数据排列的一个例子的图。
44.图23是表示预测装置所执行的控制处理的一个例子的处理流程图。
具体实施方式
45.以下,参照附图对预测装置的实施方式进行说明。
46.《实施方式》
47.图1是表示本实施方式的系统的一个例子的图。系统100包括:预测装置1、控制站2以及机组3。系统100例如是分散型控制系统(dcs:distributed control system),包括多个控制站2。即,机组3的控制系统分割为多个分区,各控制分区由控制站2分散控制。控制站2是dcs中的既存的设备,接收从机组3所具备的传感器等输出的状态信号或对机组3输出控制信号。然后,基于控制信号来控制机组3所具备的阀门等致动器、其他的机器。
48.预测装置1经由控制站2获取机组3的状态信号(工艺数据)。工艺数据包括作为原料、中间的产物的处理对象的温度、压力、流量等、决定机组3所具备的机器的运转条件的设定值等。此外,预测装置1生成基于存储所假定的原因与例如作为异常出现的影响的对应关系的知识库的预测模型。例如,使用对基于知识库而生成的作为说明变量的工艺数据(也称为主要原因系统)与作为目的变量的工艺数据(也称为影响系统)的组合进行定义的因果关系信息来生成质量、成本的预测式。然后,预测装置1能使用预测式和工艺数据来预测表示产物的质量等的特性值或预测变更了机组3的运转条件的情况下的产物的特性值。此外,也可以设为预测装置1例如求出质量和成本满足规定的条件的运转条件。此外,也可以设为预测装置1使用预测式和工艺数据,针对作为影响出现的状态的变化,求出用于向稳定状态转变的运转条件或求出产物满足规定的要求的运转条件。此外,预测装置1也可以将在规定的工序检查中获得的分析值作为目的变量来代替影响系统的工艺数据。
49.图2是表示机组所具备的机器或通过该机器进行的工艺的一个例子的示意性的图。即,设为工艺包括作为处理的生产工艺和作为装置的工艺机器。在本实施方式中,工艺可以包括分批工序31和连续工序32。在分批工序31中,按每个规定的处理单位依次对处理对象进行处理,例如按顺序进行对各机器的原料的接收、保持、排出这样的处理。在连续工
序32中,连续地对持续导入的处理对象进行处理,例如,并行进行原料的接收、保持、排出这样的处理。此外,工艺也可以包括并列进行同一处理的多个系列33。
50.进行各处理的机器例如包括反应器、蒸馏装置、热交换器、压缩机、泵、罐等,这些机器经由配管连接。此外,在机器、配管的规定的位置设有传感器、阀门等。传感器可以包括:温度计、流量计、压力计、水平计、浓度计等。此外,传感器监视各机器的运转状态,输出状态信号。此外,设为机组3所具备的传感器附加有作为用于确定各传感器的识别信息的“标签”。然后,预测装置1和控制站2基于标签来管理对各机器的输入输出信号。
51.《分批工序》
52.图3是用于说明分批工序中的工艺数据的一个例子的图。图3的左侧的列表示图2所示的分批工序31的工艺的一部分。具体而言,工艺包括:粉碎机301、旋流器302、预处理303、预冷机304以及反应机305。此外,这些工艺分为预处理工序、预冷工序、反应工序。图3的右侧的列表示在各工艺中获取的工艺数据的一个例子。在预处理工序中,从标签为001和002的传感器获取时序的数据。在预冷工序中,从标签为003和004的传感器获取时序的数据。在反应工序中,从标签为005、006以及007的传感器获取时序的数据。此外,在分批工序中,间歇地对与生产编号(也称为“产品编号”)建立了对应的处理对象进行处理。即,生产编号是用于识别在分批工序中集中处理的处理对象的识别信息。如图3所示,随着时间的经过,获得关于与后续的生产编号建立了对应的处理对象的时序的数据。需要说明的是,在后文对时间点t1和t2加以叙述。
53.图4是表示预先登录到知识库的信息的一个例子的图。设为知识库预先存储于预测装置1的存储装置。图4的表包括与各传感器对应的列和表示各传感器的输出值的变化的原因的行。即,在与因各行所示的“副原料a量上升”、“副原料a量降低”等原因而受影响的传感器对应的列登录有值。值附加与传感器的输出值的变动对应的正或负的符号地登录。需要说明的是,原因与影响的组合不限于一对一。即,对一个影响,也与多个原因建立对应,同一原因也与多个影响建立关联。
54.设为知识库例如由用户预先基于hazop(hazard and operability study:危险及可操作性研究)而生成。hazop例如是用于以下的方法:关于基于构成机组的仪器设备的监视点的感测单元、管理范围(是上下限的阈值、警报的设定点)、与管理范围的偏移(异常、调制)、发生与管理范围的偏移的假定原因的列举、判断由于哪个假定原因而发生了偏移的逻辑(感测单元)、由发生偏移导致的影响、在发生偏移的情况下采取的处理、针对该处理的动作,将这些建立关联并包罗地进行列举。需要说明的是,不限于hazop,也可以设为基于fta(fault tree analysis:故障树分析)、fmea(failure mode and effect analysis:失效模式及其影响分析)、eta(event tree analysis:事件树分析)或应用这些的方法、与这些类似的方法、从听取运营商的结果提取出的内容、从作业标准、技术标准提取出的内容来生成知识库。
55.图5是表示基于知识库而生成的分批工序的标签属性表的一个例子的图。标签属性表对从与各标签对应的传感器获得的数据的处理方法进行定义。需要说明的是,标签属性表可以是所谓的数据库的表,也可以是像csv(comma separated values:逗号分隔值)这样的规定的形式的文件。此外,标签属性表预先由用户生成,通过预测装置1读出。
56.标签属性表包括标签、系列、品种、一次加工、平滑化、运转条件最优化的各属性。
在标签的字段中登录作为传感器的识别信息的标签。在系列的字段中登录用于确定工艺的系列的识别信息。在品种的字段中登录处理对象的类别。也可以设为预测装置1在预测处理中例如设定与处理对象的品种相应的参数。在一次加工的字段中登录表示传感器的输出值的加工方法的信息。此外,一次加工的属性还包括分批工序、方法、数据区间的各属性。在分批工序的字段中登录表示分批工序中的细分化后的工序的识别信息。在方法的字段中登录表示数据的加工方法的类别的信息。类别包括:“瞬时值”、“平均”、“积分”、“微分”、“差分”、“最大”、“最小”、“热历史”、“无”。“瞬时值”表示通过数据区间指定的开始时或结束时的值。“平均”表示通过数据区间指定的期间的值除以数据的个数而得到的平均值。“积分”表示通过数据区间指定的期间的值的合计值。“微分”表示通过数据区间指定的开始时或结束时的微分系数。“差分”表示通过数据区间指定的开始时与结束时的值的差分。“最大”表示通过数据区间指定的期间内的最大值。“最小”表示通过数据区间指定的期间内的最小值。“热历史”是反应的进行的程度的一个例子,例如表示通过数据区间指定的期间内的反应速度的积分值。“无”附加于分批结束时的标签,表示不进行加工处理。数据区间的属性还包括开始和结束的属性,在开始和结束的字段中的至少一方中登录表示获取传感器的输出值的定时的信息。也可以设为表示定时的信息例如基于按每个细分化后的工序预先决定的规定的步骤来定义。在平滑化的字段中登录表示是否需要针对数据的规定的平滑化处理的实施的信息。运转条件最优化的属性还包括调整/监视、成本影响、管理范围、设定范围的各属性。在调整/监视的字段中登录表示在最优化处理中是作为调整的对象还是作为监视的对象的类别。在成本影响的字段中登录影响在最优化处理中进行调整的情况的每规定的单位的成本。管理范围的属性还包括上限和下限的属性,在上限和下限的字段中登录表示传感器的输出值的容许范围的信息。设定范围的属性还包括上限和下限的属性,在上限和下限的字段中登录表示作为传感器的输出值的目标的范围的信息。也可以设为预测装置1按照如上所述的登录到运转条件最优化的字段的信息来进行多目的最优化或单目的最优化。
57.图6是表示基于知识库而生成的标签结合表的一个例子的图。标签结合表是表示从知识库获得的因果关系的信息,对作为说明变量的工艺数据与作为目的变量的工艺数据的组合进行定义。标签结合表也可以是所谓的数据库的表,还可以是像csv这样的规定的形式的文件。此外,标签结合表也预先由用户生成,通过预测装置1读出。
58.标签结合表包括结合id、标签、主要原因/影响、因果关系、学习期间、从属关系的各属性。在结合id的字段中登录表示因果关系的集合的识别信息。在标签的字段中登录作为传感器的识别信息的标签。在主要原因/影响的字段中登录表示是因果关系中的主要原因系统还是影响系统(换言之,是说明变量还是目的变量)的类别。在因果关系的字段中登录表示为了使影响系统的值向正或负方向变动而应该使与该标签对应的主要原因系统的输出值变动的符号的限制的正或负的类别。因此,在主要原因/影响的字段中登录有“主要原因”的记录中登录因果关系的值。在本实施方式中,预测装置1以在主要原因系统的值的变动的正负的方向与影响系统的值的变动的正负的方向之间施加具有一定的对应关系的限制(称为“符号限制”)的方式生成预测模型。例如,以根据说明变量的正负的变动方向来决定目的变量的正负的变动方向的方式生成预测模型。即,登录到因果关系的字段的符号表示为了使影响系统的值向正或负中的规定的方向变动,只要使与该记录的标签对应的传感器的输出值向正或负中的哪一方向变动即可。此外,在学习期间的字段中登录用于确定
用于生成预测模型的工艺数据的期间的信息。该信息例如可以是最近的生产编号的个数。
59.预测装置1基于如上所述的标签属性表和标签结合表来生成预测模型。图7是表示预测模型的构成的逻辑树的一个例子的图。各矩形表示与标签对应的传感器的输出值或预测值。预测模型包括用于基于上游(在图7中为左侧)的工序中的传感器的输出值来预测通过箭头连接的目的地的对应于影响系统的传感器的输出值的预测式。此外,预测模型为包括多个预测式的分级结构,包括将由某个预测式得到的预测值包括在说明变量中的其他的预测式。将在图6所示的标签结合表中附加有同一结合id的记录组合来生成预测式。例如,将与在主要原因/影响的字段中登录有“主要原因”的标签对应的传感器的输出值或其预测值作为说明变量,将与在主要原因/影响的字段中登录有“影响”的标签对应的传感器的输出值、例如作为通过工序检查获得的分析值的产物的特性值作为目的变量来生成规定的预测式。
60.具体而言,预测式例如能通过如下所示的算式(1)来表示。
61.y(t)=a1(t)
·
x1(t) a2(t)
·
x2(t)
……
an(t)
·
xn(t) a
ar
(t)
·
y(t-1) c
ꢀꢀ
(1)
62.需要说明的是,t为与生产编号相应的值,y(t)为影响系统的预测值,x(t)为主要原因系统的传感器的输出值或其预测值,a(t)为主要原因系统的系数,a
ar
(t)为自回归项的系数,c为常数项。与主要原因系统对应的项仅包括在图7中通过箭头连接的源传感器的输出值的数。此外,自回归项是过去的生产编号的预测值或实测值。自回归项不限定于一个,预测式也可以包括最近的多个生产编号的自回归项。
63.此外,预测装置1在分批工序中按每个生产编号进行学习处理,对预测式的系数等进行更新。系数例如将设定于图6的学习期间的字段的与最近的规定数的生产编号对应的工艺数据作为学习数据,进行回归分析来决定。此时,设为以满足上述的符号限制的方式决定系数。
64.《连续工序》
65.图8是用于说明连续工序中的工艺数据的一个例子的图。图8的左侧的列表示图2所示的连续工序32的工艺的一部分。具体而言,工艺包括罐311和泵312。图8的右侧的列表示在各工艺中获取的工艺数据的一个例子。在连续工序32中,从传感器持续获取与标签建立对应、未与生产编号建立对应的时序的数据。在图8的例子中,从标签为102和103的各传感器获取时序的数据。在连续工序中,机器连续地接受处理对象,持续地进行处理。在分批工序后进行连续工序的情况下,使用在本实施方式中预先由用户设定的追溯信息来将分批工序中的处理对象与连续工序中的处理对象建立关联。追溯信息包括采样间隔和停留时间。采样间隔表示在连续工序中例如进行通过缩分法进行的用于工序检查的采样的间隔。停留时间表示从分批工序的完成开始至到达连续工序中所包括的工艺为止处理对象所停留的时间。
66.图9是用于说明连续工序的工序检查中的样本与分批工序中的生产编号建立对应的图。例如,工序检查以规定的间隔来进行,工序检查中的样本作为相当于该间隔的期间的缩分样本。此外,在分批工序后进行连续工序的情况下,通过在规定的期间完成的分批工序得到的产物作为连续工序的处理对象而被导入。因此,连续工序中的工艺数据的缩分样本能通过追溯到采样时间点为止的停留时间,与分批工序的完成时刻的范围建立关联来确定对应的分批工序的生产编号组。能通过这样的建立关联,在连续实施分批工序和连续工序
的情况下,提高利用分批工序中的工艺数据的预测式的精度。
67.图10是用于说明从连续工序中的传感器位置到工序检查中的采样位置为止的停留时间的图。上述的缩分样本例如计算为在连续工序中获得的工艺数据的规定期间的平均值。为了将进行该运算的采样时间点与在该时间点进行平均的工艺数据的获取时间点的范围建立对应,在本实施方式中,针对在连续工序中输出工艺数据的传感器的位置与进行用于工序检查的采样的位置的间隔来设定该区间的停留时间。由此,能将连续工序中的工艺数据与工序检查的缩分样本建立关联。能通过这样的建立关联来提高利用连续工序中的工艺数据的预测式的精度。
68.图11是表示基于知识库而生成的连续工序的标签属性表的一个例子的图。连续工序的标签属性表也可以是所谓的数据库的表,还可以是像csv这样的规定的形式的文件。此外,标签属性表预先由用户生成,通过预测装置1读出。
69.连续工序的标签属性表包括标签、类别、停留时间、分批关联标签、运转条件最优化的各属性。需要说明的是,对于与图5所示的分批工序的标签属性表名称相同的属性省略其说明。在类别的字段中登录连续、分批或质量的类别。类别中的“连续”表示各记录所示的标签为连续工序中的工艺数据。“分批”表示为分批工序中的工艺数据。“质量”表示为工序检查中的缩分样本的分析值。
70.此外,在连续工序中,预测装置1也利用如图6所示的标签结合表,基于标签属性表和标签结合表来生成预测模型。图12是表示预测模型的构成的逻辑树的一个例子的图。在图12中,各矩形也表示与标签对应的传感器的输出值或预测值。标签为101的矩形表示分批工序的工艺数据。如使用图9进行了说明的那样,分批工序的工艺数据基于停留时间来确定对应的生产编号和系列,将这些平均值用作预测式的说明变量。标签为102和103的矩形表示连续工序的工艺数据。如使用图10进行了说明的那样,连续工序的工艺数据基于停留时间和采样间隔来确定对应的期间,将期间内的工艺数据的平均值用作预测式的说明变量。标签为104的矩形是工序检查(也称为质量工序)的分析值,例如是与通过缩分法求出的工艺数据相应的值。在连续工序中,也将在图6所示的标签结合表中附加有同一结合id的记录组合来生成预测式。预测式与分批工序相同,因此省略其说明。
71.在本实施方式中,使用基于知识库而选出的工艺数据,因此,能根据因果关系明确的参数高速地生成预测模型,而无需整个机组的庞大的参数。此外,如果生成包括自回归项的预测模型,则能进行考虑到仅通过根据某个时间点的工艺数据进行模拟无法反映的工艺数据的经时性的变化的预测。
72.此外,在没有如上所述的符号限制的情况下,使用预测模型来解决逆问题的情况下,有时无法获得适当的结果。即,在指定要求的质量来求出与之相应的运转条件的情况下,可能会生成输出违反工艺的原理原则的结果的预测模型。能通过施加如上所述的符号限制来生成按照工艺的原理原则的预测模型。即,通过使用满足符号限制的预测式,不仅能预测作为产物的代替指标的影响系统的值,而且容易知道如何变更机组的运转条件来改善质量即可。
73.《控制》
74.也可以设为预测装置1使用所生成的预测式和工艺数据,针对作为影响出现的状态的变化,求出用于向稳定状态转变的运转条件或求出产物满足规定的要求的运转条件,
processing unit:中央处理器)等运算处理装置,通过执行程序来进行本实施方式的各处理。在图13的例子中,在处理器14内示出功能块。即,处理器14通过执行规定的程序来作为工艺数据获取部141、工艺数据加工部142、预测模型生成部143、质量预测部144以及机组控制部145发挥功能。
84.工艺数据获取部141例如经由通信i/f11和控制站2从机组3所具备的传感器获取工艺数据,存储于存储装置12。如上所述,工艺数据通过标签与传感器建立有对应。
85.工艺数据加工部142在预测模型的生成时,基于图5所示的分批工序的标签属性表或图11所示的连续工序的标签属性表,对工艺数据进行加工。即,工艺数据加工部142基于登录到分批工序的标签属性表的一次工序的字段的信息来提取指定定时的瞬时值,或计算出指定期间的平均值,或计算出指定期间的积分值。此外,工艺数据加工部142也可以基于登录到连续工序的标签属性表的分批关联标签的字段的信息和例如预先保持在存储装置12中的上述的追溯信息来计算出相当于规定的标签、系统以及生产编号的工艺数据的平均值,或针对连续工序的工艺数据计算出基于追溯信息而确定的期间的平均值。
86.预测模型生成部143例如基于图6所示的标签结合表来生成包括如上述的算式(1)所示的预测式的预测模型,存储于存储装置12。预测模型生成部143例如也可以在分批工序中按每个生产编号使用最近的规定期间的数据来更新预测式的系数等。此外,预测模型生成部143例如也可以在连续工序中按每个规定期间使用最近的数据来更新预测式的系数等。
87.质量预测部144使用工艺数据和预测模型来预测规定的传感器的输出值、工序检查的分析值。需要说明的是,质量预测部144也可以使用基于任意的运转条件的数据和预测模型来计算出运转条件变更后的预测值。
88.机组控制部145例如经由通信i/f11和控制站2来控制机组3所具备的阀门等致动器、其他的机器。此外,机组控制部145例如也可以求出质量和成本满足规定的条件的运转条件,并基于此来控制机组3。此外,机组控制部145也可以求出用于转变至规定的稳定状态的运转条件,或求出产物满足规定的要求的运转条件,并基于此来控制机组3。
89.如上所述的构成要素经由总线15连接。
90.《预测处理(分批工序)》
91.图14是表示预测装置1所执行的预测处理的一个例子的处理流程图。预测装置1的处理器14通过执行规定的程序来执行如图14所示的处理。预测处理在分批工序中按每个生产编号执行,在连续工序中以规定的采样间隔执行。需要说明的是,设为由用户生成图5所示的分批工序的标签属性表、图6所示的标签结合表、图11所示的连续工序的标签属性表、追溯信息等,预先存储于存储装置12。此外,工艺数据获取部141例如经由通信i/f11和控制站2从机组3所具备的传感器持续地获取工艺数据,暂时地或永久地存储于存储装置12。工艺数据例如按照像opc这样的规定的规格来记述。
92.预测装置1的工艺数据获取部141读入设定信息(图14:s1)。在本步骤中,工艺数据获取部141从存储装置12读出标签属性表、标签结合表、追溯信息等。
93.此外,工艺数据获取部141读入工艺数据(图14:s2)。在本步骤中,与用于预测式的标签对应的工艺数据例如按每个预测式且按每个系列且按每个细分化后的工序来提取。图15是表示用于写入在本步骤中读出的数据的分批工序用的写入用排列的一个例子的图。分
批工序用的写入用排列可以是opc数据,也可以是所谓的数据库的表,还可以是像csv这样的规定的形式的文件。图15的表包括日期和时间、产品编号、品种、步骤、标签的各属性。在日期和时间的字段中登录传感器输出测定值的日期和时间。在产品编号的字段中登录生产编号。在品种的字段中登录处理对象的类别。在步骤的字段中登录表示由预先定义出的步骤表示的该工序中的阶段的信息。在标签的字段中登录与各标签对应的传感器的输出值。
94.此外,预测装置1的工艺数据加工部142对工艺数据进行规定的加工处理(图14:s3)。使用图16来说明本步骤的详细内容。图16是表示加工处理的一个例子的处理流程图。工艺数据加工部142在图15所示的写入用排列中提取按每个预测式且按每个系列且按细分化后的工序的工艺数据时,对写入用排列的各记录执行如图16所示的处理。
95.工艺数据加工部142从写入用排列读出记录(图16:s11)。在本步骤中,从如图15所示的表按顺序读出一条记录。此外,工艺数据加工部142根据一次加工方法来进行数据的加工(图16:s12)。在本步骤中,参照图5所示的标签属性表,基于登录到对应的标签的“一次加工”的“方法”的字段的类别,例如求出瞬时值、平均值、积分值、微分系数、差分、最大值、最小值、热历史或工艺数据本身。图17是表示写入本步骤的处理结果的分批排列的一个例子的图。分批排列也可以是opc数据,也可以是所谓的数据库的表,还可以是像csv这样的规定的形式的文件。图17的表包括产品编号、结束日期和时间、标签的各属性。在产品编号的字段中登录生产编号。在结束日期和时间的字段中登录该产品编号的分批工序结束的日期和时间。在标签的字段中登录加工处理后的工艺数据。
96.在此,对热历史的计算进行说明。热历史例如是针对解聚、乙酰化、脱乙酰化等一般的化学反应表示反应的进行的程度的信息。在本实施方式中,求出热历史,作为规定的期间的反应速度的积分值。例如,如以下算式(2)所示,根据使用了阿伦尼乌斯公式的反应速度式的积分值进行计算。
97.[数式1]
[0098][0099]
在此,a为频率因子。e为活化能。r为气体常数。此外,a(t)、b(t)为浓度项,m、n为反应次数。这些值根据反应、对象物来定义。此外,t是表示工序中的规定的区间的步骤。t(t)为该步骤中的温度,作为工艺数据而获得。能通过这样的加工,将在规定期间处理对象所受的热量用于质量预测。
[0100]
此外,工艺数据加工部142实施规定的数据清理处理(图16:s13)。数据清理处理是排除偏离值的处理,能采用各种方法。例如,使用最近的数据计算出移动平均值。此外,取移动平均值与实测值之差,求出表示差分的不均的标准偏差σ(也称为误差方差)。然后,例如排除不落入从概率分布的平均值-3σ到概率分布的平均 3σ为止的区间(也称为3σ区间)这样的规定的可靠区间的值。同样,也可以设为针对前后的实测值的差排除不落入3σ区间的值。数据清理处理例如对瞬时值、分批结束时的工艺数据进行。
[0101]
此外,工艺数据加工部142实施规定的平滑化处理(图16:s14)。平滑化处理针对在图5所示的标签属性表中在平滑化的字段中登录有“需要”的标签来进行。此外,平滑化处理例如也可以是针对数据清理后的值求出最近的规定数的移动平均的处理,还可以是能将数据平滑化的其他的方法。以上,结束图16的加工处理,返回图14的处理。
[0102]
然后,预测装置1的预测模型生成部143进行预测模型构建处理(图14:s4)。在本步骤中,基于图6所示的标签结合表来生成构成预测模型的预测式。具体而言,读出附加有同一结合id的标签的加工后的工艺数据,基于登录到主要原因/影响的字段的类别将加工后的工艺数据代入预测式(例如上述的算式(1)),通过回归分析决定预测式的系数和常数项。此时,加工后的工艺数据根据登录到学习期间的字段的值,将最近的数据作为学习对象。需要说明的是,也可以设为预测模型生成部143也针对学习期间的大小搜索优选的值。例如,使用所生成的预测模型和工艺数据计算出相关系数,以提高相关系数的方式设定学习期间。此外,基于登录到因果关系的字段的符号,在主要原因系统的值的变动的方向与影响系统的值的变动的方向之间具有一定的对应关系这样的限制下,决定预测式的系数等。然后,预测模型生成部143使所生成的预测式存储于存储装置12。
[0103]
预测装置1的质量预测部144使用在预测模型构建处理中生成的预测模型和工艺数据或其预测值来进行预测处理(图14:s5)。为方便起见,在图14的处理流程中示出预测处理,但是,质量预测部144能在任意的时间点使用预测模型和工艺数据来进行预测处理。在本步骤中,质量预测部144读出最近的预测模型和工艺数据,将工艺数据或其预测值代入预测模型中所包括的预测式,求出与任意的影响系统相应的值的预测值。
[0104]
图18是用于说明代入预测式的工艺数据或其预测值的图。在预测图4所示的标签007的值的情况下,如图18所示,在图3的时间点t1,使用与各标签对应的传感器的实测值或预测值。即,在预测生产编号003的标签007的值的情况下,将已知的生产编号003的标签001~004的实测值和未知的生产编号003的标签005和006的预测值代入标签007的预测式。
[0105]
图19是表示用于说明代入预测式的工艺数据或其预测值的其他的例子的图。在预测图4所示的标签007的值的情况下,如图19所示,在图3的时间点t2,使用与各标签对应的传感器的实测值或预测值。即,在预测生产编号004的标签007的值的情况下,将已知的生产编号004的标签001和002的实测值和未知的生产编号004的标签003、005以及006的预测值代入标签007的预测式。在此,如图4所示,标签004的值中没有预测式,因此使用最近的生产编号的实测值。
[0106]
此外,输入预测模型的值不限于工艺数据,例如,也可以是基于任意的运转条件的数据。若如此,则能预测变更了机组3的运转条件的情况下的结果。如上所述,质量预测部144使用预测模型和传感器的输出值或其预测值,例如计算出规定的工艺数据的预测值。
[0107]
此外,也可以是质量预测部144针对计算出的预测值或工艺数据的实测值,求出在上述的数据清理中求出的规定的可靠区间,使监视器等输入输出装置13将规定的可靠区间和预测值或实测值图示在图表上。若如此,则用户能视觉上掌握倾向,能作为是否应该变更机组3的运转条件的判断材料。
[0108]
此外,机组控制部145也可以基于计算出的预测值自动地变更机组3的运转条件,或经由输入输出装置13输出对用户提出运转条件的变更的信息。
[0109]
《预测处理(连续工序)》
[0110]
在连续工序中,也进行图14所示的预测处理。以下,以与分批工序的不同点为中心进行说明。需要说明的是,设为按每个系列且按每个生产编号结束分批工序,向连续工序的处理对象的移送(移液)完成的日期和时间存储于存储装置12。
[0111]
在工艺数据的读入(图14:s2)中,在连续工序的情况下,不以生产编号为单位,持
续地进行随着写入新的数据删除旧的数据的滚动。此外,也可以基于登录到图11所示的标签属性表的类别的字段的信息来变更图15所示的写入用排列的数据结构。图20是表示保持类别为“连续”的数据的写入用排列的一个例子的图。保持类别为“连续”的数据的写入用排列例如能采用从图15的表中删除产品编号和步骤的构成。此外,图21是表示保持类别为“分批”的数据的写入用排列的一个例子的图。保持类别为“分批”的数据的写入用排列例如是保持生产编号和该生产编号的工艺数据的表,按每个系统生成如图21所示的表。登录到图21的表的数据也可以是登录到图17的分批排列的加工后的数据。
[0112]
此外,工艺数据的加工(图14:s3)例如以工序检查的定时为基准来执行。工序检查的定时在追溯信息中定义为采样间隔。图22是表示保持连续工序中的加工后的工艺数据的结合id数据排列的一个例子的图。结合id数据排列也可以是opc数据,也可以是所谓的数据库的表,还可以是像csv这样的规定的形式的文件。图22的表在包括工序检查id、采样、标签的各属性的工序检查id的字段中登录用于确定各工序检查的识别信息。采样的属性还包括开始日期和时间以及结束日期和时间的属性,在开始日期和时间以及结束日期和时间的字段中分别登录通过缩分法进行的工序检查的采样的开始日期和时间以及结束日期和时间。在标签的字段中登录与各标签对应的分析值。在此,针对在图11所示的标签属性表的类别的字段中登录有“连续”的标签,登录从处理时间点到在追溯信息中追溯采样间隔的时间点为止的工艺数据的平均值。此外,针对在如图11所示的标签属性表的类别的字段中登录有“分批”的标签,登录与从处理时间点到在追溯信息中追溯采样间隔的时间点为止完成移液的生产编号对应的工艺数据的平均值。
[0113]
此外,预测模型构建处理(图14:s4)例如在预测模型生成部143获取工序检查的分析值时,更新该分析值的预测模型。在本步骤中,也基于图6所示的标签结合表来生成构成预测模型的预测式。此外,在连续工序中,也可以如图9所示设为,预测模型生成部143基于分批工序的完成定时和预先决定的停留时间,将主要原因系统的工艺数据与影响系统的工艺数据建立对应,学习从机组3获得的工艺数据的特征。此外,也可以如图10所示设为,预测模型生成部143基于主要原因系统的工艺数据的获取定时与影响系统的工艺数据的获取定时的差,将主要原因系统的工艺数据与影响系统的工艺数据建立对应,学习从机组3获得的工艺数据的特征。
[0114]
预测装置1的质量预测部144使用在预测模型构建处理中生成的预测模型和工艺数据或其预测值来进行预测处理(图14:s5)。在本步骤中,质量预测部144读出最近的预测模型和工艺数据,将工艺数据或其预测值代入预测模型中所包括的预测式,求出与任意的影响系统相应的值的预测值。
[0115]
《控制处理》
[0116]
图23是表示预测装置1所执行的控制处理的一个例子的处理流程图。预测装置1的处理器14通过执行规定的程序来执行如图23所示的处理。控制处理例如在更新预测模型之后等任意的定时执行。在控制处理中,也设为图5所示的分批工序的标签属性表、图6所示的标签结合表、图11所示的连续工序的标签属性表、追溯信息等预先存储于存储装置12。此外,工艺数据获取部141例如经由通信i/f11和控制站2从机组3所具备的传感器持续地获取工艺数据,暂时地或永久地存储于存储装置12。
[0117]
预测装置1的机组控制部145读入设定信息(图23:s21)。在本步骤中,机组控制部
145从存储装置12读出标签属性表、标签结合表、追溯信息等。在控制处理中,所读出的信息包括例如表示为最优化问题的目的函数的控制的目标、例如表示为最优化问题的限制条件的控制的容许区域。在此,设为将使用登录到图5的成本影响的字段的单价计算出的成本成为最小作为目的函数。此外,设为登录到管理范围和设定范围的字段的值成为限制条件。
[0118]
此外,工艺数据获取部141读入工艺数据(图23:s22)。本步骤的处理与图14的s2相同。在本步骤中,与用于预测式的标签对应的工艺数据例如按每个预测式且按每个系列且按每个细分化后的工序来提取工艺数据。此外,在图15或图20所示的写入用排列中登录传感器的输出值。
[0119]
此外,工艺数据加工部142对工艺数据进行规定的加工处理(图23:s23)。本步骤的处理与图14的s3相同。
[0120]
然后,机组控制部145进行最优化问题的运算处理(图23:s24)。在本步骤中,在所读出的限制条件下求出将目的函数最小化或最大化的运转条件。例如,在基于图5所示的设定将成本最小化的情况下,通过如下的算式(3)求出成本。
[0121]
成本=(标签001的工艺数据
×
单价) (标签002的工艺数据
×
单价) (标签004的工艺数据
×
单价)(3)
[0122]
此外,利用登录到图5的“设定范围”的信息,作为限制条件。具体而言,设定如下所示的条件。
[0123]
标签005的下限≤标签005的预测值≤标签005的上限
[0124]
标签007的下限≤标签007的预测值≤标签007的上限
[0125]
此外,利用登录到图5的“管理范围”的信息,作为其他限制条件。具体而言,设定如下所示的条件。
[0126]
标签001的下限≤标签001的值≤标签001的上限
[0127]
标签002的下限≤标签002的值≤标签002的上限
[0128]
标签003的下限≤标签003的值≤标签003的上限
[0129]
标签005的下限≤标签005的值≤标签005的上限
[0130]
此外,在本实施方式中,在预测处理中生成的预测模型也用于限制条件。例如,在如图7和图12所示的逻辑树中在工艺数据间对预测式进行了定义的情况下,基于在预测处理中构建的预测式,基于上游的工艺数据来计算出下游的工艺数据。此外,在s22中获取作为位于上游侧的端部的工艺且与在图5的“调整/监视”的字段中登录有“监视”的标签对应的工艺数据,在s23中使用加工后的值。然后,在针对各预测式中的目的变量设定了上述的设定范围、管理范围的情况下,设置表示这些范围的限制条件,搜索预测值落入该限制条件的范围的说明变量的最优值。
[0131]
如上所述的最优化问题能通过既存的解法来解决。需要说明的是,将与在图5的“调整/监视”中登录有“调整”的标签对应的工艺数据作为调整对象。即,标签为001、003、004、006的工艺数据为调整对象,对象的标签不一定与限制条件一致。
[0132]
在解决最优化问题,求出包括调整对象的工艺数据的设定值的运转条件时,机组控制部145按照运转条件来控制机组3(图23:s25)。在本步骤中,机组控制部145经由通信i/f11向控制站2输出表示运转条件的数据。然后,按照来自控制站2的控制信号来控制机组3的动作。需要说明的是,例如也可以在s24中解决了多目的最优化问题的情况下,将运转条
件的多个候选经由输入输出装置13提示给用户,基于用户所选出的运转条件来控制机组3。
[0133]
《变形例》
[0134]
需要说明的是,各实施方式中的各构成及它们的组合等是一个例子,在不脱离本发明的主旨的范围内,可以适当地进行构成的附加、省略、置换以及其他变更。本公开不由实施方式限定,仅由权利要求书限定。此外,本说明书所公开的各种方案可以与本说明书所公开的其他的任意特征组合。
[0135]
此外,在上述的实施方式中以化学机组为例进行了说明,但也能应用于一般的生产设备中的制造工艺。例如,能将批次编号代替实施方式中的分批工序的生产编号作为处理单位,应用按照实施方式中的分批工序的处理。
[0136]
也可以设为预测装置1的功能的至少一部分分散至多个装置来实现,也可以设为由多个装置并行提供同一功能。例如,生成预测模型的模型生成装置、使用所生成的预测模型来进行预测的预测装置以及使用所生成的预测模型来进行生产设备的控制的控制装置也可以不同。此外,也可以设为预测装置3的功能的至少一部分设于所谓的云端上。
[0137]
此外,上述的算式(1)为包括自回归项的线性模型,但不限定于这样的例子。例如,也能采用不包括自回归项的模型。此外,模型可以为线性也可以为非线性。此外,可以为单个的算式,例如也可以采用导入了季节变动这样的周期性的变动的状态空间模型。不过,优选的是满足符号限制的模型。即,在主要原因系统的值的变动的方向与影响系统的值的变动的方向之间具有一定的对应关系这样的限制下,决定预测式的系数等。
[0138]
此外,本公开包括执行上述的处理的方法、计算机程序、记录有该程序的计算机可读记录介质。记录有该程序的记录介质能通过使计算机执行程序来进行上述的处理。
[0139]
在此,计算机可读记录介质是指能通过电、磁、光学、机械或化学的作用累积数据、程序等信息,并从计算机读取的记录介质。作为这样的记录介质中能从计算机取下的记录介质,有软盘、磁光盘、光盘、磁带、存储卡等。此外,作为固定于计算机的记录介质,有hdd、ssd(solid state drive)、rom等。
[0140]
附图标记说明
[0141]
1:预测装置
[0142]
11:通信i/f
[0143]
12:存储装置
[0144]
13:输入输出装置
[0145]
14:处理器
[0146]
141:工艺数据获取部
[0147]
142:工艺数据加工部
[0148]
143:预测模型生成部
[0149]
144:质量预测部
[0150]
145:机组控制部
[0151]
2:控制站
[0152]
3:机组
再多了解一些
本文用于企业家、创业者技术爱好者查询,结果仅供参考。