1.本发明涉及一种无人驾驶铰接式清扫车的横向控制方法。
背景技术:
2.无人驾驶是ai技术集大成者,也是当前人工智能最具挑战、最有吸引力的领域之一。自上世纪70年代起,无人驾驶经历了技术研究的兴起、可行性和实用性方面的进展等阶段,而目前,无人驾驶行业也已然逐步进入到了市场商业化的阶段。不过,由于相应的法律法规等一系列手续还未完善,载人的无人驾驶商业化也许还需要一些时间,而无人驾驶清扫车由于其工作环境与无人驾驶乘用车不同,它一般在特定场景下行驶,车速较低,相较于无人驾驶乘用车可以更好的落地开展使用。
3.现阶段大多数用于城市环卫的清扫车多为铰接式清扫车,铰接式清扫车的结构如图1所示,其中1为清扫车前部,2为清扫车后部,3为铰接装置,铰接式转向结构的一大优点是实现更高机动性。借助此系统,吸入口始终朝向行进方向,确保清扫干净彻底,不会留下难看的污垢痕迹。清扫车的后部跟随前部的确切路径,让驾驶员专注于前方任务。但是铰接式清扫车独特的转向结构相对于传统前桥转向结构,在原地转向过程中前后车体相对地面都存在运动,使得其横向控制变得复杂。
4.在实际横向控制过程中,应用得比较广泛的是pid控制(比例,积分,微分控制)。它因为结构简单,稳定性好而成为当今工业控制的主流技术之一。但对于无人驾驶铰接式车辆系统这样的大惯性的系统,由于负载扰动或者环境变化,模型的结构或受控参数易于发生了变化,使得常规pid控制的性能也就随之降低,适应性变差,无人驾驶铰接式清扫车运行过程中的横向控制精度和响应速度也无法得到保证。
技术实现要素:
5.为了解决上述技术问题,本发明提供一种算法简单、控制精度高的无人驾驶铰接式清扫车的横向控制方法。
6.本发明解决上述问题的技术方案是:一种无人驾驶铰接式清扫车的横向控制方法,包括以下步骤:
7.步骤1:初始化控制器的各个参数;
8.步骤2:由建立的无人驾驶铰接式清扫车的转向模型以及运动过程的路径示意图得知无人驾驶铰接式清扫车在横向控制过程中受横向位置偏差ε
d
,航向角偏差ε
θ
和曲率偏差ε
c
影响,通过高精定位模块和高精定位算法获得横向位置偏差ε
d
,航向角偏差ε
θ
和曲率偏差ε
c
;
9.步骤3:将横向位置偏差ε
d
,航向角偏差ε
θ
和曲率偏差ε
c
写成误差向量e(t),e(t)=[ε
d ε
θ ε
c
]
t
,将误差向量通过状态转换器转换为系统状态矩阵x(t),x(t)=[e(t) δe(t) δ2e(t)]
t
,其中δe(t)=e(t)
‑
e(t
‑
1)为e(t)的一次差分δ2e(t)=e(t)
‑
2e(t
‑
1) e(t
‑
2)为e(t)的二次差分;
[0010]
步骤4:计算actor
‑
critic的回报函数r(t),同时状态矩阵x(t)作为rbf网络的输入,经过隐含层与输出层的计算,输出未经修正的初步pid参数值k'(t)及critic的值函数v
(t)
;
[0011]
步骤5:初步pid参数值k'(t)经修正器修正后,得到最终的pid参数k(t),由机载电脑的计算单元计算得到此最终pid控制量作用下的无人驾驶铰接式清扫车的横向输出值u(t);
[0012]
步骤6:通过迭代计算得到将横向输出值u(t)作用于无人驾驶铰接式清扫车,预测下一时刻无人驾驶铰接式清扫车的横向输出值y(t 1)和回报r(t 1);
[0013]
步骤7:通过预测的横向输出值y(t 1)和回报r(t 1)计算下一时刻actor输出未经修正的初步pid参数值k'(t)及critic的值函数v
(t)
;
[0014]
步骤8:通过k'(t)及v
(t)
计算td误差,同时更新actor
‑
critic结构中actor和critic的权重值;
[0015]
步骤9:权重值通过rbf网络中的梯度下降,计算获得相应核函数的中心值和宽度值;
[0016]
步骤10:判断获得的中心值和宽度值是否达到预设的停止条件,是则结束,输出pid控制量作用下的无人驾驶铰接式清扫车的横向输出值,否则继续回到步骤2进行下一次迭代计算。
[0017]
上述无人驾驶铰接式清扫车的横向控制方法,所述步骤2中,无人驾驶铰接式清扫车的转向过程分解为两个运动,即稳态转向运动和原地转向运动,以下分别对这两种运动过程进行分析:
[0018]
无人驾驶的铰接式清扫车稳态转向模型中,设定o为瞬心,p
f
(x
f
,y
f
)和p
r
(x
r
,y
r
)分别为前后桥与铰接点距离,θ
f
和θ
r
为前后车体朝向,即航向角,前后车体夹角γ为铰接转向角,以铰接车前桥中点p
f
为整车状态参考点;
[0019]
定义整车速度v为v=v
f
,其中v为整车速度,v
f
为前车架速度,前桥中点p
f
速度为式x
f
为前桥中点横坐标,y
f
为前桥中点纵坐标,θ
f
为前桥航向角,前桥航向角变化率即前桥角速度为其中,l
f
、l
r
为前、后桥与铰接点距离,所以得出无人驾驶铰接式清扫车稳态转向过程中前桥的位姿状态为p
f
=(x
f
,y
f
,θ
f
,γ),即
[0020]
无人驾驶铰接式清扫车的原地转向模型中,因为p
f
是整车状态参考点,因此认为原地转向过程中该点相对地面静止,前桥中点p
f
在xy平面上的速度分量为航向角
变化率为则无人驾驶铰接式清扫车车在原地转向过程中前桥的位姿状态表示为p
f
=(x
f
,y
f
,θ
f
,γ),即联立铰接式清扫车稳态转向过程和原地转向过程的前桥位姿状态,得出无人驾驶铰接式清扫车的位姿状态p
f
=(x
f
,y
f
,θ
f
,γ),即
[0021]
上述无人驾驶铰接式清扫车的横向控制方法,所述步骤2中,无人驾驶铰接式清扫车在行驶过程中,实际路径和参考路径之间的路径偏差示意图为一大一小两个内切圆,其中小圆圆心为c,是无人驾驶铰接式清扫车的瞬时实际行驶轨迹;大圆圆心为c,是无人驾驶铰接式清扫车参考轨迹,在理想情况下,铰接车通过参考轨迹上的3个点p1、p2、p3;
[0022]
在实际行驶路径与参考路径偏差的模型中,有如下定义:
[0023]
横向位置偏差ε
d
:无人驾驶铰接式清扫车参考定位点p与参考路径上对应点p的横向位置差值,对应点p为参考路径上距离定位点p最近的点;
[0024]
航向角偏差ε
θ
:无人驾驶铰接式清扫车定位参考点p的航向角与参考路径上对应点p的航行角的差值,航向角为参考点p速度方向与车辆坐标系x轴之间的夹角,航行角为对应点p的切线与车辆坐标系x轴之间的夹角;
[0025]
曲率偏差ε
c
:铰接式清扫车定位参考点p与参考路径上对应点p的曲率差值;
[0026]
在实际无人驾驶过程中,包括三种实际路径逼近参考路径的情况,第一种为实际路径与参考路径平行的情况,此时两路径距离即为横向位置偏差ε
d
,控制器根据该横向位置偏差ε
d
计算控制量使得横向位置偏差ε
d
减小,达到使实际轨迹逼近参考轨迹的目的;第二种为实际路径与参考路径相交的情况,此时两路径夹角即为航向角偏差ε
θ
,当无人驾驶铰接式清扫车向参考路径接近时,虽然减少了横向位置偏差ε
d
,却产生了航向角偏差ε
θ
,在铰接车行驶至路径交点处时横向位置偏差ε
d
消除,但由于车体惯性与外界环境干扰因素影响,铰接式清扫车依旧保持之前的航向,则从下一时刻开始,横向位置偏差ε
d
再次产生,因此航向角偏差也作为控制器输入进行控制;第三种为实际路径与参考路径相切的情况,此时两路径切点处曲率差为曲率偏差ε
c
,无人驾驶铰接式清扫车行驶至切点位置时横向位置偏差ε
d
和航向角偏差ε
θ
均为0,但由于车体惯性与外界环境干扰因素影响,铰接车依旧保持之前的转角,则下一时刻开始横向位置偏差ε
d
和航向角偏差ε
θ
再次产生;因此,在设计控制器时,横向位置偏差ε
d
,航向角偏差ε
θ
和曲率偏差ε
c
均作为控制器的考虑因素进行偏差控制,以加快收敛速度、减少震荡。
[0027]
上述无人驾驶铰接式清扫车的横向控制方法,所述步骤4中,actor
‑
critic方法融
合了以值函数为基础的critic
‑
only和以动作为基础的actor
‑
critic两种方法的特点,同时对马氏决策过程的值函数和策略函数进行逼近;actor
‑
critic学习模型分为两大部分:执行器actor部分和执行器critic部分,actor
‑
critic学习可对值函数和策略函数进行逼近,其中策略估计由actor部分通过策略梯度估计方法进行梯度下降学习来实现;而值函数估计由critic部分采用td(λ)学习算法实现。
[0028]
上述无人驾驶铰接式清扫车的横向控制方法,所述步骤4中,actor
‑
critic学习模型的体系结构为:对于状态s,执行器根据当前决策选择动作a,状态s接受动作a的作用后,转移到状态s 1,同时产生一个回报信号r;状态s和回报信号r作为评价器的输入,其输出为值函数的估计,并产生一个td误差信号,用于评价器和执行器网络的更新学习,对选择的动作做出评价,以修正执行器的动作选择策略。
[0029]
上述无人驾驶铰接式清扫车的横向控制方法,所述步骤4中,critic对值函数估计采用如下学习算法:
[0030]
w
t 1
=w
t
α[r
t
γv(s
t 1
)
‑
v(s
t
)]z
t
[0031]
其中,w
t
为t时刻的权值向量;α是学习率,是一个可调节的常数;r
t
表示t时刻的回报信号;γ为折扣因子,表示的是随着时间的推移回报率的折扣0<γ<1,本发明中可取0.99;s
t 1
,s
t
分别为t 1和t时刻的状态;v(s
t
)为t时刻状态下的值函数估计;z
t
为适合度轨迹,定义为:λ表示td(λ)学习算法中的λ—回报,假定actor的输出为一维,设actor的输出为:经过高斯分布函数后,实际控制量输出为:中间变量其中k1>0,k2>0,两者均为常数。
[0032]
上述无人驾驶铰接式清扫车的横向控制方法,所述步骤4中,actor的学习算法采用如下的近似策略梯度估计算法:
[0033][0034]
其中,w为权值向量;j
π
为学习系统性能指标;为内部回报即td误差δ
td
,由critic的时域差值信号来提供:
[0035]
上述无人驾驶铰接式清扫车的横向控制方法,所述步骤9中,rbf神经网络是一种三层前向网络,分为输入层、隐含层、输出层;
[0036]
第一层:输入层是整个brf网络的输入,输入层共有三个输入节点,这三个节点的输入分别是状态向量x(t)的一个分量,x(t)=[x
1 x
2 x3]
t
=[e(t) δe(t) δ2e(t)]
t
,分别代表系统输出误差、误差的一次差分、误差的二次差分;
[0037]
第二层:隐含层共有h个节点激活函数选用高斯型核函数,根据高斯核函数的形式,第j个隐节点的输出为:
[0038][0039]
其中,μ
j
=[μ
1j μ
2j μ
3j
]
t
为第j个隐节点的中心变量,σ
j
为第j个节点的宽度参数;
[0040]
第三层:采用一个rbf网络同时实现策略函数和值函数的学习,actor和critic共享brf网络的输入层和隐含层的资源,故输出层由actor和critic两部分组成,共四个输出节点,其中前三个输出为actor部分的输出k'(t)的三个分量,第四个节点的输出为critic部分的值函数v(t)。
[0041]
本发明的有益效果在于:本发明提出了一种基于无人驾驶的铰接式清扫车的横向控制方法,通过建立无人驾驶铰接式清扫车的横向运动模型,得到该无人驾驶铰接式清扫车系统的横向控制误差来源,基于原有的pid控制策略,将强化学习中的actor
‑
critic结构和传统的pid控制做结合,利用其能同时逼近值函数以及策略函数的特点,用来解决pid参数无法在线整定的问题,同时为了优化利用强化学习处理数据时系统维数、计算量和存储空间不断变大的情况,又结合了神经网络中的径向基函数(rbf)网络,对策略函数以及策略函数采用局部逼近的方式,加强本控制系统的泛化能力。与固定参数pid算法相比,本发明在各项偏差和控制量的幅值、均值以及方差均有明显减小,能有效减少无人驾驶铰接式清扫车运行时的震荡和稳态误差,提高收敛速度。无论是在实际路径与参考路径较远,横向位置偏差影响起主要作用时;还是在实际路径与参考路径较近,航向角偏差与曲率偏差起主要作用时,本发明都能够实现无人驾驶铰接式清扫车横向pid控制器参数的自适应整定,实现对无人驾驶铰接式清扫车运行过程中各个工况的横向稳定控制,实现对路径跟踪控制的智能化。
附图说明
[0042]
图1为现有铰接式清扫车的结构示意图。
[0043]
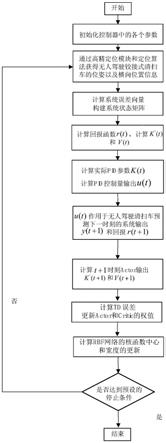
图2为本发明的流程图。
[0044]
图3为无人驾驶铰接式清扫车稳态转向示意图。
[0045]
图4为无人驾驶铰接式清扫车原地转向示意图。
[0046]
图5为无人驾驶铰接式清扫车路径示意图。
[0047]
图6为实际路径逼近参考路径情况示意图。
[0048]
图7为actor
‑
critic学习框架图。
[0049]
图8为基于rbf网络的actor
‑
critic学习示意图。
[0050]
图9为基于actor
‑
critic结构和rbf网络的自适应pid控制器结构框图。
具体实施方式
[0051]
下面结合附图和实施例对本发明作进一步的说明。
[0052]
如图2所示,一种无人驾驶铰接式清扫车的横向控制方法,包括以下步骤:
[0053]
步骤1:初始化控制器的各个参数。
[0054]
步骤2:由建立的无人驾驶铰接式清扫车的转向模型以及运动过程的路径示意图得知无人驾驶铰接式清扫车在横向控制过程中受横向位置偏差ε
d
,航向角偏差ε
θ
和曲率偏差ε
c
影响,通过高精定位模块和高精定位算法获得横向位置偏差ε
d
,航向角偏差ε
θ
和曲率偏差ε
c
。
[0055]
首先建立无人驾驶铰接式清扫车的数学模型,无人驾驶铰接式清扫车的转向过程分解为两个运动,即稳态转向运动和原地转向运动,以下分别对这两种运动过程进行分析:
[0056]
如图3所示,无人驾驶的铰接式清扫车稳态转向模型中,设定o为瞬心,p
f
(x
f
,y
f
)和p
r
(x
r
,y
r
)分别为前后桥与铰接点距离,θ
f
和θ
r
为前后车体朝向,即航向角,前后车体夹角γ为铰接转向角,以铰接车前桥中点p
f
为整车状态参考点,因为该点的速度与无人驾驶铰接式清扫车的前进方向一致,有利于计算分析。
[0057]
定义整车速度v为v=v
f
,其中v为整车速度,v
f
为前车架速度,前桥中点p
f
速度为式x
f
为前桥中点横坐标,y
f
为前桥中点纵坐标,θ
f
为前桥航向角,前桥航向角变化率即前桥角速度为其中,l
f
、l
r
为前、后桥与铰接点距离,所以得出无人驾驶铰接式清扫车稳态转向过程中前桥的位姿状态为p
f
=(x
f
,y
f
,θ
f
,γ),即
[0058]
如图4所示,无人驾驶铰接式清扫车的原地转向模型中,因为p
f
是整车状态参考点,因此认为原地转向过程中该点相对地面静止,前桥中点p
f
在xy平面上的速度分量为航向角变化率为则无人驾驶铰接式清扫车车在原地转向过程中前桥的位姿状态表示为p
f
=(x
f
,y
f
,θ
f
,γ),即联立铰接式清扫车稳态转向过程和原地转向过程的前桥位姿状态,得出无人驾驶铰接式清扫车的位姿状态p
f
=(x
f
,y
f
,θ
f
,γ),即
[0059]
进一步的,为了清楚地对无人驾驶铰接式清扫车运动路径进行描述,下面建立实际行驶路径与参考路径偏差的模型。
[0060]
如图5所示,无人驾驶铰接式清扫车在行驶过程中,实际路径和参考路径之间的路径偏差示意图为一大一小两个内切圆,其中小圆圆心为c,是无人驾驶铰接式清扫车的瞬时实际行驶轨迹;大圆圆心为c,是无人驾驶铰接式清扫车参考轨迹,在理想情况下,铰接车通过参考轨迹上的3个点p1、p2、p3;
[0061]
在实际行驶路径与参考路径偏差的模型中,有如下定义:
[0062]
横向位置偏差ε
d
:无人驾驶铰接式清扫车参考定位点p与参考路径上对应点p的横向位置差值,对应点p为参考路径上距离定位点p最近的点;
[0063]
航向角偏差ε
θ
:无人驾驶铰接式清扫车定位参考点p的航向角与参考路径上对应点p的航行角的差值,航向角为参考点p速度方向与车辆坐标系x轴之间的夹角,航行角为对应点p的切线与车辆坐标系x轴之间的夹角;
[0064]
曲率偏差ε
c
:铰接式清扫车定位参考点p与参考路径上对应点p的曲率差值;
[0065]
如图6所示,在实际无人驾驶过程中,包括三种实际路径逼近参考路径的情况,第一种为实际路径与参考路径平行的情况,即图6中(a)所示,此时两路径距离即为横向位置偏差ε
d
,控制器根据该横向位置偏差ε
d
计算控制量使得横向位置误差ε
d
减小,达到使实际轨迹逼近参考轨迹的目的;第二种为实际路径与参考路径相交的情况,即图6中(b)所示,此时两路径夹角即为航向角偏差ε
θ
,当无人驾驶铰接式清扫车向参考路径接近时,虽然减少了横向位置偏差ε
d
,却产生了航向角偏差ε
θ
,在铰接车行驶至路径交点处时横向位置偏差ε
d
消除,但由于车体惯性与外界环境干扰因素影响,铰接式清扫车依旧保持之前的航向,则从下一时刻开始,横向位置偏差ε
d
再次产生,因此航向角偏差也作为控制器输入进行控制;第三种为实际路径与参考路径相切的情况,即图6中(c)所示,此时两路径切点处曲率差为曲率偏差ε
c
,无人驾驶铰接式清扫车行驶至切点位置时横向位置偏差ε
d
和航向角偏差ε
θ
均为0,但由于车体惯性与外界环境干扰因素影响,铰接车依旧保持之前的转角,则下一时刻开始横向位置偏差ε
d
和航向角偏差ε
θ
再次产生;因此,在设计控制器时,横向位置偏差ε
d
,航向角偏差ε
θ
和曲率偏差ε
c
均作为控制器的考虑因素进行偏差控制,以加快收敛速度、减少震荡。
[0066]
步骤3:将横向位置偏差ε
d
,航向角偏差ε
θ
和曲率偏差ε
c
写成误差向量e(t),e(t)=[ε
d ε
θ ε
c
]
t
,将误差向量通过状态转换器转换为系统状态矩阵x(t),x(t)=[e(t)δe(t)δ2e(t)]
t
,其中δe(t)=e(t)
‑
e(t
‑
1)为e(t)的一次差分δ2e(t)=e(t)
‑
2e(t
‑
1) e(t
‑
2)为e(t)的二次差分。
[0067]
步骤4:计算actor
‑
critic的回报函数r(t),同时状态矩阵x(t)作为rbf网络的输入,经过隐含层与输出层的计算,输出未经修正的初步pid参数值k'(t)及critic的值函数v
(t)
。
[0068]
actor
‑
critic结构也称为执行器
‑
评价器学习算法,是一种重要的强化学习算法,其结构如图7所示,actor
‑
critic方法融合了以值函数为基础的critic
‑
only和以动作为基础的actor
‑
critic两种方法的特点,同时对马氏决策过程的值函数和策略函数进行逼近;actor
‑
critic学习模型分为两大部分:执行器actor部分和执行器critic部分,actor
‑
critic学习可对值函数和策略函数进行逼近,其中策略估计由actor部分通过策略梯度估计方法进行梯度下降学习来实现;而值函数估计由critic部分采用td学习算法实现。
[0069]
图7给出了actor
‑
critic学习模型的体系结构为:对于状态s,执行器根据当前决策选择动作a,状态s接受动作a的作用后,转移到状态s 1,同时产生一个回报信号r;状态s和回报信号r作为评价器的输入,其输出为值函数的估计,并产生一个td误差信号,用于评价器和执行器网络的更新学习,对选择的动作做出评价,以修正执行器的动作选择策略。
[0070]
critic对值函数估计采用如下学习算法:
[0071]
w
t 1
=w
t
α[r
t
γv(s
t 1
)
‑
v(s
t
)]z
t
[0072]
其中,w
t
为t时刻的权值向量,α是学习率,是一个可调节的常数;r
t
表示t时刻的回报信号;γ为折扣因子,表示的是随着时间的推移回报率的折扣0<γ<1,本发明中可取0.99;s
t 1
,s
t
分别为t 1和t时刻的状态,v(s
t
)为t时刻状态下的值函数估计,z
t
为适合度轨迹,定义为:λ表示td(λ)学习算法中的λ—回报;假定actor的输出为一维,设actor的输出为:经过高斯分布函数后,实际控制量输出为:中间变量其中k1>0,k2>0,两者均为常数。
[0073]
actor的学习算法采用如下的近似策略梯度估计算法:
[0074][0075]
其中,w为权值向量,j
π
为学习系统性能指标,为内部回报即td误差δ
td
,由critic的时域差值信号来提供:
[0076]
步骤5:初步pid参数值k'(t)经修正器修正后,得到最终的pid参数k(t),由机载电脑的计算单元计算得到此最终pid控制量作用下的无人驾驶铰接式清扫车的横向输出值u(t)。
[0077]
步骤6:通过迭代计算将横向输出值u(t)作用于无人驾驶铰接式清扫车,预测到的下一时刻无人驾驶铰接式清扫车的横向输出值y(t 1)和回报r(t 1)。
[0078]
步骤7:通过预测的横向输出值y(t 1)和回报r(t 1)计算下一时刻actor输出未经修正的初步pid参数值k'(t)及critic的值函数v
(t)
。
[0079]
步骤8:通过k'(t)及v
(t)
计算td误差,同时更新actor
‑
critic结构中actor和critic的权重值。
[0080]
步骤9:权重值通过rbf网络中的梯度下降,计算获得相应核函数的中心值和宽度值。
[0081]
rbf神经网络是一种三层前向网络,分为输入层、隐含层、输出层。网络结构如图8所示:
[0082]
第一层:输入层是整个brf网络的输入。该层共有三个输入节点,这三个节点的输入分别是状态向量x(t)的一个分量。x(t)=[x
1 x
2 x3]
t
=[e(t) δe(t) δ2e(t)]
t
,分别代表系统输出误差、误差的一次差分、误差的二次差分。
[0083]
第二层:隐含层共有h个节点激活函数选用高斯型核函数。根据高斯核函数的形式,第j个隐节点的输出为:
[0084][0085]
其中,μ
j
=[μ
1j μ
2j μ
3j
]
t
为第j个隐节点的中心变量,σ
j
为第j个节点的宽度参数。
[0086]
第三层:为了减小计算量,提升计算速度,本发明采用一个rbf网络同时实现策略函数和值函数的学习。actor和critic共享brf网络的输入层和隐层的资源,故输出层由actor和critic两部分组成,共四个输出节点。其中前三个输出为actor部分的输出k'(t)的
三个分量,第四个节点的输出为critic部分的值函数v(t)。
[0087]
基于强化学习和actor
‑
critic结构和神经网络的自适应pid控制器的结构框图如图9所示其控制原理为:
[0088]
首先,误差定义为期望输出与被控对象实际输出的差值,即:e(t)=y
d
(t)
‑
y(t),误差向量e(t)经过状态转换器转换成rbf网络学习需要的状态矩阵x(t)=[e(t)δe(t)δ2e(t)]
t
。状态矩阵x(t)作为rbf网络的输入,经过隐含层与输出层的计算,输出未经修正的初步pid参数值k'(t)=[k'
i
k'
p k'
d
]及critic的值函数v
(t)
,k'(t)为actor部分给出的结果,但并不是最终的pid参数值,还需要动作修正器(stochastic action modifier,sam)进行修正。其中随机动作修正器提供的修正值依赖于critic提供的值函数v
(t)
信息。k'(t)经修正后,得到最终的pid参数k(t)=[k
i k
p k
d
]。此结果作为pid参数,作用于被控系统,可得到系统的实际输出量y
(t)
,从而可获得下一步的新的误差,进入新一轮的计算。直到最后得到的输出路径参数值达到设定的理想误差范围。
[0089]
步骤10:判断获得的中心值和宽度值是否达到预设的停止条件,是则结束,输出pid控制量作用下的无人驾驶铰接式清扫车的横向输出值,否则继续回到步骤2进行下一次迭代计算。
再多了解一些
本文用于企业家、创业者技术爱好者查询,结果仅供参考。