本发明总体上涉及图像和视频处理,并且更具体地涉及对对象上的特征点(landmark)的位置的估计。
背景技术
特征点定位是指估计图像中对象的多个预定特征点的位置。特征点定位是在具有特征点的结构化集合的不同类型对象(如人脸和人体)的图像上进行的。如果在人脸图像上执行特征点定位,则特征点定位被称为面部对齐(face alignment),并且包括估计包括诸如眼角和嘴角的预定面部特征点点的特征点的结构化集合在图像中的位置。如果在人体图像上执行特征点定位,则特征点定位被称为人体姿势估计,并且包括估计包括诸如肘关节和膝关节的预定解剖特征点点的身体的特征点的结构化集合在图像中的位置。
例如,面部图像上的特征点定位(即,面部对齐)是包括面部表情识别、头部姿势估计、3D面部建模、人-机器人交互和远程光容积描记术的许多计算机视觉应用的面部相关任务的基本步骤。所有这些任务的完成在很大程度上取决于面部特征点定位的精度。然而,由于诸如面部形状、面部表情和取向、照明和图像质量的因素导致的不同面部图像的变化,面部对齐不可避免地受到由于特征点定位的不确定性(uncertainty)而导致的误差的影响。
面部对齐和人体姿势估计的许多方法都基于深度学习模型。用于这些任务的当前深度学习模型通常使用深度网络的级联,这是为人体姿势估计而开发的网络架构。
这样的深度学习模型是基于热图的,因为这样的深度学习模型是使用针对每个特征点的预测热图和代理真实热图(proxy ground-truth heatmap)之间的距离(l2距离,其是欧几里德距离)来训练的。通过将具有小固定方差的各向同性高斯分布放置在真实特征点位置,可以生成代理真实热图。此外,深度学习模型使用每个预测热图的argmax(即热图具有其最大值的像素位置)来确定特征点的位置。
深度学习模型提高了特征点定位的精度。然而,这种方法具有若干缺陷。例如,由于热图的argmax仅可被确定到最近的像素,因此在确定特征点位置期间引入量化误差。
用于特征点定位的大多数深度学习方法为每个特征点输出单个位置,并且网络无法输出每个位置估计的不确定性水平。用于面部对齐的一种深度学习方法使用非参数概率密度函数来估计每个特征点的位置。在非参数方法中,通过将热图与固定的各向同性高斯内核进行卷积,得到内核密度网络。非参数内核密度网络模型是一种将较大连续分布近似为简单参数模型的非常大的离散集合的并集(union)的方法。然而,非参数方法可能需要大量的训练数据以便获得精确的结果。此外,当正被非参数地建模的分布接近简单参数分布的形状时,非参数方法是次优的。此外,这种非参数方法受到热图的底层像素网格分辨率和固定内核大小的限制;例如,使用非参数方法无法精确地建模比内核大小更窄的分布。因此,需要开发系统和方法来验证和提高特征点位置的估计的精度。
技术实现要素:
一些实施方式的目的是提高图像中对象的多个预定特征点的特征点定位的精度。另外或替代地,一些实施方式的目的是根据特征点定位的精度来提高任务执行的精度。另外或替代地,一些实施方式的目的是即使在特征点定位中存在错误的情况下也提高这些任务的执行精度。
一些实施方式基于这样的认识,即,特征点定位中的错误是可能的,但是为了后续执行依赖于特征点位置的任务的目的,这些错误是可恢复的。例如,对于在驾驶员面部的图像序列中执行面部对齐的车辆驾驶员监控系统,如果对于一些图像面部对齐是不确定的,则可以减少该图像用于监控任务,例如,可以减少集合执行中的该图像的权重,或者可以一起跳过该图像。
为此,一些实施方式基于这样的认识,即,除了特征点定位之外,估计这种估计的不确定性并且使用这些不确定性来指导后续任务的执行是有益的。此外,一些实施方式基于这样的认识,即,对特征点定位的不确定性的估计不应该是单独的过程,而是应该集成在特征点定位本身中。具体地,如果训练神经网络以执行特征点定位,则这样的神经网络不仅应当输出特征点位置,而且应当输出估计位置的不确定性。以这种方式,可以端到端地训练神经网络以实现两个目标。
然而,这种双目标神经网络的配置和训练产生了与非参数数据的复杂性以及每个特征点的特征点定位的不确定性与整个图像的不确定性之间的差异有关的附加挑战。一些实施方式分两个步骤解决这些问题。首先,一些实施方式使用的神经网络不输出特征点的位置,而是输出图像中每个特征点的位置上的参数概率分布。参数概率估计涉及确定参数模型的少量参数以表示图像中每个特征点的位置上的概率分布。因此,使用小参数模型而不是使用大的非参数模型来表示每个特征点位置上的概率分布。在一些实施方式中,每个特征点的参数概率分布的不同参数定义特征点的位置的点估计和每个特征点的位置估计的不确定性。以这种方式,神经网络的单个输出可以表示特征点的位置和其估计的不确定性两者。以这种方式,针对双目标训练一些实施方式的神经网络,而不显著增加计算负担和输出数据量。
每个处理图像中的每个特征点的位置的由参数的值定义的参数概率分布的示例是高斯分布,其中,参数确定高斯分布的均值和协方差矩阵。在该示例中,均值定义特征点的位置点,协方差矩阵定义不确定性。注意,协方差矩阵定义特征点位置上的高斯概率分布的多维(例如,二维)形状和结构。
此外,一些实施方式确定输入图像中每个特征点的参数分布。以这种方式,可以为每个单独的特征点定制不确定性估计。然而,一些实施方式基于针对输入图像的各个特征点确定的参数概率分布的参数的组合来确定输入图像的全局不确定性。例如,在一些实现方式中,全局不确定性是汇总图像中所有单独特征点位置的不确定性的单个标量测量。任务执行可以使用输入图像的该单个标量测量作为简单测量来确定如何处理该输入图像。以这种方式,提高了任务执行的精度。
一些实施方式基于这样的认识,即,每个特征点的参数概率分布包括特征点的位置的估计,使得从参数概率分布的参数导出特征点的位置和每个特征点的位置估计的不确定性。为此,参数概率分布的一些参数定义特征点位置的点估计,并且参数概率分布的其他参数定义特征点位置的估计的不确定性,诸如概率分布的形状和扩展。然而,基于热图的表示对于估计这些参数中的一些可能是次优的。事实上,可以使用不同的机制来最优地估计不同的参数。
例如,在为每个特征点估计高斯概率分布的一些实施方式中,从一个或更多个热图获得高斯概率分布的均值(其是特征点位置的点估计),而通过直接回归来获得确定协方差矩阵的参数。一些实施方式通过实验确定,通过直接回归(例如,从神经网络的瓶颈层处的低维特征值)获得高斯协方差矩阵的协方差矩阵(其确定分布的不确定性,即,其形状和扩展)比从热图获得协方差矩阵提供更精确的结果。这可能是因为热图没有足够高的分辨率来给出分布的大小和形状的良好估计。另外,一些实施方式还通过实验发现,从热图获得特征点位置的点估计(高斯的均值)比通过直接回归获得点估计工作得更好。为此,一些实施方式从热图计算特征点位置的点估计(例如,高斯的均值),同时经由直接回归计算特征点位置的不确定性(例如,概率分布的形状和扩展)。
另外或替代地,一些实施方式基于这样的认识,即,用于训练具有概率输出的这种神经网络的损失函数应当捕获该概率性质。为此,一些实施方式训练神经网络以提供从输入图像到概率分布的映射,该映射使真实特征点位置的可能性最大化。例如,可以使用负对数似然度作为损失函数来训练神经网络。
以这种方式,为每个特征点位置输出参数分布(例如,高斯分布)允许使用与输出分布匹配的损失函数来训练神经网络。例如,高斯对数似然损失函数使得能够同时估计特征点位置及其不确定性。这种联合估计产生了对不确定性的良好预测,但这也产生了最先进的面部对齐结果。以这种方式,具有概率输出的双目标神经网络允许同时估计特征点位置及其不确定性,以及提高特征点定位的精度。
另外或替代地,一些实施方式的目的是提供一种用于安全关键应用(例如驾驶员监控)的特征点检测系统。与特征点位置检测一起,不确定性的估计为执行与安全关键应用(例如,驾驶员监控)相关的任务提供了额外的支持。在一些实施方式中,训练神经网络以处理具有特征点的结构化集合的一种对象的图像,以产生在图像中的每个特征点的位置上的参数概率分布。
在一些实施方式中,神经网络是密集连接的U-网(DU-Net)架构,从一个或更多个U-网(其也称为沙漏网络或沙漏)向该U-网架构添加两个附加分支组件。在一些实施方式中,从所有沙漏添加新组件;在其他实施方式中,仅从最终的沙漏添加新组件。第一附加组件是均值估计器,其以可微分的方式计算估计的特征点位置,其中,每个特征点的估计位置被计算为对应热图的正元素的加权空间均值。第二组件是Cholesky估计器网络(CEN),其估计每个特征点位置的2D高斯概率分布的协方差矩阵的Cholesky系数。高斯对数似然损失(GLL)的估计使得能够估计特征点位置和与特征点位置相关联的不确定性,其中,估计的特征点位置被用作高斯分布的均值,并且估计的协方差矩阵被用作高斯分布的协方差。这种估计被称为具有高斯对数似然的不确定性(UGLLI),其产生不确定性估计和特征点位置估计两者。
例如,用于计算均值和协方差矩阵的方法的选择可以是区别因素。一些实施方式基于这样的认识,即,从热图获得特征点位置的点估计产生特征点位置的更精确估计。然而,一些实施方式基于这样的认识,即,当通过直接回归而不是从热图获得概率分布的其他参数时,概率分布的其他参数更精确。因此,在一个实施方式中,从热图获得特征点位置的概率分布(例如,均值),而通过直接回归获得特征点概率分布的形状和扩展(例如,协方差矩阵)。
另外或替代地,一些实施方式基于如下认识,即,因为双目标神经网络输出概率分布的参数,所以概率特征点位置估计可以与其他概率滤波器组合以进一步提高特征点定位的精度。例如,在一些实施方式中,当前输入图像的特征点的参数概率分布是高斯概率分布,并且使用卡尔曼滤波器来确定高斯概率分布,卡尔曼滤波器使用针对先前输入图像确定的高斯概率分布来更新针对当前输入图像确定的高斯概率分布。卡尔曼滤波基于所涉及的概率分布是高斯分布的假设,因此卡尔曼滤波可以很好地适用于跨视频的后续帧的特征点位置和不确定性的顺序估计。
在一些实施方式中,基于估计的全局不确定性来执行任务。另外或替代地,在一些示例实施方式中,基于估计的特征点位置和估计的全局不确定性两者来执行任务。在一些示例实施方式中,如果关于图像中的多个特征点的位置的估计的全局不确定性高于阈值,则控制器拒绝从图像估计的特征点用于安全关键应用,并且随后不执行任务。在一些实施方式中,如果图像的估计的全局不确定性低于阈值,则执行任务。
因此,一个实施方式公开了一种用于根据概率性的基于图像的特征点定位来执行任务的控制器。所述控制器包括:输入接口,其被配置为接受具有特征点的结构化集合的一种对象的输入图像的集合;存储器,其被配置为存储神经网络,所述神经网络被训练以处理具有所述特征点的结构化集合的所述一种对象的图像,以产生每个处理的图像中的每个特征点的位置的由参数的值定义的参数概率分布;以及处理器,其被配置为将所述输入图像的集合提交给所述神经网络以产生参数的值,所述参数的值定义每个输入图像的特征点的结构化集合中的每个特征点的位置上的参数概率分布;基于所述输入图像中的特征点的参数概率分布针对每个输入图像确定图像的全局特征点不确定性;并且基于每个输入图像中的特征点的参数概率分布和每个输入图像的全局特征点不确定性来执行任务。
将参照附图进一步解释当前公开的实施方式。所示出的附图不一定是按比例绘制的,而是通常将重点放在说明当前公开的实施方式的原理上。
附图说明
[图1A]
图1A示出了根据一些实施方式的用于根据概率性的基于图像的特征点定位来执行任务的控制器的框图。
[图1B]
图1B示出了根据一些实施方式的人脸的输入图像的集合。
[图1C]
图1C示出了根据一些实施方式的人体的输入图像的集合。
[图2]
图2示出了根据一些实施方式的用于根据概率性的基于图像的特征点定位来执行任务的控制器的原理的示意性概视图。
[图3]
图3示出了说明由一些实施方式使用的概率神经网络的原理的示意图。
[图4A]
图4A示出了根据一些实施方式的训练神经网络以估计特征点位置和位置估计的不确定性的示意图。
[图4B]
图4B示出了根据一些实施方式的用于针对每个输入图像获得每个特征点的位置上的参数概率分布的具有高斯对数似然损失的不确定性(UGLLI)方法的方案。
[图5]
图5示出了测试图像上的特征点位置估计和位置估计的不确定性的示例性结果。
[图6A]
图6A是根据一些实施方式的在300-W公共、挑战和完整数据集(分叉1)上的不同方法之间的归一化均值误差(NME)比较表。
[图6B]
图6B是300-W测试(分叉2)和Menpo数据集上不同方法之间的NME和曲线下面积(AUC)的比较的图表。
[图7]
图7示出了相对于所有300-W测试图像上的特征点位置的点估计的归一化误差的位置估计的归一化不确定性的绘图(分叉2)。
[图8]
图8是示出使用在300-W分叉2上训练的UGLLI方法对300-W测试和Menpo数据集进行消融研究的图表。
[图9A]
图9A示出了根据一些实施方式的使用不确定性反馈来改进特征点定位的示意图。
[图9B]
图9B示出了没有不确定性反馈和具有不确定性反馈的特征点位置估计和特征点位置估计的不确定性的示例性结果。
[图10]
图10示出了根据一些实施方式的用于在车辆驾驶员监控环境中根据概率性的基于图像的特征点定位来执行任务的示意图。
[图11]
图11示出了用于将概率性的基于图像的特征点定位合并到Bayes滤波器(诸如卡尔曼滤波器)中以用于视频特征点跟踪的示意图。
具体实施方式
在以下描述中,出于解释的目的,阐述了许多具体细节,以便提供对本公开的透彻理解。然而,对于本领域技术人员来说显而易见的是,可以在没有这些具体细节的情况下实践本公开。在其他实例中,装置和方法仅以框图形式示出,以避免使本公开模糊。
如本说明书和权利要求书中所使用的,当与一个或更多个组件或其他项目的列表结合使用时,术语“例如”、“比如”、和“诸如”,以及动词“包括”、“具有”、“包含”和它们的其他动词形式均被理解为开放式的,这意味着该列表不应被视为排除其他的附加组件或项目。术语“基于”是指至少部分基于。此外,应当理解,这里使用的措辞和术语是为了描述的目的,不应当被认为是限制性的。本说明书中使用的任何标题仅为方便起见,没有法律或限制作用。
系统概述
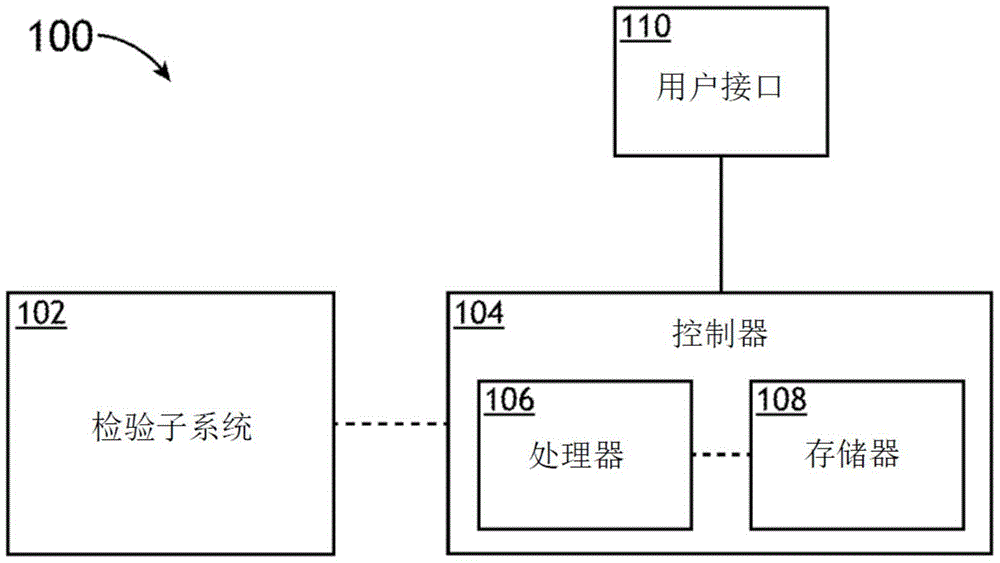
图1A示出了根据一些实施方式的用于根据概率性的基于图像(probabilistic image)的特征点定位来执行任务的控制器100的框图。例如,在一些实施方式中,任务是车辆驾驶员监控系统的一部分,并且可以包括例如确定车辆驾驶员的面部对齐。在这些实施方式中,执行任务涉及执行或启动动作过程,例如降低车辆的速度和/或改变车辆的转向。然而,不同的实施方式使得能够基于图像中的特征点定位来执行不同的系统。
控制器100包括输入接口102,输入接口102被配置为接受具有特征点的结构化集合的一种对象的输入图像的集合122。此外,控制器100包括网络接口控制器(NIC)118,其适于通过总线116将控制器100连接到网络120。通过网络120,无线地或有线地,控制器100可以接收输入图像122。如本文所使用的,特征点的结构化集合指示输入图像是相同类型的,诸如人脸或人体的图像。
图1B示出了根据一些实施方式的人脸的输入图像集合。如图所示,输入图像可以具有具备不同表情和取向的不同面部。然而,这些面部的特征点具有相同的结构以确定嘴138、鼻子140、眉毛142、眼睛144等的位置、形状和构造。在这种情况下,界的标结构化集合定义了存在于典型面部上的特定面部特征点。包含一个或更多个输入图像的集合可以包括不同人的面部,但是可以是单个人的面部的图像的时间序列(例如,视频帧)。
图1C示出了根据一些实施方式的人体的输入图像的集合。在这种情况下,特征点的结构化集合限定人体的特定关节146和148。在一个实施方式中,图像彼此独立。在不同的实施方式中,输入图像集合是人体的图像的时间序列。在另一实施方式中,集合包含单个图像。
控制器100包括存储可由处理器104执行的指令的存储器106。处理器104可被配置为执行所存储的指令。处理器104可以是单核处理器、多核处理器、图形处理单元(GPU)、计算集群或任何数量的其他配置。存储器106可以包括随机存取存储器(RAM)、只读存储器(ROM)、闪存存储器或任何其他合适的存储器系统。处理器104通过总线116连接到一个或更多个输入和输出设备。此外,控制器100包括存储设备110,其被配置为存储神经网络112和诸如概率特征点估计器114和任务执行器136的其他组件。存储设备110可以使用硬盘驱动器、光驱、闪盘、驱动器阵列或其任意组合来实现。在一些实施方式中,神经网络112被训练以处理具有特征点的结构化集合的类型的对象的图像,以产生每个处理的图像中的每个特征点的位置上的由参数值定义的参数概率分布。在对象的类型是人脸的情况下,神经网络112被训练以处理不同面部的图像,例如图1B所示的人脸图像。在对象是人体的情况下,神经网络被训练以处理不同人体的图像,例如图1C所示的人体图像。
处理器104被配置为将输入图像的集合提交给神经网络112以产生定义每个输入图像的特征点的结构化集合中每个特征点的位置上的参数概率分布的参数的值。每个特征点的参数概率分布包括特征点的位置的估计,使得从参数概率分布的参数导出特征点的位置和特征点的位置估计的不确定性。在一些实施方式中,特征点的参数概率分布是高斯概率分布,并且特征点的估计位置是高斯概率分布的均值。位置估计的不确定性由高斯概率分布的协方差矩阵确定。从一个或更多个热图获得高斯概率分布的均值,并且通过直接回归获得确定协方差矩阵的参数。为此,一些实施方式基于这样的认识,即,神经网络112被进一步训练以提供从输入图像到高斯概率分布的映射,其使真实特征点位置的可能性最大化。在一些实施方式中,真实特征点位置是指特征点的实际或精确位置。在一些实施方式中,真实特征点位置是指由人类贴标者指示的特征点的位置。
处理器104执行概率特征点估计器114,以使用神经网络112来确定每个特征点位置上的参数概率分布,并且基于输入图像中的特征点的参数概率分布来为每个输入图像确定图像的全局特征点不确定性。例如,在一些实现方式中,将所确定的在输入图像中的特征点估计的不确定性进行组合,以产生输入图像的全局特征点不确定性。此外,处理器104被配置为运行任务执行器136以基于每个输入图像的全局特征点不确定性来执行任务。
在一些实施方式中,由处理器104执行任务基于对每个图像中的特征点的位置的估计和每个输入图像的全局特征点不确定性。在一些实施方式中,任务执行器的阈值可被预定义。在一些实施方式中,阈值对于任务是专用的,这意味着从一个任务到另一个任务阈值可以变化。如果输入图像的全局特征点不确定性低于阈值则任务执行涉及采取主要(primary)动作过程,并且如果输入图像的全局特征点不确定性高于阈值则采取辅助(secondary)动作过程。
在一些实现方式中,控制器100包括适于将控制器100连接到显示设备126的显示接口124,其中,显示设备126可以尤其包括计算机监视器、电视、投影仪或移动显示设备等。
另外或替代地,控制器100可以包括适于将控制器100连接到成像设备130的成像接口128。成像设备130可以包括视频摄像机、计算机、移动设备、网络摄像机或其任意组合。
另外或替代地,在一些实施方式中,控制器100通过总线116连接到应用接口132,应用接口132适于将控制器100连接到可以基于控制器100的结果操作的应用设备134。例如,在一个实施方式中,应用设备134是汽车导航系统,其使用估计的特征点位置来获得驾驶员的生命体征,并使用全局特征点不确定性来验证估计的特征点位置以及因此所获得的生命体征是否可被信任,并且该汽车导航系统执行包括决定如何控制(例如,转向)汽车的任务。例如,在一个实施方式中,应用设备134是驾驶员监控系统,其使用具有不确定性的特征点定位来确定和验证驾驶员的生命体征,以确定驾驶员何时能够安全驾驶,例如,驾驶员是否昏昏欲睡,或者驾驶员是否失能。
图2示出了根据一些实施方式的用于根据概率性的基于图像的特征点定位来执行任务的控制器的原理的示意性概视图。具有特征点的结构化集合的输入图像200被输入到神经网络202。输入图像200可以包括对象,诸如人脸和/或人体。在一些实施方式中,诸如视频帧序列的输入图像集合可被输入到神经网络202。神经网络202输出每个特征点位置的估计204和每个特征点位置的估计的不确定性206,例如概率分布的形状和比例(shape and scale)。输出参数,即每个特征点位置的估计204和每个特征点位置的不确定性206,定义每个特征点的位置上的参数概率分布208。
在一些实施方式中,每个特征点的位置上的参数概率分布208是2D高斯分布。对于2D输入图像,高斯分布由作为定义图像空间中位置的2D向量的均值和作为对角元素为正或至少非负的正定(或至少正半定)矩阵的2×2协方差矩阵来定义。在这样的实施方式中,高斯分布的均值可以用作每个特征点的位置的点估计。在一些其他实施方式中,中值位置(在x方向和y方向上单独计算)或概率分布达到其最大值的位置可用作每个特征点的位置的点估计。协方差矩阵可用于确定每个特征点位置的不确定性。
另外地或替代地,在一些实施方式中,可以以不存在特征点的位置的单点估计的方式来参数化每个特征点的位置上的估计概率分布。例如,每个特征点的位置上的概率分布可以是两个高斯的混合,其将通过两个均值和两个协方差矩阵来参数化。
对于输入图像200,基于在输入图像200中的每个特征点208的位置上的参数概率分布,确定全局特征点不确定性210。全局特征点不确定性210可以是概括输入图像200中所有个体特征点的估计位置的不确定性的单个标量度量(scalar measure)。基于全局特征点不确定性210,实施任务执行212。在一些实施方式中,任务执行基于每个特征点208的位置上的参数概率分布和全局标特征点确定性210两者。另外或替代地,在一些实施方式中,任务执行基于每个特征点204的估计位置和全局特征点不确定性。
在一些实施方式中,对于每个输入图像,控制器100可以将所确定的全局特征点不确定性与阈值进行比较。阈值可以是预定义的。如果输入图像的全局特征点不确定性小于阈值,则控制器100执行主要动作过程。然而,如果输入图像的全局特征点不确定性大于阈值,则控制器100执行可以与主要动作过程不同的辅助动作过程。
另外或替代地,在一些实施方式中,可以针对特征点的子集计算全局特征点不确定性。例如,如果对象是面部,则可以基于确定眼睛的位置的特征点的位置的不确定性来计算全局特征点不确定性。例如,对于依赖于知道眼睛的精确位置(例如,为了执行随后的注视方向估计)的应用来说,这可能是有利的。
图3示出了说明由一些实施方式使用的概率神经网络的原理的示意图。神经网络302处理输入图像300以输出由每个处理图像中每个特征点的位置的参数值定义的参数概率分布304。在概率分布304是高斯分布的情况下,这种分布的参数包括均值μ306和协方差矩阵Σ308。因为图像是多维的(例如,二维的),所以参数概率分布304的参数也是多维的。
每个特征点的参数概率分布304的不同参数定义310特征点的位置的点估计和每个特征点的位置估计的不确定性。例如,如图3所示,椭圆312的中心指示特征点的估计位置,而椭圆312的大小和形状指示每个方向上的不确定性的程度。例如,椭圆越大,不确定性就越大。在高斯概率分布的情况下,椭圆可以表示参数概率分布的等概率轮廓。
可以使用遵循利用链规则的基于梯度的优化算法的反向传播来训练神经网络302。反向传播的主要特征是其用于计算权重的更新以改进网络直到其能够执行正针对其训练的任务为止的迭代、递归和有效的方法。然而,不同的实施方式在神经网络的层结构、损失函数和优化技术之间变化,以提高特征点定位的精度。
图4A示出了根据一些实施方式的训练神经网络以估计特征点位置和位置估计的不确定性的示意图。由于在人脸图像上执行特征点位置的估计,因此将其称为面部对齐。人脸的输入RGB图像被应用于预训练的密集连接的U-网(DU-Net)400。每个U网被称为沙漏。向每个沙漏中添加两个组件402。第一组件用于将每个特征点的估计位置计算为对应于该特征点的热图的正元素的加权空间平均(例如,均值)404,其中,每个像素位置处的热图的值确定在空间平均中应用于该像素位置的权重。第二组件用于估计每个特征点位置的2D高斯概率分布的协方差矩阵406。第二组件从每个沙漏的瓶颈层出现。对于每个沙漏i和每个特征点j,特征点位置估计由μij给出,协方差矩阵由Σij给出。此外,特征点位置估计μij和协方差矩阵Σij通过损失函数绑定在一起408,损失函数实现整个面部对齐和不确定性估计系统的端到端优化。
在一些实施方式中,训练神经网络的方法是具有高斯对数似然损失的不确定性(UGLLI)方法,其是基于神经网络的方法。在一些实施方式中,UGLLI方法也被称为UGLLI模型。UGLLI方法产生更精确的结果。这将参照图6A至图8在说明书中详细进行解释。在一些实施方式中,利用UGLLI来针对每个图像获得每个特征点的位置上的参数概率分布和全局特征点不确定性。在这样的实施方式中,两个组件是均值估计器和Cholesky估计器网络(CEN)。均值估计器对应于第一组件,而Cholesky估计器网络对应于第二组件。在一些其他实施方式中,用于将特征点位置估计μij和协方差矩阵Σij绑定在一起的损失函数是高斯对数似然(GLL)损失函数与非参数内核密度网络模型不同,这里公开的不确定性估计方法是参数的,即直接估计单个高斯分布的参数。此外,一些实施方式基于高斯协方差矩阵不被约束为对角的认识。在一些实施方式中,可以使用其他参数模型来估计图像中每个特征点的概率分布,诸如拉普拉斯分布、多元指数分布或少量2D多元高斯的概率混合(高斯的混合)。此外,在一些实施方式中,UGLLI方法用于特征点定位问题,例如面部对齐、身体姿势估计等。
图4B示出了根据一些实施方式的用于针对每个输入图像获得每个特征点的位置上的参数概率分布的UGLLI方法。人脸的输入RGB图像410被输入到预训练的神经网络中,该神经网络的架构是密集连接的U-网(DU-Net)412。每个U-网被称为沙漏。在其他实施方式中,神经网络架构是沙漏网络的级联(即,序列),称为堆叠沙漏。UGLLI方法使用热图Hij442、443和444来估计每个特征点的位置(其为高斯参数概率分布的均值μij480),但不用于估计由高斯参数概率分布的协方差矩阵Σij470表示的每个特征点位置的不确定性。
在用于特征点回归(例如,面部对齐和身体姿势估计)的现有的基于热图的方法中,通过取相应热图的argmax(热图达到其最大值的像素位置)来获得每个估计的特征点位置。然而,argmax是不可微的(因此,用于特征点回归的现有网络不能以通常产生优异的结果的端到端方式训练),并且特征点位置被量化,因为特征点位置限于热图的底层网格的格点,从而产生特征点位置估计的次优精度。因此,UGLLI方法使用用于热图的均值估计器,而不是热图的argmax,因为均值函数是可微分的并且实现子像素精度。在一些实施方式中,在计算均值之前将函数σ应用于热图。在一些实施方式中,函数σ是整流线性单位(ReLU)函数,σ(X)=max(X,0),其限制在热图的仅正元素上取均值,而忽略热图的负元素。替代地或附加地,在一些实施方式中,可以在取均值之前应用不同的可微函数或次可微函数σ。例如,σ可以是softmax函数或温度控制的softmax函数,其可以用于将均值主要集中在热图取其最大值的位置上。
例如,在一个实现方式中,神经网络包括沙漏子网络422、423和424的堆叠412。每个沙漏从沙漏的最后、最大特征映射层432、433和434输出每个特征点的热图Hij442、443和444。热图是指示特征点的位置的强度图像,并且使用热图的正值的位置的加权均值来获得对应特征点的参数概率分布的均值442、443和444。另外,沙漏子网络422、423和424具有来自瓶颈、最小特征层452、453和454的第二输出。瓶颈层的特征值由称为Cholesky估计器网络(CEN)462、463和464的子网络处理,以产生下三角矩阵Lij468,其中,从Lij及其转置469的乘积获得每个特征点的参数概率分布的协方差矩阵Σij470。
例如,考虑Hij(x,y),其表示来自第i沙漏的第j特征点的热图的在像素位置(x,y)处的热图值。特征点的位置估计μij=[μijx,μijy]T480是通过用函数σ对热图Hij的像素进行后处理并随后取后处理结果的加权空间均值而给出的。对于函数σ考虑各种函数,例如整流线性单位(ReLU)函数、softmax函数、温度控制softmax函数等。ReLU函数消除了热图的负值。softmax函数将均值估计器修改为热图的argmax的软版本。取决于温度设置,温度控制的softmax函数提供从硬argmax到均匀分布的softmax函数的连续体。在一些实施方式中,观察到选择函数σ为ReLU函数产生最简单且精确的均值估计器。通过取空间均值从正热图估计特征点位置可以被认为是2D高斯分布均值的最大似然估计(MLE)。在规则网格上采样2D高斯分布的均值,其中热图值表示每个网格位置处的采样频率。
一些实施方式基于这样的认识,即直接从热图计算协方差矩阵产生不精确的结果,因为许多图像包含可以非常精确地定位的一些特征点,并且这些特征点位置的不确定性在至少一个方向上非常小(像素的分数)。每个特征点位置的不确定性被表示为具有协方差矩阵Σij470(2×2对称正定矩阵)的高斯分布。协方差矩阵Σij470具有通过其Cholesky分解捕获的三个自由度,即,下三角矩阵Lij468,使得其中,指示Lij的转置。
为了估计下三角矩阵Lij468,从每个沙漏的瓶颈添加了Cholesky估计器网络(CEN)。CEN是一个完全连接的线性层,其输入是沙漏的瓶颈,可以具有例如128×4×4=2048维度,其输出是Np×3维度的矢量,其中,Np是特征点的结构化集合中特征点的数量。例如,如果特征点的数量是68,则CEN的输出具有68×3=224维度。如果下三角矩阵Lij包括正对角元素的话,下三角矩阵Lij是协方差矩阵的Cholesky分解。为了确保下三角矩阵Lij468包括正对角元素,指数线性单位(ELU)激活函数被应用于下三角矩阵Lij的第一元素和第三元素。在一些实施方式中,利用具有常数的ELU函数来确保下三角矩阵Lij包括正对角元素。
给定在每个沙漏i处的输入图像的特征点的估计高斯分布,特征点j在图像位置pj处的可能性由下式给出:
其中矩阵Σij的行列式标记为|Σij|,μij为特征点的估计位置。
因此,对于每个输入图像中的每个特征点,神经网络输出由μij和Lij参数化的高斯分布。
神经网络被训练以提供从输入图像到高斯分布的映射,使得真实特征点位置(在所有特征点和所有训练图像上)的可能性尽可能大。使似然(1)最大化等同于使负对数似然最小化。因此,负对数似然度被用作损失函数。对于特征点j,在每个沙漏i处的损失函数可以被写为两个项T1和T2的和:
其中,T1用作确保高斯不确定性分布不会变得太大的正则化项(regularization term),并且T2是真实特征点位置pj的平方马哈拉诺比斯距离。在一些实施方式中,训练图像中的真实特征点位置pj是人类专家标签者指示特征点j在训练图像中所位于的位置。如果协方差矩阵Σij是单位矩阵,则式(2)缩减为估计的特征点位置μij和真实特征点位置pj之间的标准距离(即欧几里得距离)。
通过对所有特征点(1,...,Np)上的损耗进行平均来获得单个沙漏的目标函数,并且每个输入图像的总损耗是每个沙漏i的损耗的加权和,由下式给出:
其中,
在一些实施方式中,在测试时间,仅从最终沙漏K424导出每个特征点的估计均值和协方差矩阵。
图5示出了特征点位置估计的示例性结果和测试图像上的位置估计的不确定性。在图像500、502和504中,白点表示真实特征点位置,黑点表示估计的特征点位置。椭圆表示特征点的估计位置的估计不确定性,即,基于定义特征点j的高斯概率分布的估计均值和协方差矩阵参数,具有等于1的马哈拉诺比斯距离的位置pj的轮廓。更大的椭圆(例如图像502中手上的椭圆)表示更大的不确定性,并且类似地,更小的椭圆(例如,图像500中鼻子上的椭圆)表示更小的不确定性。观察到被遮挡(例如,由图像502中的手遮挡)的特征点趋向于具有更大的不确定性,这指示特征点位置的不确定性的估计正确地确定了被遮挡的特征点的估计位置更不确定。
图6A是在300-W公共、挑战和完整数据集(分叉1)上的不同方法之间的归一化均值误差(NME)比较的图表。针对被称为300-W分叉1的训练/测试集对的面部对齐结果或特征点位置估计汇总在图5的图表中,并且被报告为在300W公共子集、挑战子集和完整数据集上在测试集中的所有图像上进行平均的NME。由图5的图表中的结果可以观察到,本文公开的UGLLI方法在面部对齐方面优于一些其他最近的方法。除了产生特征点位置的最精确的点估计(由UGLLI方法输出的高斯参数概率分布的均值)之外,UGLLI方法以高斯参数概率分布的协方差矩阵的形式提供每个估计的特征点位置的不确定性的估计。图6A中的其他方法均没有提供对其特征点位置估计的不确定性的估计。
图6B是在300-W测试(分叉2)和Menpo数据集上在不同方法之间的归一化均值误差(NME)和曲线下面积(AUC)比较的图表。在图5的图表中汇总了被称为300-W分叉2的训练/测试集对的面部对齐结果或特征点位置估计。此外,图6B的图表示出了Menpo数据集(具有68个特征点的6679个正面训练图像)上的模型(在分叉2上训练)的结果。根据图6B中的结果,显然UGLLI方法明显优于其他方法。
确定测量图像中每个特征点的位置估计的不确定性的标量(scalar quantity)。此外,将图像中所有特征点的位置估计的这种不确定性的值进行组合,以获得整个图像的单个标量全局特征点不确定性值。在一些实施方式中,从特征点位置上的高斯概率分布的协方差矩阵获得每个特征点的位置估计的不确定性。
例如,特征点的位置估计的不确定性可以是协方差矩阵的特征值的平均值。在一些实施方式中,协方差矩阵的行列式的第n根(例如行列式的平方根或第四根)被用作特征点的位置估计的不确定性。在一个实施方式中,从最终沙漏估计的协方差矩阵的行列式的第四根K被用作每个特征点的位置估计的标量不确定性,即,|∑Kj|1/4。
图7示出了相对于所有300-W测试图像上的特征点位置的点估计的归一化误差的位置估计的归一化不确定性的绘图(分叉2)。在绘图700中,每个点表示一个图像中的一个特征点,并且每个点的y坐标表示该特征点的位置估计的不确定性的归一化版本。在绘图702中,每个点表示一个图像中所有特征点的平均值,并且每个点的y坐标表示图像的全局特征点不确定性。这里,图像的全局特征点不确定性被计算为位置估计的归一化不确定性在图像中的所有特征点上的均值。每个绘图的写在每个绘图的顶部的皮尔逊相关系数表明我们预测的不确定性与实际误差高度相关。
观察到,绘图702中的相关系数大于绘图700的相关系数。换句话说,尽管图像中每个特征点的特征点位置的不确定性是该特征点的估计位置的误差的良好预测器,但是图像的全局特征点不确定性是(图像的平均特征点定位误差的)更好的预测器。此外,图像的全局特征点不确定性具有显著更高的相关系数。因此,在一些实施方式中,图像的全局特征点不确定性被应用为用于任务执行的控制器的输入,而不是使用每个单独特征点的特征点位置的不确定性。
图8是示出使用在300-W分叉2上训练的UGLLI方法对300-W测试和Menpo数据集进行消融研究(ablation study)的图表。图8的图表表明,在训练期间仅在最后的沙漏(HG)上计算损失函数比在训练期间在所有沙漏上计算损失导致网络更低效且更不精确地执行,这可能是因为其改善了消失梯度问题。此外,UGLLI方法的高斯对数似然(GLL)损失优于在特征点位置上使用均方误差(MSE)损失(等效于将估计的协方差矩阵设置为单位矩阵,Σij=I)。对于均值估计器,使用直接回归(直接)从每个沙漏的瓶颈层获得均值(而不是使用热图)是低效的。这可能是因为神经网络可以产生连续实值的不可靠预测。除了ReLU函数外,还比较了σ的另外两个函数,即软argmax(s-amax)和温度标度的软argmax(τ-s-amax)。温度标度的软argmax和ReLU的结果基本上是绑定的,但是温度标度的软argmax更复杂,并且需要调整温度参数。因此,在一些实施方式中,为UGLLI方法选择ReLU函数。
图9A示出了根据一些实施方式的使用不确定性反馈来改进特征点定位的示意图。将UGLLI模型应用于图像集合900。根据UGLLI模型的输出,估计图像集合中的每个图像的全局特征点不确定性902。根据图像集合的每个图像的估计的全局特征点不确定性,选择全局特征点不确定性高于阈值的图像904。在一些实施方式中,阈值是预定义的。所选择的图像(即,其全局特征点不确定性高于阈值的图像)是估计的特征点位置被估计为最不确定的图像,因此这些图像是特征点定位最需要改进的图像。为了改进所选图像的特征点估计,将UGLLI模型多次应用于每个所选图像,每次使用不同的随机扰动906。例如,在一些实施方式中,随机扰动906被应用于用于对算法初始化的面部框。在一些实施方式中由诸如Viola-Jones面部检测算法的自动面部检测器确定的面部框被用于初始缩放、平移、旋转或以其他方式变换对象的图像(例如,经由2D仿射变换)以用于输入到神经网络中。将随机扰动应用于面部框的位置、比例、旋转角和纵横比中的一个或更多个导致方法的初始化稍微不同,这也导致方法的输出稍微不同。特别地,一些初始化导致更精确估计的特征点位置。
对于每个选择的图像,通过UGLLI模型馈送图像的多个扰动版本,并且计算图像的每个扰动版本的全局特征点不确定性。比较图像的所有扰动版本的全局特征点不确定性908,然后从产生最小全局特征点不确定性的扰动中选择结果910。观察到,这些最终结果的特征点位置估计比方法的原始特征点位置估计具有更小的归一化均值误差(NME)。换句话说,因此,由于不确定性反馈,减少了特征点位置估计的平均误差。另外地或替代地,可以应用不同类型的随机扰动。例如,在神经网络的某些层处的特征值可以被随机扰动。
图9B示出了没有不确定性反馈和具有不确定性反馈的特征点位置估计和特征点位置估计的不确定性的示例性结果。在图9B中,图像912是没有不确定性反馈的特征点位置估计和特征点位置估计的不确定性的结果。图像914是使用不确定性反馈的特征点位置估计和特征点位置估计的不确定性的结果。在图像912和914中的每一个中的特征点上平均的NME(%)以及预测不确定性(UCA)的值分别显示在图像的顶部。根据图9B中的结果,很明显,与初始结果(即,没有不确定性反馈912的结果)相比,具有不确定性反馈914的结果具有更小的误差。
图10示出了根据一些实施方式的用于在车辆驾驶员监控环境中根据概率性的基于图像的特征点定位来执行任务的示意图。在车辆驾驶员监控环境1000中,车辆驾驶员1002正在驾驶车辆1004,并且需要监控车辆驾驶员1002的生命体征(面部对齐和身体姿势对齐的一个或更多个)。在一些示例实施方式中,视频跟踪方法被应用于面部跟踪或人类姿势跟踪。在这种情况下,基于视频的特征点跟踪可以是最终任务,或者基于视频的特征点跟踪可以是结果用于后续下游任务的中间任务。这里,考虑视频面部对齐(即,面部跟踪)以便于描述实施方式。然而,在一些实施方式中,还考虑其他视频跟踪应用,包括视频人类姿势估计(即,人类姿势跟踪)。
相机1006被配置为捕获视频并将捕获的视频转换成帧(即,图像)的时间序列。控制器1008被配置为对图像的时间序列中的图像执行概率性的基于图像的特征点定位(例如,UGLLI方法)。基于图像的特征点定位通过由诸如Viola-Jones面部检测算法的自动面部检测器给出的面部框1010初始化。面部框1010覆盖车辆驾驶员1002的整个面部。在一些实施方式中,面部框覆盖车辆驾驶员1002的整个面部的显著部分,例如面部的包含特征点的部分。
对于序列中的第一图像(视频的第一帧),使用由自动面部检测器给出的第一面部框来对基于图像的特征点定位进行初始化。基于图像的特征点定位输出第一图像的特征点估计和全局不确定性估计。
基于这些输出,控制器1008确定特征点定位和任务执行的质量。在一些实施方式中,如果第一图像的估计的全局特征点不确定性低于阈值,则控制器1008确定第一图像中的特征点定位的质量良好,并且执行主要动作过程。在一些实施方式中,主要动作过程包括使用由来自第一帧的估计的特征点位置确定的第二面部框来对序列的第二图像的基于图像的特征点定位进行初始化。
在一些实施方式中,如果第一图像的估计的全局特征点不确定性低于阈值,则控制器1008确定第一图像中的特征点定位的质量较差,并且执行辅助动作过程。在一些实施方式中,辅助动作过程包括使用由自动面部检测器给出的第二面部框来对第二图像的基于图像的特征点定位进行初始化。
在一些实施方式中,基于图像的特征点估计器用于使用贝叶斯滤波器(例如卡尔曼滤波器)的面部特征点跟踪。
图11示出了结合基于图像的参数概率性特征点定位使用贝叶斯滤波器(例如卡尔曼滤波器)用于概率性特征点跟踪的示意图。在一些实施方式中,诸如UGLLI方法的基于图像的特征点定位为图像序列中的每个输入图像k 1118中的每个特征点提供高斯概率分布1112。利用图像序列中的每个输入图像中的每个特征点的高斯概率分布1112作为从输入图像1118获得的噪声测量,该高斯概率分布1112由均值μk1116和协方差矩阵Σk1114参数化。此外,使用卡尔曼滤波器来组合时间步长序列上的每个特征点的高斯概率分布1112,以获得图像k 1118中特征点的位置上的最终高斯概率分布1110。该高斯概率分布1110通过特征点位置的点估计(即,均值xk 1108)和特征点位置的估计的不确定性(其为协方差矩阵Pk1106)来参数化。该概率分布1110被称为由卡尔曼滤波器针对图像序列中的每个图像k输出的高斯分布。对于图像序列中的每个图像,卡尔曼滤波器的输出估计1110被用作控制器的任务执行的参数概率分布。
在一些实施方式中,控制器还被配置为基于卡尔曼滤波器使用针对图像序列中的第一图像确定的高斯概率分布来更新针对图像序列中的第二图像确定的高斯概率分布。然后,将卡尔曼滤波器针对每个输入图像(每个时间步长)的输出估计1110用于后续图像(后续时间步长),作为状态1110的先验知识(即,先验概率分布),并且在后续时间步长中使用来自每个时间步长的输出均值1108和协方差矩阵1106,作为先验分布1100的均值1104和协方差矩阵1102。由于若干原因,随着时间推移使用滤波(例如卡尔曼滤波)是有利的。首先,其可以提高特征点位置和不确定性估计的精度。第二,其可以适当地使用每个图像的估计的不确定性,使得具有较大不确定性的估计1112将较少地影响输出特征点估计1110,而具有较小不确定性的估计1112将更多地影响输出特征点估计1110。
以上描述仅提供示例性实施方式,并不旨在限制本公开的范围、适用性或配置。相反,示例性实施方式的以上描述将向本领域技术人员提供用于使得能够实现一个或更多个示例性实施方式的描述。预期可在不脱离所附权利要求书中所阐述的公开主题的精神和范围的情况下对元件的功能和布置进行各种改变。
在以上描述中给出具体细节以提供对实施方式的全面理解。然而,如果本领域普通技术人员理解,则可以在没有这些具体细节的情况下实践实施方式。例如,所公开的主题中的系统、过程和其他元件可以以框图形式示出为组件,以便不以不必要的细节使实施方式模糊。在其他实例中,可在没有不必要细节的情况下示出众所周知的过程、结构及技术以避免使实施方式模糊。此外,各个附图中相同的附图标记和标号指示相同的元件。
而且,可以将各个实施方式描述为被描绘为流程表、流程图、数据流图、结构图或框图的过程。尽管流程图可将操作描述为顺序过程,但许多操作可并行或同时执行。另外,可以重新排列操作的顺序。过程可在其操作完成时终止,但可具有未在图中论述或未包括的额外步骤。此外,并非在所有实施方式中都会出现任何特别描述的过程中的所有操作。过程可以对应于方法、函数、进程、子例程、子程序等。当过程对应于函数时,函数的终止可以对应于函数返回到调用函数或主函数。
此外,所公开的主题的实施方式可以至少部分地手动或自动地实现。可通过使用机器、硬件、软件、固件、中间件、微代码、硬件描述语言或其任何组合来执行或至少辅助手动或自动实施方案。当在软件、固件、中间件或微代码中实现时,用于执行必要任务的程序代码或代码段可以存储在机器可读介质中。处理器可以执行必要的任务。
本文概述的各种方法或过程可被编码为可在采用各种操作系统或平台中的任何一个的一个或更多个处理器上执行的软件。另外,这样的软件可以使用许多合适的编程语言和/或编程或脚本工具中的任何一种来编写,并且还可以被编译为在框架或虚拟机上执行的可执行机器语言代码或中间代码。通常,在各种实施方式中,程序模块的功能可以根据需要进行组合或分布。
本公开的实施方式可以实施为一种方法,已经提供了该方法的示例。作为方法的一部分执行的动作可以以任何合适的方式排序。因此,可以构建其中以不同于所示出的顺序执行动作的实施方式,所述顺序可包括同时执行一些动作,虽然在说明性实施方式中示出为顺序动作。
虽然已经参考某些优选实施方式描述了本公开,但是应当理解,在本公开的精神和范围内可以进行各种其他的改编和修改。因此,所附权利要求的方面覆盖了落入本公开的真实精神和范围内的所有这些变化和修改。
本文用于企业家、创业者技术爱好者查询,结果仅供参考。