1.本发明属于语音识别技术领域,具体涉及一种联合去混响的回声消除方法及装置。
背景技术:
2.近年来,人工智能技术和物联网在飞速发展落地,语音识别作为人机交互的重要手段,在其中具有关键性的作用,然而在实际落地过程中,复杂的声学应用环境中、严苛的用户体验限制着产品的有效落地推广,尤其针对具有扬声器和麦克风的音频系统,回声消除质量直接影响着用户语音识别交互体验。因此如何有效提升回声消除效果,是提升语音识别交互质量的关键问题。
3.目前常用的回声消除方法通过不同的自适应滤波器对回声通道进行估计,进而消除回声,该类方法具有一定的有效性,但忽略了环境中存在的混响,实际应用过程中往往会影响自适应滤波器的估计效果。同时还有另一类基于深度神经网络的回声消除方法,该类方法对解决回声消除过程中存在的非线性失真的问题上具有明显效果,但该类方法所需的训练样本比较苛刻,其实际落地的过程中,产品的算力、内存等因素制约了其发展。
技术实现要素:
4.为克服现有回升消除方法存在的技术缺陷,本发明公开了一种联合去混响的回声消除方法及装置。
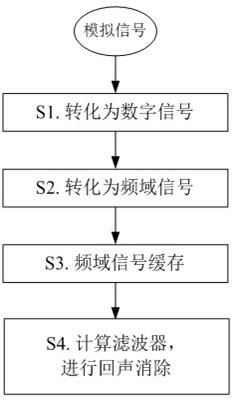
5.本发明所述联合去混响的回声消除方法,包括如下步骤:s1.利用麦克风阵列和音频播放装置分别获取模拟麦克风信号和模拟参考信号,通过adc分别转化为数字麦克风信号和数字参考信号;s2. 通过短时傅里叶变换将接收的数字麦克风信号和数字参考信号每个声道的时域信号分解成多个频点的频域信号,得到频域麦克风信号和频域参考信号;s3.逐帧进行下列操作:将当前帧和当前帧的若干过去帧的频域麦克风信号和频域参考信号作为缓存的频域信号存储到联合预测缓存器中;s4.通过自适应滤波器对联合预测缓存器中缓存的频域信号进行滤波,并对其中的频域麦克风信号进行回声消除;滤波采用的联合预测自适应滤波器w(l,k)=p(l,k)*
ꢀꢀꢀ
r(l,k);p(l,k)为第l帧第k个频点的频域转置信号buff_t(l,k)的自相关矩阵逆矩阵;r(l,k)为第l帧第k个频点的频域麦克风信号mic(l,k)与缓存的频域信号buff(l,k)的互相关矩阵;输出目标语音频域信号y:第l帧第k个频点的目标语音频域信号y(l,k)= mic(l,k)
‑
w
h
(l,k)* buff_t(l,k);
其中上标h表示共轭转置,mic(l,k)为第l帧第k个频点的频域麦克风信号。
6.优选的,所述s4步骤中的r(l,k)= λr(l
‑
1,k) (1
‑
λ) buff_t(l,k)conj(mic(l,k));λ为遗忘因子,r(l
‑
1,k) 为第l
‑
1帧第k个频点的频域麦克风信号mic(l
‑
1,k)与缓存的频域信号buff(l
‑
1,k)的互相关矩阵;buff_t(l,k)为第l帧第k个频点的频域转置信号;conj表示共轭。
7.优选的,所述s4步骤中的p(l,k)计算方式如下:骤中的p(l,k)计算方式如下:;λ为遗忘因子,p(l
‑
1,k)表示第l
‑
1帧第k个频点的频域转置信号buff_t(l
‑
1,k)的自相关矩阵逆矩阵,p(l,k)定义以此类推; buff_t(l,k)为第l帧第k个频点的频域转置信号,上标h表示共轭转置;kal(l,k)为第l帧第k个频点kalman增益矩阵。
8.优选的,所述s3步骤中,将当前帧和当前帧的(l
p
‑
1)帧的频域麦克风信号和(v
‑
1)帧频域参考信号作为缓存的频域信号存储到联合预测缓存器中;其中为l
p
参考信号线性预测长度,v为麦克风信号线性预测长度。
9.本发明还公开了一种联合去混响的回声消除装置,包括联合预测缓存器及与其连接的两条预处理支路,所述预处理支路包括串联的模数转换器和短时傅里叶变换模块;所述联合预测缓存器还连接有转置模块,所述转置模块还连接有联合预测自适应滤波器,所述两条预处理支路中用于与麦克风连接的支路的短时傅里叶变换模块与回声消除器和所述联合预测自适应滤波器连接;所述联合预测自适应滤波器还连接有共轭装置模块;所述共轭装置模块和转置模块共同连接有乘法器,所述乘法器连接所述回声消除器,所述回声消除器还连接有一个短时傅里叶变换模块本发明方案利用联合去混响的回声消除算法,可有效改善回声消除效果,提升语音交互质量。
附图说明
10.图1为本发明所述回声消除方法的一个具体流程示意图;图2为本发明所述回声消除装置的一个具体实施方式示意图;图3为本发明一个具体实施例中的输入信号波形示意图;图4为采用现有技术和本发明所述方法对图3中的输入信号进行回波消除后的输出信号波形对比示意图;图3和图4中波形图横坐标均为时间,纵坐标均为电压。
具体实施方式
11.下面对本发明的具体实施方式作进一步的详细说明。
12.本发明所述本发明所述回声消除方法可以包括以下步骤实现:s1.利用麦克风阵列和音频播放装置分别获取模拟麦克风信号和模拟参考信号,通过adc(模拟数字转换器)分别转化为数字麦克风信号和数字参考信号。
13.麦克风阵列中的麦克风个数n不小于2,当n=1时为单麦克风系统;多个麦克风形成的阵列结构不局限于规则几何形状阵列或非常规阵列,音频播放装置中的扬声器个数q不小于1,参考信号通道数体现在声源属性上,如立体声音源存在两路通道,则其产生的参考通道是有两路音源信号;而在对音质要求没有严苛要求时或传输带宽有限时,往往音源只需取一路信号或只有一路信号。
14.为对具体实施方式作进一步的详细说明,以最小系统为例,即采用单麦克风单扬声器系统进行介绍,此时n=1,q=1。
15.模拟麦克风信号从麦克风阵列的电学信号输出端获取,模拟参考信号为音频播放装置输入的电学模拟信号。
16.如图2所示,音频源发出的模拟参考信号通过喇叭转化为音频信号播放,播放后的音频信号混杂外部环境噪音等其他音频信号后被麦克风接收并转化为作为模拟麦克风信号的电学信号。
17.s2. 通过短时傅里叶变换将接收的数字麦克风信号和数字参考信号每个声道的时域信号分解成k1个频点的频域信号,一个具体实施方式中,在短时傅里叶的过程中,采用512点的傅里叶变换,此时频点数k1=257。
18.即将数字麦克风信号中当前第l帧的时域麦克风信号转换成频域麦克风信号mic(l)=[ mic1(l), mic2(l)
…
mic
n
(l)],在示例的最小系统中,mic(l)的维度为k1*1;n为麦克风个数;将数字参考信号中的时域参考信号转换成频域参考信号;ref(l)=[ ref1(l), ref2(l)
…
ref
q
(l)];q为扬声器个数;在示例的最小系统中,ref(l)的维度为k1*1;s3.逐帧进行下列操作:将当前帧和当前帧的若干过去帧的频域麦克风信号和频域参考信号作为缓存的频域信号存储到联合预测缓存器中;实际的数据先存储到联合预测缓存器后输入到滤波器中算法扩展和实现,抽象提取出来可适用于其他的滤波器方案。
[0019]
缓存数据处理应用线性预测的方法,需要过去帧已知数据进行预测,预测的长度阶数代表需要过去多少帧的数据,因此过去帧的数量通常根据线性预测长度确定。
[0020]
联合预测缓存器中存储的数据buff(l)可用下式表达buff(l)=[ buff_ref(l), buff_mic(l)]buff_ref(l)=[ref1(l
‑
l
p
1),
…
ref
1 (l),
…
ref
q
(l
‑
l
p
1),
…
ref
q (l)]buff_mic(l)= [mic
1 (l
‑
v 1),
…
mic
1 (l),
…
mic
n (l
‑
v 1),
…
mic
n (l)]例如假设参考信号线性预测长度l
p
=4,麦克风信号线性预测长度v=6,则buff(l)的维度为频点数*v*l
p
=257*(4 6),这个过程中存储了过去3帧和当前帧合计4帧的频域参考信号,并存储了过去5帧和当前帧合计6帧的频域麦克风信号,进而得到当前帧的联合预测缓存器buff(l),后续再结合线性预测的方法,并采用同一个自适应滤波器进行去混响与
线性回声消除处理;s4.通过自适应滤波器对频域信号的缓存数据buff(l)进行滤波,并对其中的频域麦克风信号进行回声消除;具体每个频点k的计算为:为方便算法实现处理,对第l帧第k个频点缓存的频域信号buff(l,k)进行转置处理:频域转置信号buff_t(l,k)= buff
t
(l,k)其中,buff
t
(l,k)的维度为 (4*1 6*1),上标t表示转置;计算kalman增益矩阵kal(l,k):其中,λ为遗忘因子,取值范围为0~1,可设λ=0.999,在当前最小系统中kal(l,k)的维度为 (4*1 6*1),上标h表示共轭转置;p(l
‑
1,k)表示第l
‑
1帧第k个频点的频域转置信号buff_t(l
‑
1,k)的自相关矩阵逆矩阵;为避免复杂的求逆过程,计算buff_t(l,k)的自相关矩阵的逆矩阵p(l,k):其中,p(l,k)的维度为 (4*1 6*1) *(4*1 6*1);进一步计算频域麦克风信号mic(l,k)与缓存的buff(l,k)频域信号的互相关矩阵r(l,k):r(l,k)= λr(l
‑
1,k) (1
‑
λ) buff_t(l,k)conj(mic(l,k))其中,r(l,k)的维度为(l
p
*q v*n)*n,conj表示共轭;n 为麦克风个数,q为扬声器个数;l
p
为麦克风信号线性预测长度,v为参考信号的线性预测长度;计算联合预测自适应滤波器w(l,k):w(l,k)=p(l,k)*
ꢀꢀꢀ
r(l,k)其中,w(l,k)的维度为(l
p
*q v*n)*n,w(l,k)为第l帧第k个频点联合预测滤波器;进行回声消除处理,计算目标语音频域信号y(l,k):y(l,k)= mic(l,k)
‑
w
h
(l,k)* buff_t(l,k)其中,y(l,k)的维度为n,y(l,k)为第l帧第k个频点经过回声消除器滤除后的目标语音频域信号;回声消除模块对系统的线性回声进行滤除。
[0021]
针对回声消除处理后的频域信号,可通过短时傅立叶逆变换模块 istft转化为时域信号,输出的时域信号可直接通过系统传递给下一个处理模块。
[0022]
本发明所述回声消除方法可采用一种联合去混响的回声消除装置进行,如图2所示,联合去混响的回声消除装置包括联合预测缓存器及与其连接的两条预处理支路,所述
预处理支路包括串联的模数转换器和短时傅里叶变换模块;所述联合预测缓存器还连接有转置模块,所述转置模块还连接有联合预测自适应滤波器,所述两条预处理支路中用于与麦克风连接的支路的短时傅里叶变换模块与回声消除器和所述联合预测自适应滤波器连接;所述联合预测自适应滤波器还连接有共轭装置模块;所述共轭装置模块和转置模块共同连接有乘法器,所述乘法器连接所述回声消除器,所述回声消除器还连接有一个短时傅里叶变换模块。两条预处理支路分别用于连接麦克风阵列的输出端和喇叭的电学信号输入端并处理模拟麦克风信号和模拟参考信号,其余模块可实现回声消除方法的其他步骤。
[0023]
与传统的回声消除方法相比,本发明方案利用联合去混响的回声消除算法,可有效改善回声消除效果,提升语音交互质量。如图3和图4所示给出本发明一个具体实施例,基于图2给出的回声消除装置,在音频源发出如图3下通道所示的信号后,经过喇叭播放,同时存在目标人声在距离麦克风3m处说命令词,在麦克风阵列输入端得到的输入信号波形图如图3上通道所示,该波形的语音成分主要包括环境噪声、喇叭播放的声音、目标人声;图4是将图3的信号进行回声消除处理后得到的波形图;图4中下通道为利用本发明图2所示回声消除装置处理后输出的波形图;上通道为利用现有技术的基于rls(最小二乘法)的回声消除方法处理得到的输出波形图。由图4可见,本发明处理后的目标语音,即图4上下两通道波形中出现的多个电压振幅较大部分,与回声残留值即电压振幅较小部分的差别更大,即本发明处理后的语音信号信噪比更高,表明本发明对回声消除效果更好。
[0024]
前文所述的为本发明的各个优选实施例,各个优选实施例中的优选实施方式如果不是明显自相矛盾或以某一优选实施方式为前提,各个优选实施方式都可以任意叠加组合使用,所述实施例以及实施例中的具体参数仅是为了清楚表述发明人的发明验证过程,并非用以限制本发明的专利保护范围,本发明的专利保护范围仍然以其权利要求书为准,凡是运用本发明的说明书及附图内容所作的等同结构变化,同理均应包含在本发明的保护范围内。
再多了解一些
本文用于企业家、创业者技术爱好者查询,结果仅供参考。

