1.本发明涉及疾病风险评估技术领域,尤其涉及一种基于肠道微生物的疾病风险评估模型构建方法及应用。
背景技术:
2.肠道是人体最大的微生态系统,栖息着总数约10的14次方、1000-2000余种、重量约为1-2公斤的微生物。这些肠道微生物编码基因的总数超过330万,约为人类编码基因总数的100倍。肠道微生物基因组与人体基因组一起,与环境因素的相互作用,通过不同方式影响我们的健康,被认为是人体的第二基因组。
3.肠道微生物与慢性疾病的关系一直是人们关注的话题,但长期以来人们缺乏深入的理解和科学论证。近年来,随着高通量测序和宏基因组学等新的研究方法的不断开发和应用,肠道微生物对人体健康的影响逐渐受到重视并取得了大量实质性的进展,越来越多的肠道微生物与慢性疾病(如肥胖、炎症性肠病、心血管疾病、阿尔兹海默症、糖尿病等)的关联关系通过实验等方式被验证和发表。这些都为通过肠道微生物结构的变化预测疾病的发病风险提供了理论基础。
4.基于肠道微生物进行疾病风险预测,为诸多慢性疾病的早期发现和治疗干预提供了强有力的技术手段。但目前这项技术手段并不成熟,在不同的研究项目中呈现出不同甚至相悖的结论,除了因年龄、地域、饮食等因素造成的个体间肠道微生物差异较大等不可控因素外,研究人群的零散小众化及研究方法的粗浅不规范等因素也是极大的阻碍,亟需从方法学上进行优化。
5.现有技术提供了多种基于粪便微生物进行疾病风险评估的技术方案。例如,专利文献cn113380396a公开了一种基于粪便微生物标志物和人dna含量的多种肠道疾病风险评估的方法及应用,包括常见肠道相关细菌信息的收集、数据预处理、粪便人类dna鉴定、肠病相关菌群与相关通路丰度鉴定、机器学习模型的建立、真实样本应用。鉴定到的标志物菌群与通路,结合人类粪便dna含量,增加了分类模型的全面性;利用多个数据集通过meta分析,可以减小背景噪音和其他因素的影响,得到更加稳定结果;同时考虑多种常见肠道疾病,挖掘其可能的致病机制,可避免因其有相似表型而误诊的可能;根据实际需求,根据不同目的建立了不同的机器分类器,便于使用者根据自己的需求使用或进一步验证。然而,该发明直接使用样本组间秩和检验差异(fdr<0.05)的菌群及代谢通路等作为机器学习模型的特征,在特征选取方法上存在不合理性。相比之下,本发明的随机森林算法的平均精度下降和基尼指数两个指标可以更加有效的评估特征权重。另外,上述菌群和代谢通路丰度由于没有采用等距对数比进行转化,使得构建模型中存在的数据误差较大,因此最终得到的预测模型的预测结果的误差较大。
6.例如,专利文献cn107506582a公开了一种基于肠道微生物的健康风险预测系统,所述系统包括标本信息接收功能模块、高通量测序分析数据的接收和管理模块、肠道微生物信息管理模块、以及报告系统主界面。该系统能够建立全新的质量管理体系,以质控数据
的自动化、信息化、网络化、智能化管理为核心,实现对肠道微生物菌群及功能的检测、解读工作的科学、规范、高效的管理,通过肠道微生物组数据信息评估人体的健康状况。然而,该发明未详细描述其构建健康风险预测模型的方法,同时相比于宏基因组测序,16s rdna测序技术存在菌种分辨率低、覆盖面窄等缺陷,其结果用于风险预测准确性较低。
7.如上所示,现有技术中公开的健康风险预测系统或模型,都没有涉及肠道微生物的宏基因组测序数据,也没有通过等距log-ratio和机器学习等算法对数据集进行标准化处理、数据挖掘和建模等得到疾病风险评估模型。基于现有技术的空白,本发明希望提供一种疾病风险的预测准确度较高的评估模型的构建方法及应用。
8.此外,一方面由于对本领域技术人员的理解存在差异;另一方面由于申请人做出本发明时研究了大量文献和专利,但篇幅所限并未详细罗列所有的细节与内容,然而这绝非本发明不具备这些现有技术的特征,相反本发明已经具备现有技术的所有特征,而且申请人保留在背景技术中增加相关现有技术之叔利。
技术实现要素:
9.现有技术中,在进行疾病风险评估时,直接使用样本组间秩和检验差异(fdr<0.05)的菌群和代谢通路等作为机器学习模型的特征,在特征选取方法上存在不合理性。相比之下,随机森林方法的平均精度下降和基尼指数两个指标可以更加有效的评估特征权重。其中的菌群和代谢通路丰度由于没有采用等距对数比进行转化,使得构建模型中存在的数据误差较大,因此最终得到的预测模型的预测结果的误差较大。现有技术的相关的技术方案中,采用16s rdna测序技术,相比于宏基因组测序,16s rdna测序技术存在菌种分辨率低、覆盖面窄等缺陷,其结果用于风险预测准确性较低。
10.基于需要技术的缺陷,本发明基于收集疾病和健康人群肠道微生物的宏基因组测序数据,通过等距log-ratio、机器学习和十折交叉验证等算法对数据集进行标准化处理、数据挖掘和建模等,构建了一套基于肠道微生物的疾病风险预测的方法和系统,在疾病风险预测准确性上有了较大的提升,可以用于多种慢性疾病的发病风险提示和健康监测。
11.本发明提供了一种基于肠道微生物的疾病风险评估模型构建方法,所述方法至少包括:对样本测序数据进行质控和预处理;
12.构建微生物种水平的相对丰度矩阵并提取特征矩阵;
13.基于分类列和所述特征矩阵构建第一训练矩阵并且进行数据集训练;
14.筛选所述第一训练矩阵中的若干最优特征列和样本分类列以构建第二训练矩阵;对所述第二训练矩阵进行数据集训练并基于训练结果构建风险评估模型。
15.本发明中,通过将微生物种水平的丰度信息构建为相对丰度矩阵并且提取特征矩阵,形成了对丰度数据信息的特征过滤,减少了由于特征较多导致的过拟合问题。本发明还通过特征过滤对最优特征列进行筛选,减少了对于样本分类起到作用的权特征重较小的特征,同时保留了对于样本分类起到作用的特征权重较大的特征,从而使得对预测效果影响较大的特征因素得以保留。本发明还对第二训练矩阵再次进行训练,通过再一次调整参数的方式使得风险评估模型的精度进一步提高。因此,本发明相对于现有技术中的疾病风险预测模型的准确度更高。
16.优选地,构建微生物种水平的相对丰度矩阵并提取特征矩阵的步骤至少包括:筛
选样本微生物种水平的相对丰度信息并合并形成所述相对丰度矩阵,对所述相对丰度矩阵进行特征过滤;
17.基于等距log-ratio转化公式对所述相对丰度矩阵中的特征值进行转化并形成样本特征矩阵。
18.优选地,所述相对丰度矩阵进行转化的方式至少包括:
19.采用较小的正数值替换所述相对丰度矩阵中的0值;
20.选定一组标准正交基,得到相应的等距log-ratio转化公式;
21.将所述相对丰度矩阵代入所述等距log-ratio转化公式进行转化并形成样本特征矩阵。
22.优选地,所述等距log-ratio转化公式为:
23.对于任意的i=1,2,3,
…
,n-1,转化值n为相对丰度矩阵的特征数量,ai表示第i个特征值,g(a1,a2,a3,
…ai
)表示a1,a2,a3,
…ai
的几何平均数,
24.公式转化形成的所述样本特征矩阵为m*(n-1)矩阵,转化后的特征名称采用ni/n
i 1
替换,其中ni表示所述相对丰度矩阵的第i个特征的名称。
25.本发明通过等距log-ratio转化公式处理相对丰度矩阵,其优势在于,不会改变数据的性质和相关关系,但压缩了变量的尺度,减弱了模型的共线性和易方差性,因此使得相对丰度矩阵标准化,准确度更高,有效性更强。
26.优选地,基于分类列和所述特征矩阵构建第一训练矩阵并且进行数据集训练的步骤至少包括:基于样本分组信息和所述样本特征矩阵的特征列构建第一训练矩阵,第一训练矩阵为m*n矩阵;将随机森林算法代入第一训练矩阵并且基于测试集进行训练和/或测试,在训练参数循环变化的情况下,选择与测试准确性最高对应的第一训练矩阵的参数值为第一有效参数。
27.通过第一次的数据训练形成的训练模型采纳了特征矩阵的全部特征,导致模型的泛化能力不足,实际使用会存在过拟合的问题,需要根据重要性对特征进行进一步筛选。
28.优选地,筛选所述第一训练矩阵中的若干最优特征列和样本分类列以构建第二训练矩阵的步骤包括:
29.将第一训练矩阵中的特征列基于平均进度下降指标按照由高到低的顺序进行重要性排序;对所述第一训练矩阵进行十折交叉验证,在重复验证的情况下获取cv值临界点的特征数量,基于所述cv值临界点的特征数量选取最优特征列,将选取出的最优特征列和样本分类列构建第二训练矩阵。
30.本发明采用随机森林的平均精度下降指标和十折交叉验证方法对特征列进行了筛选,仅保留了cv值临界点的特征数量的特征列,使得第二训练矩阵中的特征列都是对预测效果具有明显影响力的重要特征列,并且排除了影响力较弱的特征列,实现了预测结果的准确度的明显提高。
31.优选地,对所述第二训练矩阵进行数据集训练并基于训练结果构建风险评估模型的步骤至少包括:
32.将随机森林算法代入第二训练矩阵并且基于测试集进行训练和/或测试,在训练参数循环变化的情况下,选择与测试准确性最高对应的第二训练矩阵的参数值为第二有效
参数,将由第二训练矩阵训练形成的第二训练结果构成风险评估模型。
33.在选取了具有明显影响力的重要特征列后,本发明对第二训练矩阵进行再一次的重新训练,优化训练参数,形成的疾病风险评估模型的准确度更高。
34.本发明还提供一种基于肠道微生物的疾病风险评估系统,至少包括:
35.预处理模块,用于对样本测序数据进行质控和预处理;
36.提取模块,用于构建微生物种水平的相对丰度矩阵并提取特征矩阵;
37.评估模块,用于根据本发明的基于肠道微生物的疾病风险评估模型构建方法形成的疾病风险评估模型,对所述特征矩阵进行疾病风险评估,得到评估结果。
38.本发明还提供一种基于肠道微生物的疾病风险评估方法,所述方法至少包括:对样本测序数据进行质控和预处理;构建微生物种水平的相对丰度矩阵并提取特征矩阵;由根据本发明的基于肠道微生物的疾病风险评估模型构建方法形成的疾病风险评估模型对所述特征矩阵进行疾病风险评估,得到评估结果。
39.优选地,疾病风险评估方法中,所述构建微生物种水平的相对丰度矩阵并提取特征矩阵的步骤至少包括:
40.筛选样本微生物种水平的相对丰度信息并合并形成所述相对丰度矩阵,对所述相对丰度矩阵进行特征过滤;
41.基于等距log-ratio转化公式对所述相对丰度矩阵中的特征值进行转化并形成样本特征矩阵。
42.本发明的基于肠道微生物的疾病风险评估系统及方法,基于收集疾病和健康人群肠道微生物的宏基因组测序数据,通过等距log-ratio和机器学习等算法对数据集进行标准化处理、数据挖掘和建模等,在疾病风险预测准确性上有了较大的提升,可以用于多种慢性疾病的发病风险提示和健康监测。
附图说明
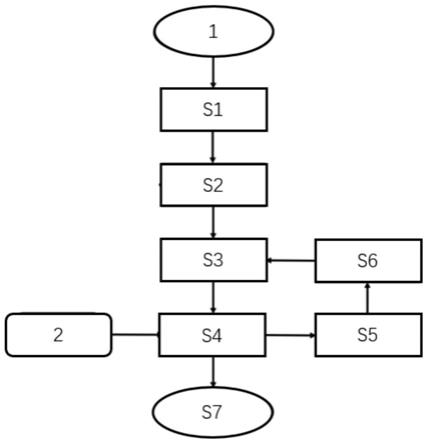
43.图1是本发明提供的基于肠道微生物的疾病风险评估方法的一种优选实施方式的流程图;
44.图2是本发明提供的一种优选实施方式的特征评估cv曲线示意图;
45.图3是本发明提供的一种优选实施方式的模型roc曲线示意图;
46.图4是本发明提供的另一种优选实施方式的特征评估cv曲线示意图;
47.图5是本发明提供的另一种优选实施方式的模型评估roc曲线示意图;
48.图6是本发明提供的一种优选实施方式的疾病预测风险概率分布示意图。
49.附图标记列表
50.1:样本集;2:测试集。
具体实施方式
51.下面结合附图进行详细说明。
52.本发明提供一种基于肠道微生物的疾病风险评估模型构建方法及其应用,还可以提供一种疾病风险评估方法及系统。
53.如图1所示,本发明的基于肠道微生物的疾病风险评估模型的构建方法,至少包
括:
54.s1:对样本测序数据进行质控和预处理;
55.s2:构建微生物种水平的相对丰度矩阵并提取特征矩阵;
56.s3:基于分类列和特征矩阵构建第一训练矩阵并且进行数据集训练;
57.s4:筛选第一训练矩阵中的若干最优特征列和样本分类列以构建第二训练矩阵;对第二训练矩阵进行数据集训练并基于训练结果构建风险评估模型。
58.本发明的基于肠道微生物的疾病风险评估方法还可以包括:
59.s5:性能验证:将样本集1分为训练集和测试集2,设置训练参数循环变化,分别采用测试集2对第二训练矩阵进行测试。
60.s6:参数优化:将与最高测试准确性对应的训练参数作为风险评估模型的最终参数值。
61.s7:在构建风险评估模型后,采用风险评估模型进行疾病风险评估的应用。
62.实施例1
63.本发明对基于肠道微生物的疾病风险评估模型构建方法的各个步骤进行详细的说明。
64.s1:对样本测序数据进行质控和预处理。
65.采集疾病和健康人群肠道微生物样本测序数据,进行样本测序数据的质控和处理。
66.例如,收集175例建结直肠癌crc患者和153例健康人群的粪便样本的宏基因组测序数据。单样本测序数据量10gb~15gb不等。人群样本有明确的疾病和健康分组信息,每组样本数不少于100例。疾病人群样本尽可能避免患有其他疾病。健康人群样本未患有该疾病,并且尽可能避免患有其他疾病。疾病和健康分组样本数趋于相等。
67.进行样本测序数据的质控和处理的步骤包括:
68.测序数据统计和测序质量评估;
69.对测序接头和低质量序列过滤;
70.对宿主基因组序列过滤。
71.优选地,测序接头和低质量序列过滤包括去除所含低质量碱基(碱基质量《=30)超过50bp的序列、去除所含n碱基超过10bp的序列、去除所含部分接头序列超过15bp的序列。优选地,宿主基因组序列过滤包括与宿主参考基因组进行比对、去除比对上的序列。优选地,宿主参考基因组选择人hg19或hg38版本。
72.例如,使用预存储的程序对样本测序数据进行数据统计和质量评估。使用预存储的程序进行测序接头和低质量碱基过滤,得到高质量数据。使用预存储的程序将高质量数据比对到人参考基因组hg19,提取未比对上的序列作为后续分析的高质量数据。
73.s2:构建微生物种水平的相对丰度矩阵并提取特征矩阵。
74.具体地,筛选样本微生物种水平的相对丰度信息,合并形成相对丰度矩阵。
75.基于metaphlan3工具和相关数据库进行各样本微生物菌种鉴定和各分类层级的相对丰度定量。筛选保留各样本微生物种水平的相对丰度信息。合并全部样本微生物种水平的相对丰度信息并形成相对丰度矩阵。
76.优选地,合并过程取并集,即对于仅在部分样本中存在丰度的微生物进行保留,其
他样本中该微生物丰度赋值为0。
77.优选地,相对丰度矩阵为m*n的矩阵,m代表样本数量,n代表微生物种水平数量即特征数量。矩阵中第i行第j列数值代表第i个样本对应第j个特征的相对丰度值。其中1≤i≤m,1≤j≤n。
78.优选地,对相对丰度矩阵进行特征过滤。
79.特征过滤能够去除在疾病和健康人群样本中0值占比均超过90%的特征及相关的丰度值列,使得过滤后的相对丰度矩阵具有一定的人群代表性,有利于后期进行模型训练时提高训练结果的准确性。优选地,保存m*n相对丰度矩阵作为后续受检样本的微生物筛选标准。
80.例如,使用预存储的程序(例如metaphlan3)进行各样本微生物物种注释分析,生成包含微生物各层级分类及相对丰度值等信息。使用预存储的程序合并全部样本。提取微生物种水平的各样本相对丰度信息,生成样本-特征(微生物)的相对丰度矩阵。保存样本-特征的相对丰度矩阵,作为风险评估模型的特征原始信息文件。
81.本发明通过特征矩阵的提取步骤,有目的地保留特征矩阵,去除可能会对于风险评估结果存在干扰或增大误差的特征列。
82.基于等距log-ratio转化公式对相对丰度矩阵中的特征值进行转化并形成样本特征矩阵。
83.采用较小的正数值替换相对丰度矩阵中的0值;选定一组标准正交基,得到相应的等距log-ratio转化公式;将相对丰度矩阵代入等距log-ratio转化公式进行转化并形成样本特征矩阵。
84.等距log-ratio转化公式为:对于任意的i=1,2,3,
…
,n-1,转化值1,转化值
85.n为相对丰度矩阵的特征数量,ai表示第i个特征值,g(a1,a2,a3,
…ai
)表示a1,a2,a3,
…ai
的几何平均数。
86.通过等距log-ratio转化公式转化形成的样本特征矩阵,特征数量由n变为n-1。即样本特征矩阵为m*(n-1)矩阵,转化后的特征名称采用ni/n
i 1
替换,其中ni表示相对丰度矩阵的第i个特征的名称。
87.本发明通过等距log-ratio转化公式转化,将相对丰度矩阵进行标准化转化,消除了矩阵中共线性和易方差性,因此能够减少后期数据训练产生的数据误差。
88.s3:基于分类列和特征矩阵构建第一训练矩阵并且进行数据集训练。
89.在形成样本特征矩阵后,基于样本分组信息和样本特征矩阵的特征列构建第一训练矩阵。第一训练矩阵为m*n矩阵。
90.首先,在第一训练矩阵里添加一列样本分组信息,即第一训练矩阵的第一列标记样本分组信息,定义为class。疾病样本分组赋值为crc,正常样本分组赋值为hc。
91.将随机森林算法代入第一训练矩阵并且基于测试集进行训练和/或测试。例如,设置训练参数ntree=1000,importance=true。在训练参数循环变化的情况下,选择与测试准确性最高对应的第一训练矩阵的参数值为第一有效参数。
92.例如,m*n训练矩阵按照样本数8:2随机分成训练集和测试集。设置训练参数mtry
由1循环至10,分别对训练集进行训练并对测试集进行测试。取与最高测试准确性对应的训练参数mtry值作为最终训练的第一有效参数值。本发明的随机森林算法的平均精度下降和基尼指数两个指标可以更加有效的评估特征权重。
93.构建第一训练矩阵并且基于机器学习算法进行训练,能够得到最基本的风险评估模型。但是,仅由第一次数据训练形成的训练模型采纳了特征矩阵的全部特征,导致模型的泛化能力不足,在实际使用的过程总会存在过拟合的问题。
94.为了解决问题,本发明根据重要性对特征进行进一步筛选。此时的风险评估模型中,第一训练矩阵中的特征列对样本分类具有影响的特征权重不同,一部分特征列对样本分类具有影响的特征权重比较大,另一部分对样本分类具有影响的特征权重比较小。特征权重小的特征列对风险评估结果存在干扰,从而使得风险评估结果存在偏差。不仅如此,特征列较多,还增大了数据计算量,延长了数据统计的时间。因此,有必要将特征权重高的特征列筛选出来,排除掉特征权重小的特征列,以减少风险评估模型的计算量和计算时间,减少评估结果的等待时间。
95.s4:筛选第一训练矩阵中的若干最优特征列和样本分类列以构建第二训练矩阵;对第二训练矩阵进行数据集训练并基于训练结果构建风险评估模型。
96.筛选第一训练矩阵中的若干最优特征列和样本分类列以构建第二训练矩阵的步骤包括:将第一训练矩阵中的特征列基于平均进度下降指标按照由高到低的顺序进行重要性排序。
97.本发明采用随机森林的平均精度下降指标和十折交叉验证方法对特征列进行了筛选,仅保留了所述cv值临界点的特征数量的重要特征列,使得第二训练矩阵中的特征列都是对预测效果具有明显影响力的特征列,并且排除了影响力较弱的特征列,实现了预测结果的准确度的明显提高。
98.本发明中,采用rfcv函数进行十折交叉验证。设置验证参数cv.fold=10,step=1.5。重复验证至少一次。优选地,重复验证5次。记录cv值临界点的特征数量n。基于特征重要性排序后选取前n个重要特征列作为最优特征列。绘制不同特征数量的cv值曲线。
99.基于m*n的第一训练矩阵选取前n个重要特征列和样本分类列,构建最优的第二训练矩阵。第二训练矩阵为m*(n 1)矩阵,m代表样本数量,n 1代表最优特征列和样本分类列。
100.例如,基于数据集初步训练结果,根据平均精度下降指标由高到低进行特征重要性排序。使用rfcv函数对第一训练矩阵进行十折交叉验证,设置参数cv.fold=10,step=1.5。重复验证5次后取平均获得梯度特征数量下的cv值,并绘制cv值曲线,如图2所示。记录cv值临界点的特征数量约为30。基于特征重要性排序后选取前30个重要特征作为最优特征。基于第一训练矩阵提取30个最优特征列和样本分类列,构建第二训练矩阵。
101.本发明按照特征列的特征权重的大小对第一训练矩阵中的特征列进行筛选,保留对样本分类的作用明显的特征列,减少对样本分类的作用不明显的特征列,在不影响风险评估的结果的基础上缩小了训练矩阵的大小,也减少了本发明的数据的计算量。
102.在进行特征列的筛选后,对第二训练矩阵进行数据集训练并基于训练结果构建风险评估模型。
103.将随机森林算法代入第二训练矩阵并且基于测试集进行训练和/或测试,在训练参数循环变化的情况下,选择与测试准确性最高对应的第二训练矩阵的参数值为第二有效
参数,将由第二训练矩阵训练形成的第二训练结果构成风险评估模型。
104.优选地,保存n个特征名称及重要性指标值作为模型特征,保存oob误差值作为模型重要的性能指标。
105.例如,基于随机森林算法对m*(n 1)的第二训练矩阵进行训练。设置训练参数ntree=1000,importance=true。按照样本数8∶2随机分成训练集和测试集。设置训练参数mtry由1循环至10,分别对训练集进行训练并对测试集进行测试。取与最高测试准确性对应的第二训练参数mtry值作为最终训练的第二有效参数值。保存第二训练结果作为最终的crc疾病风险预测模型。保存30个最优特征名称及重要性指标值等信息,作为crc疾病模型的特征文件。记录oob误差值作为crc疾病模型的重要性能指标。
106.优选地,对疾病风险预测模型灵敏度和特异度进行评估,包括:第二训练矩阵按照样本数8∶2随机分成训练集和测试集。分别对训练集进行训练并对测试集进行测试;测试分类结果与实际结果进行比较;比较结果绘制roc曲线,如图3所示。如图3所示,本发明的风险评估模型的灵敏度和特异度都比较好。
107.如上所述,本发明的构建方法的优势明显在于:
108.第一,将丰度信息构建为相对丰度矩阵,实现了特征过滤,能够去除在疾病和健康人群样本中0值占比均超过90%的特征及相关的丰度值列,使得过滤后的相对丰度矩阵具有一定的人群代表性,有利于后期进行模型训练时提高训练结果的准确性;
109.第二,对相对丰度矩阵通过等距log-ratio、机器学习和十折交叉验证等算法实现数据集的标准化处理,有效性更强;
110.第三,基于第一次训练矩阵直接形成模型的缺陷:模型的泛化能力不足和实际使用会存在过拟合,本发明通过基于平均精度下降指标按照由高到低的顺序对第一训练矩阵进行重要性排序,选取最优特征列构建第二训练矩阵;即本发明采用随机森林的平均精度下降指标和十折交叉验证方法对特征列进行筛选,仅保留所述cv值临界点的特征数量的重要特征列,排除影响力较弱的特征列,实现了预测结果的准确度的明显提高;
111.第四,本发明通过特征列的筛选,还减少了模型的存储量和数据计算量,使得风险评估模型的训练时效明显缩短,评估结果准确度高。
112.实施例2
113.本发明还提供了一种基于肠道微生物的疾病风险评估系统,通过本发明的由基于肠道微生物的疾病风险评估模型构建方法形成的疾病风险评估模型对疾病风险进行评估。
114.基于肠道微生物的疾病风险评估系统包括彼此建立通信连接的预处理模块、提取模块和评估模块。预处理模块、提取模块和评估模块均可以是专用集成芯片、处理器、服务器、cpu中的一种或几种。预处理模块、提取模块和评估模块还可以集成为一个处理器、服务器或者专用集成芯片。本发明的基于肠道微生物的疾病风险评估系统还能够以执行程序的方式存储,以使得该系统能够在处理器中运行。
115.预处理模块,用于对样本测序数据进行质控和预处理;
116.提取模块,用于构建微生物种水平的相对丰度矩阵并提取特征矩阵;
117.评估模块,存储有风险评估模型,并且能够对特征矩阵进行疾病风险评估。
118.本发明以构建孤独症谱系障碍(asd)的肠道微生物风险评估模型的示例说明基于肠道微生物的疾病风险评估系统的运行。
119.收集样本数据。收集135例asd患者和123例健康人群的粪便样本的宏基因组测序数据,单样本测序数据量10gb~30gb不等。
120.预处理模块对测序数据进行数据质控和处理。预处理模块中能够存储和自动运行fastqc软件、fastp软件、bowtie2软件等。
121.使用fastqc软件对测序数据进行数据统计和质量评估。使用fastp软件进行测序接头和低质量碱基过滤,得到高质量数据。使用bowtie2软件将高质量数据比对到人参考基因组hg19,提取未比对上的序列作为后续分析的高质量数据。
122.提取模块构建相对丰度矩阵。提取模块中能够存储并自动运行metaphlan3软件。使用metaphlan3软件进行各样本微生物物种注释分析,生成包含微生物各层级分类及相对丰度值等信息。提取模块合并全部样本,提取样本中微生物种水平的各样本相对丰度信息,生成样本-特征(微生物)的相对丰度矩阵。保存样本-特征相对丰度矩阵,作为疾病模型的特征原始信息文件。
123.提取模块将相对特征丰度进行等距log-ratio转化,形成样本-特征矩阵。
124.提取模块对于任意的i=1,2,3,
…
,n-1,转化值1,转化值n为相对丰度矩阵的特征数量,ai表示第i个特征值,g(a1,a2,a3,
…ai
)表示a1,a2,a3,
…ai
的几何平均数。
125.提取模块利用等距log-ratio公式转化形成的样本特征矩阵为m*(n-1)矩阵,转化后的特征名称采用ni/n
i 1
替换,其中ni表示相对丰度矩阵的第i个特征的名称。
126.评估模块在构建过程进行疾病风险评估模型的构建,在模型构建完成后直接用于进行疾病风险评估的评估测试。
127.首先,在构建模型时,评估模块对数据集初步训练。
128.评估模块接收提取模块发送的样本特征矩阵。评估模块首先在样本特征矩阵里添加一列样本分组信息,标签定义为class,疾病样本分组赋值为asd,正常样本分组赋值为hc。然后使用r语言随机森林算法对样本特征矩阵进行初步训练,设置参数ntree=1000,importance=true。设置训练参数mtry由1循环至10,分别对样本特征矩阵进行训练集的训练并对测试集进行测试。取与最高测试准确性对应的训练参数mtry值作为最终训练的第一有效参数值。
129.在构建模型时,评估模块对优化后的第一训练矩阵进行最优特征筛选。
130.基于第一训练矩阵的训练结果,评估模块根据平均精度下降指标由高到低进行特征重要性排序。评估模块自动使用rfcv函数对第一训练矩阵进行十折交叉验证。设置参数cv.fold=10,step=1.5。重复验证5次后取平均获得梯度特征数量下的cv值,并绘制cv值曲线,如图4所示。记录cv值临界点的特征数量约为20。基于特征重要性排序后选取前20个重要特征作为最优特征。基于第一训练矩阵提取20个最优特征列和样本分类列,构建第二训练矩阵。
131.评估模块使用随机森林算法对第二训练矩阵重新进行训练。设置参数ntree=1000,importance=true。设置训练参数mtry由1循环至10,分别对第一训练矩阵进行训练集的训练并对测试集进行测试。取与最高测试准确性对应的训练参数mtry值作为最终训练的第二有效参数值。
132.评估模块将训练结果保存,作为最终的asd的疾病风险评估模型。20个最优特征名称及重要性指标值等信息保存,作为asd疾病模型的特征文件。评估模块记录oob误差值作为asd疾病模型的重要性能指标。
133.本发明的系统还可以包括检测模块,用于对风险评估模型的灵敏度和特异度评估。
134.将风险评估模型按照样本数8∶2随即分成训练矩阵(206样本)和测试矩阵(52样本)。基于随机森林算法对风险评估模型进行训练。使用predict函数对测试矩阵进行疾病分类预测。预测结果与矩阵class标签列进行比较。基于比较结果绘制roc曲线,如图5所示。
135.实施例3
136.本实施例是对实施例1或者实施例2提供的模型或方法的进一步改进或应用,重复的内容不再赘述。
137.本实施例提供一种疾病风险评估方法,是对基于肠道微生物的疾病风险评估模型的进一步应用。
138.本实施例中,通过肠道微生物的疾病风险评估模型以单盲法预测一批样本的asd疾病风险。
139.受检样本数据:获得一批78个人群粪便样本的宏基因组测序数据,单样本测序数据量~10gb。
140.预处理模块对数据质控和处理。对测序数据进行数据统计和质量评估;进行测序接头和低质量碱基过滤,得到高质量数据;将高质量数据比对到人参考基因组hg19,提取未比对上的序列作为后续分析的高质量数据。
141.提取模块构建相对丰度矩阵。提取模块基于预存储的运行程序进行各样本微生物物种注释分析,生成包含微生物各层级分类及相对丰度值等信息。提取模块合并全部样本。基于已有的asd疾病模型中的特征(微生物)信息,提取模块提取相关特征的各样本相对丰度信息,生成受检样本-特征的相对丰度矩阵。
142.提取模块将样本特征矩阵进行等距log-ratio转化。提取模块基于等距log-ratio转化公式对相对丰度矩阵各样本特征值进行转化,生成特征矩阵。
143.评估模块首先在特征矩阵里添加一列样本分组信息,标签定义为class,全部样本分组赋值为null。评估模块直接调用对应的风险评估模块对受检的特征矩阵进行疾病分类预测,其中分别设置参数type=”class”和type=”prob”进行两次预测,分别生成分类和概率结果,合并两次预测结果并保存。
144.评估模块评估预测结果。评估模块将受检样本真实疾病分类信息(其中asd样本58例、正常样本20例)与预测结果进行比较,预测的疾病风险概率分布如图6所示,疾病分类灵敏度和特异度结果如表1所示。
145.表1:
146.样本分组实际样本数预测样本数占比asd584781%hc201470%
147.如图6所示,本发明的疾病风险评估模型,能够较准确的区分疾病和健康人群,健康人群预测的疾病风险概率值较低,而疾病人群预测的疾病风险概率值普遍较高。
148.需要注意的是,上述具体实施例是示例性的,本领域技术人员可以在本发明公开内容的启发下想出各种解决方案,而这些解决方案也都属于本发明的公开范围并落入本发明的保护范围之内。本领域技术人员应该明白,本发明说明书及其附图均为说明性而并非构成对权利要求的限制。本发明的保护范围由权利要求及其等同物限定。本发明说明书包含多项发明构思,诸如“优选地”、“根据一个优选实施方式”或“可选地”均表示相应段落公开了一个独立的构思,申请人保留根据每项发明构思提出分案申请的权利。
再多了解一些
本文用于企业家、创业者技术爱好者查询,结果仅供参考。