1.本发明涉及智能车辆领域,尤其涉及一种基于声源定位的智能座舱人机交互方法。
背景技术:
2.随着电动车的蓬勃兴起,在小型客车内配置大显示器、高性能的主机已经慢慢普及。但是,相关的周边软件部分还属于起步阶段,例如,目前与电动车座舱配套的游戏非常少。这其中还有一个重要的原因是,受限于座舱的环境,一般不会配置鼠标、手柄等输入装置,而通过触摸屏的方式也对使用者的位置有较高的要求,而且游戏体验不佳。如何提高座舱内进行人机交互的方便性,提高游戏体验是目前亟待解决的技术问题。另一方面,通过语音实现人机交互,控制智能设备的方式已经非常成熟,客车内也有普及的趋势。例如,通过语音唤醒车载导航、甚至控制车内的智能空调等智能设备都有现实的应用。目前,通过语音实现人机交互多采用语音识别引擎进行语义识别,从而准确判断操作者的指令意图。相关语音识别引擎也非常成熟,其最快甚至能在0.7秒内准确识别出操作者的指令。但是,对于游戏而言,0.7秒的响应速度仍有不足,尤其是对于动作类的游戏。如何进一步加快语音的识别速度,实现快速的人机交互是目前亟待解决的技术问题。另一方面,现有的智能座舱很难实现多人同时操作,相应的多人游戏也很难应用在智能座舱中。
技术实现要素:
3.本发明的目的在于提供一种高速、高效、可多点多人控制的基于声源定位的智能座舱人机交互方法。
4.为实现上述目的,本发明提供如下技术方案:
5.基于声源定位的智能座舱人机交互方法,其包括智能座舱,所述智能座舱内设置有若干个用于采集声音的声音撷取装置以及至少一个主机;其还包括若干个用于人机交互操作的命令及预先设置好的命令列表,所述命令列表中包括全部的所述命令以及与每个所述命令对应的声源位置;还包括在所述主机内运行的对声音进行处理并获取声源位置的声音定位模块、对所获得的声源位置与所述命令列表进行比对以获得对应的命令的控制模块;其包括以下步骤:
6.s100、通过声音撷取装置获取工作环境中的声音;
7.s101、所述声音定位模块对所获得的声音进行处理,以获取声源位置;
8.s102、所述控制模块根据所述声源位置在所述命令列表检索得到对应的所述命令;
9.s103、根据所述命令与所述主机进行交互操作。
10.优选的,所述命令列表中还包括与每个所述命令对应的指令音素序列,其还包括一对所述声音撷取装置采集的声音进行音素比较、从而获得对应的命令的命令识别方法;
11.该命令识别方法包括以下步骤:
12.3.1)通过声音撷取装置获取工作环境中的声音;
13.3.2)通过所述声音处理引擎获取步骤3.1)获取的声音进行处理,去除其中的背景噪音,获得其中的控制声音;
14.3.3)通过所述声音识别引擎将步骤3.2)中得到的所述控制声音进行识别,将所述控制声音转换音素,并将其按顺序组成所述待识别音素序列;
15.3.4)通过所述控制模块将所述待识别音素序列与所述命令列表中的指令音素序列进行比对,以获取其中对应的所述命令或比对失败标志;其包括以下步骤:
16.3.4.1)从所述命令列表提取一所述命令,并将其对应的指令音素序列作为待比对的指令音素序列;
17.3.4.2)通过将所述待识别音素序列中的音素按顺序逐一与待比对的指令音素序列中的音素进行比对;如比对结果不一致则执行3.4.3),如比对结果一致则执行3.4.4);
18.3.4.3)取出所述命令列表中下一个所述命令,并将其对应的指令音素序列作为待比对的指令音素序列,并执行3.4.2);如果所述命令列表中的全部所述命令均已比对完,则输出识别失败标志;
19.3.4.4)计数器计数,并进行下一个音素的比较,直至一致的音素数量超过预设的阈值,则将待比对的所述命令作为比对结果输出,并将计数器清零;如果其中任一音素比对结果不一致,则将计数器清零,并执行3.4.3)。
20.优选的,预先设置所述命令列表的方法包括以下步骤:
21.1.1)录入所述命令对应的声音;
22.1.2)由声音识别引擎将所述命令对应的声音转换为若干个音素;
23.1.3)将上述音素中的全部或部分音素按顺序组合后得到指令音素序列;
24.1.4)将所述命令与其对应的指令音素序列存储为所述命令列表。
25.优选的,其还包括以下步骤:
26.2.1)在训练环境下,模拟控制声音,并通过声音撷取装置获取声音,然后对所述声音处理引擎进行训练,其训练的内容包括去除声音撷取装置获取的声音中的背景噪音,从中提取所述控制声音;所述控制声音由若干个单词或字或响声组成;
27.2.2)在训练环境下,对声音识别引擎进行训练,其训练的内容包括将所述声音处理引擎得到所述控制声音转换音素,将其按顺序组成待识别音素序列;所述待识别音素序列是由若干个音素按顺序组成的音素序列。
28.优选的,所述步骤2.1)包括以下步骤:
29.2.1.1)去噪,在训练环境下模拟各类背景噪音,并训练所述声音处理引擎去除所述背景噪音。
30.优选的,所述步骤3.2)包括以下步骤:
31.3.2.1)去噪,通过所述声音处理引擎去除工作环境中的背景噪音,将其获得的声音作为所述控制声音;
32.3.2.2)如果所述控制声音为连续声音,则将其连续地输送给所述声音识别引擎;否则则将其完整地输送给所述声音识别引擎;
33.3.2.3)如果所述控制声音为连续声音,则所述声音识别引擎将输入的所述控制声音连续地送入所述控制模块,由所述控制模块依次执行步骤3.3)和3.4),以进行命令识别;
其中,如果所述控制模块返回识别失败标志则将其返回给所述声音处理引擎,所述声音处理引擎停止将后续的所述控制声音输送给所述声音识别引擎,直至所述控制声音出现停顿后再出现新的所述控制声音。
34.优选的,其还包括声音输出装置,所述步骤3.2.1)中的背景噪音包括所述声音输出装置输出的声音。
35.优选的,所述阈值为1~5。
36.优选的,所述声音包括鼓掌、拍击身体部位或敲击所述智能座舱发出的声音、以及操作发声装置发出的声音。
37.本发明的有益效果:通过声源的位置来对应不同的操作命令,实现多人或多点的人机交互;还可以通过将语音转换为音素,其可以通过部分音素直接进行命令识别,从而减少了语义识别的过程,其既简化了识别引擎的复杂程度,也大大提高了识别的速度。
附图说明
38.图1为本发明的应用示例的原理示意图。
39.图2为本发明的应用示例的流程示意图;
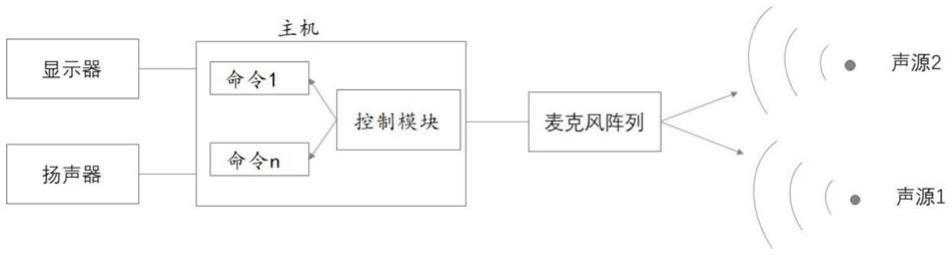
40.图3为本发明的应用示例的流程示意图。
具体实施方式
41.下面结合具体实施方式对本专利的技术方案作进一步详细地说明。
42.在本发明的描述中,需要说明的是,术语“内”、“外”、“上”、“下”、“水平”等指示的方位或位置关系为基于附图所示的方位或位置关系,仅是为了便于描述本发明和简化描述,而不是指示或暗示所指的装置或元件必须具有特定的方位、以特定的方位构造和操作,因此不能理解为对本发明的限制。
43.如图1所示,本发明的基于声源定位的智能座舱人机交互方法,其包括智能座舱,智能座舱内设置有若干个用于采集声音的声音撷取装置以及至少一个主机,还可以配置显示器和扬声器;其还包括若干个用于人机交互操作的命令及预先设置好的命令列表,命令列表中包括全部的命令以及与每个命令对应的声源位置;还包括在主机内运行的对声音进行处理并获取声源位置的声音定位模块、对所获得的声源位置与命令列表进行比对以获得对应的命令的控制模块;其包括以下步骤:
44.s100、通过声音撷取装置获取工作环境中的声音;
45.s101、声音定位模块对所获得的声音进行处理,以获取声源位置;
46.s102、控制模块根据声源位置在命令列表检索得到对应的命令;
47.s103、根据命令与主机进行交互操作。
48.其工作原理是,采用多个声音撷取装置,如麦克风,组成立体的阵列,采集声音并可判断声源的位置。相关的可直接判断声源位置的智能麦克风阵列已有成熟的技术,根据需要合理使用即可。本发明也可以根据不同麦克风对同一声音采集的强弱等特征,经过合理的算法进行计算,从而推断出声源的位置。相关的算法也是业界所成熟的技术,因而本发明未详细揭示。本发明的控制模块根据声源位置在命令列表检索得到对应的命令,从而控制主机进行操作。例如,在跳跃类游戏中,操作者可以通过拍击左右腿,来控制游戏中的角
色向左跳或向右跳。当然,也可以根据不同的位置,实现多人各自控制多角色的游戏。进一步地,声音撷取装置采集的声音也送入控制模块,控制模块还可以根据输入的声音的位置、音量、时长、声音类型来进行相应的命令操作,例如将副驾上发出的鼓掌声转换为鼓声,并通过扬声器进行同步输出;将主驾上发出的拍腿声转换为钹声,并通过扬声器进行同步输出,从而实现乐器合奏。
49.进一步地,命令列表中还包括与每个所述命令对应的指令音素序列,其还包括一对所述声音撷取装置采集的声音进行音素比较、从而获得对应的命令的命令识别方法。本发明的基于声源定位的智能座舱人机交互方法,其包括若干个用于人机交互操作的命令,其还包括预先设置好的命令列表,命令列表中包括全部的命令以及与每个命令对应的指令音素序列;还包括一用于采集声音的声音撷取装置、对声音进行处理的声音处理引擎、对处理后的声音进行识别的声音识别引擎、对识别后的声音与命令列表进行比对的控制模块。上述模式,进一步为多人操作游戏提供了方便,客车内,不同位置的操作者,通过语音控制不同的角色,从而完美实现多人控制,提高了娱乐性。
50.该命令识别方法包括预先准备的步骤(其类似出厂前的工作),以及实际工作的步骤。其中,预先准备的步骤包括:
51.预先设置命令列表的步骤:
52.1.1)录入命令对应的声音;
53.1.2)由声音识别引擎将命令对应的声音转换为若干个音素;
54.1.3)将上述音素中的全部或部分音素按顺序组合后得到指令音素序列;
55.1.4)将命令与其对应的指令音素序列存储为命令列表。
56.其还包括对引擎进行训练的步骤,以提高识别效率和准确度:
57.2.1)在训练环境下,模拟控制声音,并通过声音撷取装置获取声音,然后对声音处理引擎进行训练,其训练的内容包括去除声音撷取装置获取的声音中的背景噪音,从中提取控制声音;控制声音由若干个单词或字或响声组成;其中包括步骤:
58.2.1.1)去噪,在训练环境下模拟各类背景噪音,并训练声音处理引擎去除背景噪音。
59.2.2)在训练环境下,对声音识别引擎进行训练,其训练的内容包括将声音处理引擎得到控制声音转换音素,将其按顺序组成待识别音素序列;待识别音素序列是由若干个音素按顺序组成的音素序列。
60.实际工作的步骤包括:
61.3.1)通过声音撷取装置获取工作环境中的声音;
62.3.2)通过声音处理引擎获取步骤3.1)获取的声音进行处理,去除其中的背景噪音,获得其中的控制声音;
63.3.3)通过声音识别引擎将步骤3.2)中得到的控制声音进行识别,将控制声音转换音素,并将其按顺序组成待识别音素序列;
64.3.4)通过控制模块将待识别音素序列与命令列表中的指令音素序列进行比对,以获取其中对应的命令或比对失败标志;其包括以下步骤:
65.3.4.1)从命令列表提取一命令,并将其对应的指令音素序列作为待比对的指令音素序列;
66.3.4.2)通过将待识别音素序列中的音素按顺序逐一与待比对的指令音素序列中的音素进行比对;如比对结果不一致则执行3.4.3),如比对结果一致则执行3.4.4);
67.3.4.3)取出命令列表中下一个命令,并将其对应的指令音素序列作为待比对的指令音素序列,并执行3.4.2);如果命令列表中的全部命令均已比对完,则输出识别失败标志;
68.3.4.4)计数器计数,并进行下一个音素的比较,直至一致的音素数量超过预设的阈值,则将待比对的命令作为比对结果输出,并将计数器清零;如果其中任一音素比对结果不一致,则将计数器清零,并执行3.4.3);其中,阈值通常为1~5,其根据命令的不同来设置,以实现不需要完整比对音素列表即可找到对应的命令。
69.其中:
70.步骤3.2)包括以下步骤:
71.3.2.1)去噪,通过声音处理引擎去除工作环境中的背景噪音,将其获得的声音作为控制声音;
72.3.2.2)如果控制声音为连续声音,则将其连续地输送给声音识别引擎;否则则将其完整地输送给声音识别引擎;
73.3.2.3)如果控制声音为连续声音,则声音识别引擎将输入的控制声音连续地送入控制模块,由控制模块依次执行步骤3.3)和3.4),以进行命令识别;其中,如果控制模块返回识别失败标志则将其返回给声音处理引擎,声音处理引擎停止将后续的控制声音输送给声音识别引擎,直至控制声音出现停顿后再出现新的控制声音。例如,如果座舱内有人在说非控制且连续的话,则声音识别引擎通过前几个字即可获知,其非控制命令,而后续连续的声音则被声音处理引擎所丢弃,以节约资源。如果中间发生停顿,则返回初始状态,等待声音输入,以进行识别。
74.进一步地,其还包括声音输出装置,步骤3.2.1)中的背景噪音包括声音输出装置输出的声音,这使得其可以将游戏本身通过扬声器输出的声音作为背景噪音,从而被排除。
75.本发明还提供一种游戏座舱,其包括至少一个座位,还包括声音输出装置、显示器、至少一个声音撷取装置以及运行游戏的主机,主机采用基于声源定位的智能座舱人机交互方法将游戏玩家的声音转换为控制游戏的命令,并依据命令执行游戏操作。
76.游戏玩家的声音包括鼓掌、拍击身体部位或敲击客车部位发出的声音、以及操作发声装置(例如铃铛)发出的声音。
77.如图1所示,以常见的游戏指令stop举例来说明,本发明的工作原理及流程是:
78.首先由声音撷取装置(例如麦克风)获取用户stop的声音,然后声音识别引擎将其转换为/s、/t、/oh、/p的音素列表。声音识别引擎将声音转换为音素为业界所熟知的技术,相关的算法非常成熟,可参考专利201711082646.9。预先设置好的命令列表中,有对应的音素序列,通过简单的比对,即可找出对应的指令stop。游戏中,操作指令数量较少,因而有可能在比对出/s或/s、/t后即可获得唯一的操作指令stop,从而去控制游戏,达到快速识别的目的。阈值根据操作指令的不同来确定,如果3个音素即可唯一确定出不同的操作指令,则阈值设为3,这就可以减少音素比对的数量,避免不必要的多余比对,以进一步提高速度。
79.如图2所示,以常见的游戏指令left、right、stop、start举例来说明,本发明的工作原理及流程是:声音识别引擎首先将声音转换为音素序列/left、/right、/stop、/start;
然后通过一个简单筛选,例如比对上/s,则进一步比对/t;其还不能得到唯一的命令,则进一步比对/o或/a,从而获得唯一的命令。针对上述几个命令,此时阈值可以设置为3,通过3个音素的比对,肯定可以获得唯一的命令。比对/left、/right同理,实际上只需要一个音素即可,即/l和/r,最多比到阈值3时,即可返回结果,而放弃比对其他的命令,从而提高比对的速度。
80.以上所述仅为本发明的实施例,并非因此限制本发明的专利范围,凡是利用本发明说明书及附图内容所作的等效结构或等效流程变换,或直接或间接运用在其它相关的技术领域,均同理包括在本发明的专利保护范围内。
再多了解一些
本文用于企业家、创业者技术爱好者查询,结果仅供参考。