一种基于gaia系统的数据分类方法
技术领域
1.本发明属于分布式大数据计算系统及机器学习技术领域,具体涉及一种基于gaia系统的数据分类方法。
背景技术:
2.gaia是一个面向多计算模型混合并存的高时效、可扩展的新一代大数据计算系统。该新型大数据计算系统针对批流混合任务具有全周期多尺度优化技术和统一计算引擎。现有大数据计算系统或依托自身计算引擎模拟另一类框架的行为,或定义一套通用接口屏蔽底层计算引擎的差异,对批流融合支持较弱。同时,其优化大多位于执行的特定时期或特定层级,且针对高复杂性任务的优化能力不足。针对以上问题,创新性地开发了基于统一计算引擎和全周期多尺度优化的高性能批流融合大数据计算引擎。该引擎为批流融合处理提供统一表达逻辑支持,通过统一表达建模融合批流处理的计算模型、数据模型、变换模型和动作模型,实现批、流处理的真正融合。针对作业的多样性、持久性、迭代性等特点,提供面向多作业、多任务、迭代计算、持久计算等优化策略,优化针对性更强。同时,提供执行前和执行中的全周期优化,并细分为作业级、任务级、变换级等多个尺度,以实现极速响应和海量吞吐。
3.超限学习机(简称elm)是一种基于单隐层前馈神经网络的机器学习算法,具有超快的学习速度,同时又因其不存在大量迭代计算而具有很好的泛化能力。在当今数据量爆发的时代,将大量机器学习算法实现于分布式计算引擎之上也是一种必然的趋势,因此也诞生了大量基于hadoop和spark的elm算法,使其能够支持对海量数据的学习。
4.虽然上述面向海量数据的分布式离线elm算法对于图像识别、自动驾驶等新一代智能应用起到了巨大的贡献,然而现实的世界是一个不断变化的世界,海量数据也在不断地增加和更迭,因此对海量数据的在线学习也是同样重要的任务。然而,在目前的大数据计算引擎中,hadoop主要针对大数据批处理,对于实时计算的性能较差;spark引入了spark streaming支持流计算,但其本质是一种微批处理,实时计算性能也不是很好,尤其表现在延时方面;storm是一种原生流计算系统,不支持大数据批处理;flink虽然是目前新一代的“批流融合”计算系统,但对于批处理和流计算也分别需要定义两套接口,大大增加了开发的难度。综上所述,需要找到一套具有“高吞吐、低延时”的,从上层开发接口到底层计算引擎都支持“批流计算融合”的分布式计算系统来开发一套同时支持离线学习与在线学习功能的elm框架,实现高精度、高效率的数据分类。
技术实现要素:
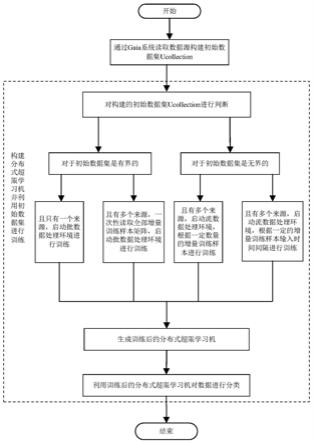
5.基于上述问题,本发明提出一种基于gaia系统的数据分类方法,包括:
6.步骤一:通过gaia系统读取数据源构建初始数据集ucollection,所述数据源包括带有属性的训练样本矩阵x、t以及初始的随机赋值权重向量w;
7.步骤二:基于gaia系统构建分布式超限学习机并利用初始数据集ucollection进
行训练;
8.步骤三:通过gaia系统读取用户输入的待分类数据集,利用训练后的分布式超限学习机输出数据的分类结果。
9.所述步骤二包括:
10.步骤1:对构建的初始数据集ucollection进行判断,如果初始数据集ucollection是有界的且只有一个来源,则一次性读取全部数据作为训练数据,并启动批数据处理环境进行训练;
11.步骤2:如果初始数据集是有界的且有多个来源,一次性读取全部增量训练样本矩阵(x1,x2…
,x
k
)、(t1,t2…
,t
k
),并启动批数据处理环境进行训练;
12.步骤3:如果初始数据集ucollection是无界的且有多个来源,在线持续输入增量训练样本矩阵,启动流数据处理环境,根据一定数量的增量训练样本进行训练;
13.步骤4:如果初始数据集ucollection是无界的且有多个来源,在线持续输入增量训练样本矩阵,启动流数据处理环境,根据一定的增量训练样本输入时间间隔进行训练。
14.所述步骤1包括:
15.步骤1.1:利用gaia系统中的pardo并行转换操作进行内积计算的第一步运算过程;
16.步骤1.2:利用gaia系统中的groupbykey转换操作进行内积计算的第二步运算过程,即将得到的每个乘积值发送到主节点中并进行求和操作,得到矩阵x与向量w进行内积运算的最终结果;
17.步骤1.3:利用超限学习机的非线性映射函数计算矩阵x的激活函数值h
i
(x)得到矩阵h,并得到矩阵h的转置矩阵h
t
;所述超限学习机的非线性映射函数表示为:
18.h
i
(x)=g(w
i
·
x b
i
)
ꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀ
(1)
19.式中,w
i
表示第i个随机赋值权重向量,i=1,2,
…
,l,l为隐藏层的结点个数,b
i
表示偏移量,g(
·
)表示非线性映射函数;
20.步骤1.4:继续使用pardo并行转换操作进行h
t
h内积计算和h
t
t内积计算的第一步运算过程,然后使用groupbykey转换操作进行h
t
h内积计算和h
t
t内积计算的第二步运算过程,得到h
t
h内积和h
t
t内积计算的结果;
21.步骤1.5:利用公式(2)得到分布式超限学习机的输出权重β;
[0022][0023]
式中,i为单位矩阵,λ为根据岭回归理论引入的正值。
[0024]
所述步骤2包括:
[0025]
步骤2.1:使用pardo并行转换操作,按照预设的并行度值n将一次性给定的增量训练样本矩阵(x1,x2…
,x
k
)进行分组;
[0026]
步骤2.2:对于分组后的矩阵,利用超限学习机的非线性映射函数计算矩阵x的激活函数值h
i
(x)得到矩阵h,则n个分组分别计算得到n个矩阵h,标记为h1,h2…
,h
n
;
[0027]
步骤2.3:使用groupbykey转换操作,将每个h1,h2…
,h
n
分别发送到主节点中;
[0028]
步骤2.4:根据h1,h2…
,h
n
,利用公式(3)、(4)得到每一个增量训练样本输入后的更新权重,直至输入最后的增量训练样本,得到最终更新的输出权重;
[0029][0030][0031]
其中,其中,为h的伪逆矩阵,β
k
为第k次迭代的输出权重值,m
k
为第k次迭代的中间结果。
[0032]
所述步骤3包括:
[0033]
步骤3.1:使用pardo并行转换操作,根据预设的并行度值n将持续输入的增量训练样本矩阵(x1,x2…
,x
k
)进行分组,每组数据量的最大值标记为groupsize,其大小等于滚动窗口的大小;
[0034]
步骤3.2:数据被分发至每个组后,利用超限学习机的非线性映射函数计算矩阵x的激活函数值h
i
(x)得到矩阵h,则n个分组分别计算得到n个矩阵h,标记为h1,h2…
,h
n
;
[0035]
步骤3.3:使用groupbykey转换操作,将每个h1,h2…
,h
n
分别发送到主节点中;
[0036]
步骤3.4:当n的值达到countsize后,使用trigger操作对计算输出权重进行触发,读取h1,h2…
,h
n
;
[0037]
步骤3.5:根据公式(3)、公式(4)得到每一个增量训练样本输入后的更新权重,直至输入最后的增量训练样本,得到最终更新的输出权重;
[0038]
步骤3.6:重复步骤3.2~步骤3.5,计算每个增量训练样本产生的矩阵h,每当矩阵h的数量达到countsize后,都触发一次更新输出权重的过程。
[0039]
所述步骤4包括:
[0040]
步骤4.1:使用pardo并行转换操作,根据预设的并行度值n将持续输入的增量训练样本矩阵(x1,x2…
,x
k
)进行分组;
[0041]
步骤4.2:当数据被分发至每个组后,利用超限学习机的非线性映射函数计算矩阵x的激活函数值h
i
(x)得到矩阵h,则n个分组分别计算得到n个矩阵h,标记为h1,h2…
,h
n
;
[0042]
步骤4.3:使用groupbykey转换操作,将每个h1,h2…
,h
n
分别发送到主节点中;
[0043]
步骤4.4:当时间达到预设时间间隔timesize后,使用trigger操作对计算输出权重进行触发,读取(h1,h2…
,h
n
);
[0044]
步骤4.5:根据公式(3)、公式(4)得到每一个增量训练样本输入后的更新权重,直至输入最后的增量训练样本,得到最终更新的输出权重;
[0045]
步骤4.6:重复步骤4.2~步骤4.5,计算每个增量训练样本产生的矩阵h,每当时间达到达到timesize后,都触发一次更新输出权重的过程。
[0046]
所述步骤1.1包括:
[0047]
步骤1.1.1:将数据源表示为三元组形式,元素分别为行id、列id以及元素值;
[0048]
步骤1.1.2:计算矩阵x与向量w中对应元素的乘积,得到内积计算的第一步运算结果。
[0049]
本发明的有益效果是:
[0050]
本发明提出了一种基于gaia系统的数据分类方法,所述方法基于超限学习机实现,gaia系统由于其更新的底层流处理计算架构和多种全局优化与执行优化技术,相比于其他分布式计算系统(如hadoop、spark、flink等)具有更好的执行效率。在批处理模式下可实现海量吞吐,在流处理模式下可实现极速响应;另外,由于超限学习机是一种单隐层前馈
神经网络,相比于其他的学习机(如svm等)具有更快的学习速度;将上述两种优势进行结合,可使得本发明实现更高效率的数据分类。再者,由于gaia系统是一种“批流融合”分布式计算系统,可通过构建的初始数据集ucollection自行判断判定启动批处理环境或流处理环境,因此用户在使用该学习机进行数据分类时可不用关心数据的类型与来源,只需关注对数据的处理过程即可,为用户的使用带来了极大的便利。
附图说明
[0051]
图1为本发明中基于gaia系统的数据分类方法流程图;
[0052]
图2为本发明中基于gaia系统的分布式超限学习机框图;其中,(a)为基于gaia系统的分布式离线超限学习机整体框架;(b)为基于gaia系统的分布式在线超限学习机整体框架;
[0053]
图3为本发明中gaia系统执行分布式离线超限学习机的过程;
[0054]
图4为本发明中gaia系统执行一次性输入全部增量训练数据的分布式在线超限学习机的过程;
[0055]
图5为本发明中gaia系统执行按一定的增量数据量输出更新后的输出权重的分布式在线超限学习机的过程;
[0056]
图6为本发明中gaia系统执行按一定的时间间隔输出更新后的输出权重的分布式在线超限学习机的过程。
具体实施方式
[0057]
下面结合附图和具体实施实例对发明做进一步说明。针对现有分布式超限学习机框架的不足,提供一种基于gaia系统的分布式超限学习机,能够有效支持分布式离线学习与在线学习,并使其中的算法具有较高的效率,利用该分布式超限学习机实现数据的分类。
[0058]
本发明提出一种基于gaia系统的数据分类方法,所述方法基于超限学习机实现,使用gaia系统中的unified api开发该框架,主要有以下两方面优势。第一,使用传统分布式计算系统开发融合离线学习与在线学习的框架时,往往需要两种计算引擎或两套接口(批处理接口、流计算接口),而gaia系统中的unified api是一种“批流融合”的开发接口,可以使开发人员在编写代码时无需关注被处理数据来源(离线、在线),极大简化了开发难度;第二,用户使用该框架时开发上层应用时,也只需关注对数据的处理过程,无需定义两套接口。
[0059]
该框架由两部分组成,分别是面向海量离线大数据的分布式离线超限学习机,以及面向海量在线大数据的分布式在线超限学习机,分别适用于不同的训练数据输入方式。由于gaia系统的底层为分布式流计算引擎,并将大数据批处理当作流处理的一种特殊情况,因此基于gaia系统的分布式离线超限学习机将输入的训练数据当成一种有限的流数据进行处理,而基于gaia系统的分布式在线超限学习机将输入的训练数据当成一种原生的流数据进行处理。
[0060]
基于gaia系统的分布式离线超限学习机整体框架如图2(a)所示。由于输入数据为海量离线数据,因此该学习机的计算过程可以转化为超大矩阵的分布式计算过程。其中,超大矩阵元素的乘积由gaia系统的任务管理节点(taskmanager)进行分布式计算,元素乘积
后的加和以及激活函数的计算过程由gaia系统的作业管理节点(jobmanager)进行计算。传统离线超限学习机的计算过程如下所示:
[0061][0062]
其中,x=[x1,x2,
…
x
n
]
t
和β=[β1,β2,
…
β
l
]
t
分别表示输入向量与输出权重向量,n为样本个数,l为隐藏层的结点个数,h
i
(x)=g(w
i
·
x b
i
)是超限学习机的非线性映射函数,也叫做激活函数。在本发明中,激活函数取sigmoid函数。而传统离线超限学习机的目的就是求出最优的β值,使得||hβ
‑
t||=0,也就是hβ=t。由于l值的大小远小于n,因此β的求值过程可以转化为其中为h的伪逆矩阵。为了使算法更加适用于分布式计算并提高其泛化能力,可以被更改为并引入值1/λ。因此,基于gaia系统的分布式离线超限学习机的计算过程如下所示,其中i为单位矩阵:
[0063][0064]
基于gaia系统的分布式在线超限学习机整体框架如图2(b)所示。其主要分为两个阶段,第一阶段为计算初始权重,其过程与传统离线超限学习机的计算过程相同,第二阶段为输出权重的更新过程,上述两种过程在分布式环境下均为超大矩阵计算过程。传统在线超限学习机的计算过程如公式3和公式4所示:
[0065][0066][0067]
其中,h0可根据传统离线超限学习机的计算过程得到。这样,每次被更新的权重可根据上述两个公式得到。在分布式计算过程中,每个分组产生的h值由gaia系统的任务管理节点(taskmanager)进行分布式计算,上述两个公式的计算过程由gaia系统的作业管理节点(jobmanager)进行计算。
[0068]
基于上述原理,一种基于gaia系统的数据分类方法,所述方法基于超限学习机实现,如图1所示,包括:
[0069]
步骤一:gaia系统对学习机作业进行管道pipeline创建,读取数据源构建初始数据集ucollection,所述数据源包括带有属性的训练样本矩阵x、t以及初始的随机赋值权重向量w;
[0070]
步骤二:基于gaia系统构建分布式超限学习机并利用初始数据集进行训练;包括:
[0071]
步骤1:对构建的初始数据集ucollection进行判断,如果初始数据集ucollection是有界的且只有一个来源,则一次性读取全部数据作为训练数据,并启动批数据处理环境进行训练;学习机将按照公式(2)进行函数调用,计算输出权重,gaia系统对上述计算的具体执行过程如图3所示,包括:
[0072]
步骤1.1:利用gaia系统中的pardo并行转换操作进行内积计算的第一步运算过程;包括:
[0073]
步骤1.1.1:将数据源表示为三元组形式,元素分别为行id、列id以及元素值;
[0074]
步骤1.1.2:计算矩阵x与向量w中对应元素的乘积,得到内积计算的第一步运算结
果,此过程是一个并行计算的过程,且矩阵w与矩阵x是分布式存储,因此矩阵的元素乘积是在不同的节点中进行;
[0075]
步骤1.2:利用gaia系统中的groupbykey转换操作进行内积计算的第二步运算过程,即将得到的每个乘积值发送到主节点中并进行求和操作,得到矩阵x与向量w进行内积运算的最终结果,由于此步骤的计算量较少,因此无需进行并行计算操作;
[0076]
步骤1.3:利用超限学习机的非线性映射函数计算矩阵x的激活函数值h
i
(x)得到矩阵h,并得到矩阵h的转置矩阵h
t
;所述超限学习机的非线性映射函数表示为:
[0077]
h
i
(x)=g(w
i
·
x b
i
)
ꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀ
(1)
[0078]
式中,w
i
表示第i个随机赋值权重向量,i=1,2,
…
,l,l为隐藏层的结点个数,b
i
表示偏移量,g(
·
)表示非线性映射函数,在本发明中,激活函数取sigmoid函数,即g(x)=1/(1 e
‑
x
);
[0079]
步骤1.4:继续使用pardo并行转换操作进行h
t
h内积计算和h
t
t内积计算的第一步运算过程,然后使用groupbykey转换操作进行h
t
h内积计算和h
t
t内积计算的第二步运算过程,得到h
t
h内积和h
t
t内积计算的结果;
[0080]
步骤1.5:利用公式(2)得到分布式超限学习机的输出权重β,将输出的权重值写入文件,最后将该文件保存至本地或hdfs中;
[0081][0082]
式中,i为单位矩阵,λ为根据岭回归理论引入的正值。
[0083]
在图3中,每一个圆形代表一个操作,除了初始的读取数据source外,均属于转换操作utransform;每一个矩形代表一个数据集,在gaia系统中被统称为ucollection;图中的箭头表示数据的流动过程。
[0084]
基于gaia系统的分布式在线超限学习机主要由步骤2
‑
步骤4所示。其中,步骤2描述了增量训练样本数据一次性全部给入的情况。这些增量训练样本数据可以是多个数据源,且每个数据源中的数据量大小不同:通过source api读取数据源,该数据源可以是本地数据,也可以是存储在hadoop分布式文件系统hdfs中。构建初始数据集ucollection,启动批处理环境;所述的被读取的数据源分别是通过初始训练样本矩阵x、t、初始的随机赋值权重向量w计算出的中间结果m0、初始输出权重值β0,以及一次性给定的增量训练样本矩阵(x1,x2…
,x
k
)、(t1,t2…
,t
k
);
[0085]
步骤2:如果初始数据集ucollection是有界的且有多个来源,则说明已有初始的输出权重,一次性读取全部增量训练样本矩阵(x1,x2…
,x
k
)、(t1,t2…
,t
k
),并启动批数据处理环境进行训练;学习机将按照公式(3)和公式(4)进行函数调用,计算更新的输出权重,gaia系统对上述计算的具体执行过程如图4所示;包括:
[0086]
步骤2.1:使用pardo并行转换操作,按照预设的并行度值n将一次性给定的增量训练样本矩阵(x1,x2…
,x
k
)进行分组;由于(x1,x2…
,x
k
)本身以分布式的方式进行存储,因此直接使用公式h
i
(x)=g(w
i
·
x b
i
)得到存储在每个节点中的h值,标记为(h1,h2…
,h
n
)。其中,n的值等同于分布式计算设置的并行度的值;由于(x1,x2…
,x
k
)中的每一个增量样本的数据量较小,计算w与x的内积的过程不使用分布式计算过程;
[0087]
步骤2.2:对于分组后的矩阵,利用超限学习机的非线性映射函数计算矩阵x的激
活函数值h
i
(x)得到矩阵h,则n个分组分别计算得到n个矩阵h,标记为h1,h2…
,h
n
;
[0088]
步骤2.3:使用groupbykey转换操作,将每个h1,h2…
,h
n
分别发送到主节点中;
[0089]
步骤2.4:根据h1,h2…
,h
n
,利用公式(3)、(4)得到每一个增量训练样本输入后的更新权重,直至输入最后的增量训练样本,得到最终更新的输出权重;最后,将输出的权重值写入文件,将该文件保存至本地或hdfs中;
[0090][0091][0092]
其中,为h的伪逆矩阵,β
k
为第k次迭代的输出权重值,m
k
为第k次迭代的中间结果。
[0093]
这里要说明的是,虽然步骤1描述的过程属于离线学习过程,步骤2描述的过程属于在线学习过程,但在gaia系统中均属于大数据批处理的过程。因为即使步骤2描述的过程引入了增量学习样本,但在数据输入的层面也属于离线数据。而接下来描述的步骤3与步骤4的计算过程属于大数据流计算的过程,因为增量训练数据样本是持续给入,且输入的结束时间未知,用户可以根据不同的方式得到最后的输出权重。另外,图4中每一个形状所表示的内容与图3描述的一致。
[0094]
如果初始数据集是无界的且有多个来源,则说明是给定初始输出权重与增量训练数据的在线学习,且输入增量数据的结束时间未知。学习机将启动流数据处理环境,并按照公式(3)和公式(4)进行函数调用,计算输出权重;
[0095]
继续判断用户想要得到被更新的输出权重的方式,如果用户想根据输入增量训练数据的数量更新输出权重,学习机将按照滚动窗口模式,依据用户设定的增量训练数据的数量更新输出的权重值。gaia系统将根据用户设定的增量数据数量对执行公式(3)和公式(4)进行触发,其具体执行过程如图5所示;如果用户想根据输入增量训练数据的时间更新输出权重,学习机将按照时间窗口模式,依据用户设定的时间间隔更新输出的权重值。gaia系统将根据用户设定的时间间隔对执行公式(3)和公式(4)进行触发,其具体执行过程如图6所示。
[0096]
步骤3:如果初始数据集ucollection是无界的且有多个来源,则说明是给定初始输出权重与增量训练数据的在线学习,且输入增量数据的结束时间未知,在线持续输入增量训练样本矩阵,启动流数据处理环境,根据一定数量的增量训练样本进行训练,并按照公式(3)和公式(4)进行函数调用,计算输出权重;该步骤描述的是增量训练样本数据持续给入,且用户希望通过根据一定的增量训练样本数据量来更新输出权重的情况;通过source api读取数据源,所述的数据源包括与步骤2相同的数据,以及滚动窗口的大小,标记为countsize。构建初始数据集ucollection,启动流处理环境;所述的中间结果m0,以及初始输出权重值β0可以是本地数据,也可以是存储在hadoop分布式文件系统hdfs中。由于增量训练样本的输入结束时间未知,因此所述的给定增量训练样本矩阵(x1,x2…
,x
k
),以及(t1,t2…
,t
k
)通过apache kafka输入;包括:
[0097]
步骤3.1:使用pardo并行转换操作,根据预设的并行度值n将持续输入的增量训练样本矩阵(x1,x2…
,x
k
)进行分组,每组数据量的最大值标记为groupsize,其大小等于滚动窗口的大小/分布式计算设置的并行度的值;
[0098]
步骤3.2:数据被分发至每个组后,利用超限学习机的非线性映射函数h
i
(x)=g(w
i
·
x b
i
)计算矩阵x的激活函数值h
i
(x)得到矩阵h,则n个分组分别计算得到n个矩阵h,标记为h1,h2…
,h
n
;
[0099]
步骤3.3:使用groupbykey转换操作,将每个h1,h2…
,h
n
分别发送到主节点中;
[0100]
步骤3.4:当n的值达到countsize后,使用trigger操作对计算输出权重进行触发,读取h1,h2…
,h
n
;
[0101]
步骤3.5:根据公式(3)、公式(4)得到每一个增量训练样本输入后的更新权重,直至输入最后的增量训练样本,得到最终更新的输出权重;最后,将输出的权重值写入文件,将该文件保存至本地或hdfs中,删除已经得到的(h1,h2…
,h
n
);
[0102]
步骤3.6:重复步骤3.2~步骤3.5,计算每个增量训练样本产生的矩阵h,每当矩阵h的数量达到countsize后,都触发一次更新输出权重的过程,即每当增量数据达到countsize,系统都会将更新后的输出权重值反馈给用户。
[0103]
步骤4:如果初始数据集ucollection是无界的且有多个来源,在线持续输入增量训练样本矩阵,启动流数据处理环境,根据一定的增量训练样本输入时间间隔进行训练;该步骤描述的是增量训练样本数据持续给入,且用户希望通过根据一定的增量训练样本数据输入时间间隔来更新输出权重的情况;通过source api读取数据源,所述的数据源包括与步骤2相同的数据,以及时间窗口的大小,标记为timesize。构建初始数据集ucollection,启动流处理环境;所述的中间结果m0,以及初始输出权重值β0可以是本地数据,也可以是存储在hadoop分布式文件系统hdfs中,由于增量训练样本的输入结束时间未知,因此所述的给定增量训练样本矩阵(x1,x2…
,x
k
),以及(t1,t2…
,t
k
)通过apache kafka输入;包括:
[0104]
步骤4.1:使用pardo并行转换操作,根据预设的并行度值n将持续输入的增量训练样本矩阵(x1,x2…
,x
k
)进行分组;
[0105]
步骤4.2:当数据被分发至每个组后,利用超限学习机的非线性映射函数计算矩阵x的激活函数值h
i
(x)得到矩阵h,则n个分组分别计算得到n个矩阵h,标记为h1,h2…
,h
n
;
[0106]
步骤4.3:使用groupbykey转换操作,将每个h1,h2…
,h
n
分别发送到主节点中;
[0107]
步骤4.4:当时间达到预设时间间隔timesize后,使用trigger操作对计算输出权重进行触发,读取(h1,h2…
,h
n
);
[0108]
步骤4.5:根据公式(3)、公式(4)得到每一个增量训练样本输入后的更新权重,直至输入最后的增量训练样本,得到最终更新的输出权重;最后,将输出的权重值写入文件,将该文件保存至本地或hdfs中,删除已经得到的(h1,h2…
,h
n
);
[0109]
步骤4.6:重复步骤4.2~步骤4.5,计算每个增量训练样本产生的矩阵h,每当时间达到达到timesize后,都触发一次更新输出权重的过程,即每当时间间隔为timesize时,系统都会将更新后的输出权重值反馈给用户。
[0110]
步骤三:通过gaia系统读取用户输入的待分类数据集,利用训练后的分布式超限学习机输出数据的分类结果。
[0111]
使用gaia系统中的unified api开发本发明框架,通过仿真实验得出如下结论,本发明方法比于其他分布式计算系统(如hadoop、spark、flink等)具有更好的执行效率。在批处理模式下可实现海量吞吐,在流处理模式下可实现极速响应;再者,由于gaia系统是一种“批流融合”分布式计算系统,可通过构建的初始数据集ucollection自行判断判定启动批
处理环境或流处理环境,因此用户在使用该学习机进行数据分类时可不用关心数据的类型与来源,只需关注对数据的处理过程即可,为用户的使用带来了极大的便利。
再多了解一些
本文用于企业家、创业者技术爱好者查询,结果仅供参考。