1.本发明实施例涉及语音交互技术领域,特别涉及一种语音交互方法、系统、电子设备及存储介质。
背景技术:
2.语音交互通常是机器人等电子设备从环境中获取语音信号后,利用自动语音识别(automatic speech recognition,asr)处理将语音信号转换为文本信息,然后对文本信息进行自然语言理解(natural language processing,nlu)处理,获取文本信息中包含的意图并确定与该意图相对应的应答内容,然后通过文本转语音(text to speech,tts)处理将应答内容从文本转换到语音,最终输出语音,完成语音交互。由于nlu处理和tts处理都是基于asr处理得到的文本信息进行的,因此,asr处理结果的效果会直接影响语音交互的应答效果。而在实际的应用场景中,进行语音交互时所处的环境通常比较嘈杂,不可避免存在噪声等干扰,尤其是在公共环境,如机场、医院等场景,所处环境中的声音更嘈杂,干扰更大。在嘈杂环境下,获取的语音信号将包括很多背景噪音,例如周围人的聊天信息、环境噪音等,进而通过asr处理将语音信号转化为文本信息时会同时将背景噪声转化为文本信息,导致asr处理效果不好,出现电子设备乱回答、不停回答的问题。一种可行的解决办法是不断提高asr处理的准确率和精度以减少噪音输入。
3.然而,从现有的精度、准确度较高的asr模型的处理结果来看,仍然不能解决电子设备乱回答、不停回答的问题,继续提高asr处理的精度和准确度也很困难,因此,亟需提供一种新的语音交互方法来避免电子设备乱回答、不停回答的现象,提升嘈杂环境下的应答效果。
技术实现要素:
4.本发明实施例的目的在于提供一种语音交互方法、系统、电子设备及存储介质,使得在不需要提升asr处理精度和准确度的情况下能够避免电子设备乱回答、不停回答的现象,提升嘈杂环境下的应答效果。
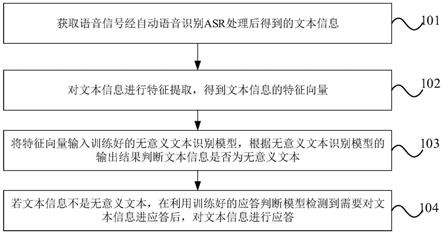
5.为达到上述目的,本发明的实施例提供了一种语音交互方法,包括以下步骤:获取语音信号经自动语音识别asr处理后得到的文本信息,其中,所述语音信号为从环境中获取的声音信号;对所述文本信息进行特征提取,得到所述文本信息的特征向量;将所述特征向量输入训练好的无意义文本识别模型,根据所述无意义文本识别模型的输出结果判断所述文本信息是否为无意义文本,其中,所述无意义文本为不符合常规表达方式的文本;若所述文本信息不是所述无意义文本,在利用训练好的应答判断模型检测到需要对所述文本信息进应答后,对所述文本信息进行应答。
6.本发明的实施方式还提供了一种语音交互系统,包括:获取模块,用于获取语音信号经自动语音识别asr处理后得到的文本信息,其中,所述语音信号为从环境中获取的声音信号;特征提取模块,用于对所述文本信息进行特征提取,得到所述文本信息的特征向量;
意义判断模块,用于将所述特征向量输入训练好的无意义文本识别模型,根据所述无意义文本识别模型的输出结果判断所述文本信息是否为无意义文本,其中,所述无意义文本为不符合常规表达方式的文本;应答模块,用于若所述文本信息不是所述无意义文本,在利用训练好的应答判断模型检测到需要对所述文本信息进应答后,对所述文本信息进行应答。
7.为实现上述目的,本发明的实施例还提供了一种电子设备,包括:至少一个处理器;以及,与所述至少一个处理器通信连接的存储器;其中,所述存储器存储有可被所述至少一个处理器执行的指令,所述指令被所述至少一个处理器执行,以使所述至少一个处理器能够执行以上所述的语音交互方法。
8.为实现上述目的,本发明的实施例还提供了一种计算机可读存储介质,存储有计算机程序,所述计算机程序被处理器执行时实现以上所述的语音交互方法。
9.本发明实施例提供的语音交互方法,在获取了环境中的语音信号经自动语音识别asr处理后得到的文本信息后,不直接由自然语音理解nlu进行意图理解和应答,而是先对文本信息进行特征提取,使得通过特征提取得到的文本信息的特征向量能够作为训练好的无意义文本识别模型的输入,从而根据无意义文本识别模型的输出结果来判断文本信息是否为无意义文本,并在判断处文本信息为有意义文本时,继续进行是否需要进行应答的判断,只有在需要进行应答的情况下进行应答。这样通过在应答之前对asr处理得到的文本信息进行检测,只有确定文本信息有意义且需要应答才进行应答,从而保证进行应答的信息是有意义以及需要进行应答的文本信息,排除了存在噪声时文本信息包含噪声对应的文本造成的应答错误,以及由于噪声等声音信息被当作语音信息获取造成不断应答的情况,即避免应答错误或对噪声进行应答,进而语音交互时提高在嘈杂环境中的应答效果。
10.另外,本发明实施例提供的语音交互方法,所述将所述特征向量输入训练好的无意义文本识别模型之前,所述方法还包括:构造同时包含所述无意义文本和有意义文本的初始训练集;对所述初始训练集中包含的所述无意义文本和所述有意义文本进行特征提取,将得到的所述特征向量作为识别训练集;利用所述识别训练集对所述无意义文本识别模型进行训练,得到训练好的所述无意义文本识别模型。利用无意义文本和有意义文本提取的特征进行训练,而不是无意义文本和有意义文本本身,使得用于训练的样本更能反映文本在是否有意义方面的特征,而不会过多参考文本的其他特征,使得模型对是否有意义的识别更加准确,提高了无意义文本识别模型的识别效果。
11.另外,本发明实施例提供的语音交互方法,所述进行特征提取,包括:
12.利用自然语言理解nlu模型中的lstm模型、unigram模型和bert模型从多个维度分别进行特征提取;所述进行特征提取之前,所述方法还包括:构造同时包含所述无意义文本和有意义文本的bert训练集;利用所述bert训练集对所述bert模型进行训练;利用开源数据集对所述unigram模型和所述lstm模型进行训练。进行特征提取时能够得到多个维度的特征向量,而不是单一的困惑度和分类结果,使得对文本信息进行是否有意义的识别时能够参考更多的信息,能够提高模型的准确率与召回率。并且使用有意义文本和无意义文本组成的训练集来训练bert模型,使得bert模型能够对文本是否有意义进行感知,提高bert模型输出结果在是否有意义方向的感知度。
13.另外,本发明实施例提供的语音交互方法,所述初始训练集和所述bert训练集中的所述无意义文本的获取方式,包括:从语料库中获取不符合常规表达方式的文本和符合
recognition,asr) 自然语言理解(natural language processing,nlu) 文本转语音(text to speech,tts)等处理进行语音交互的,其中,asr模块的识别结果的准确与否将直接影响语音交互过程中的应答效果。为了提高应答效果,常用的办法是提高asr处理的精度,但是现有的sar模型精度已经相对较高了,却仍然不能解决电子设备乱回答、不停回答的现象,继续提高asr处理的精度也很困难。因此,亟需提供一种新的语音交互方法来避免电子设备乱回答、不停回答的现象,提升嘈杂环境下的应答效果。
26.为了实现能够避免电子设备乱回答、不停回答的现象,提升嘈杂环境下的应答效果,本发明的实施例提供了一种语音交互方法,包括:获取语音信号经自动语音识别asr处理后得到的文本信息,其中,所述语音信号为从环境中获取的声音信号;对所述文本信息进行特征提取,得到所述文本信息的特征向量;将所述特征向量输入训练好的无意义文本识别模型,根据所述无意义文本识别模型的输出结果判断所述文本信息是否为无意义文本,其中,所述无意义文本为不符合常规表达方式的文本;若所述文本信息不是所述无意义文本,在利用训练好的应答判断模型检测到需要对所述文本信息进应答后,对所述文本信息进行应答。
27.本发明实施例提供的语音交互方法,在获取了环境中的语音信号经自动语音识别asr处理后得到的文本信息后,不直接由自然语音理解nlu进行意图理解和应答,而是先对文本信息进行特征提取,使得通过特征提取得到的文本信息的特征向量能够作为训练好的无意义文本识别模型的输入,从而根据无意义文本识别模型的输出结果来判断文本信息是否为无意义文本,并在判断处文本信息为有意义文本时,继续进行是否需要进行应答的判断,只有在需要进行应答的情况下进行应答。这样通过在应答之前对asr处理得到的文本信息进行检测,只有确定文本信息有意义且需要应答才进行应答,从而保证进行应答的信息是有意义以及需要进行应答的文本信息,排除了存在噪声时文本信息包含噪声对应的文本造成的应答错误,以及由于噪声等声音信息被当作语音信息获取造成不断应答的情况,即避免应答错误或对噪声进行应答,进而语音交互时提高在嘈杂环境中的应答效果。
28.为使本发明实施例的目的、技术方案和优点更加清楚,下面将结合附图对本发明的各实施方式进行详细的阐述。然而,本领域的普通技术人员可以理解,在本发明各实施方式中,为了使读者更好地理解本技术而提出了许多技术细节。但是,即使没有这些技术细节和基于以下各实施方式的种种变化和修改,也可以实现本技术所要求保护的技术方案。
29.下面将结合图1
‑
图5对本实施例的滤波特性的检测方法的实现细节进行具体的说明,以下内容仅为方便理解提供的实现细节,并非实施本方案的必须。
30.参考图1,在一些实施例中,语音交互方法应用于如机器人、平板等能够进行语音交互的电子设备中,具体包括:
31.步骤101,获取语音信号经自动语音识别asr处理后得到的文本信息。
32.具体地,从环境中获取语音信号,然后对语音信号进行asr处理,将语音信号转化为文本信息。
33.需要说明的是,本实施例中语音信号为从环境中获取的声音信号,语音信号中不仅包含用户的语音指令,还可能包括用户所在环境中的其他语音内容,如某个用户在具有播放歌曲的需求时,在机器人附近下达语音指令“播放歌曲a”,在该用户周围还有其他用户正在交谈,交谈内容包括“好久不见”,则机器人可能从环境中捕捉到该夹杂有其他用户谈
话声的语音指令为“播放好久歌见曲a”。
34.步骤102,对文本信息进行特征提取,得到文本信息的特征向量。
35.本实施例中,利用ulr模型提取文本信息的特征向量,进一步地,在一些实施例中ulr模型包括:语言模型中的lstm模型和unigram模型,以及语言表示模型中的bert模型,此时步骤102实际为:利用自然语言理解nlu模型中的lstm模型、unigram模型和bert模型从多个维度分别进行特征提取,得到文本信息在多个维度上的特征向量。
36.值得一提的是,进行特征提取时利用了多个模型——lstm模型、unigram模型和bert模型,能够得到多个维度的特征向量,而不是单一的困惑度和分类结果,使得对文本信息进行是否有意义的识别时能够参考更多的信息,能够提高模型的准确率与召回率。
37.在一个例子中,文本信息在多个维度上的特征向量可以用以下表达式表示:
38.bert_prob=bert(s)
[0039][0040][0041][0042][0043][0044][0045][0046][0047][0048]
其中,s代表文本,|s|代表文本长度,n代表词汇个数,<x>代表取向上取整数,bert(s)代表经过bert模型得到的概率值;p
m
(s)=p(w
n
|w1,w2,
……
,w
n
‑1)代表lstm语言模型中
文本s出现的概率,w
n
为s中的词汇;p
u
(s)=p(w1)p(w2)
…
p(w
n
)代表unigram语言模型中文本s出现的概率,w
n
为s中的词汇;p
m
(w)=p(wi|w1,w2,
……
,w i
‑
1)代表lstm语言模型s中当前词汇w出现的概率,w=w
i
;pu(w)=p w1)p(w2)
…
p(w
n
)代表unigram语言模型s中当前词汇w出现的概率,w=w
i
。
[0049]
进一步地,在一些实施例中,无意义文本识别模型为极致梯度提升xgboost模型。
[0050]
值得一提的是,通过自然语言处理技术判断文本是否有意义的方法通常是采用语言模型的困惑度(perplexity,ppl)大小或者使用深度学习分类模型判断。但是这两种方法都存在一定的不足,ppl值大小代表一定的趋势,值越大代表该文本出现的概率越小,但是没有一个确定的阈值表示大于该值的文本都是无意义的、使用深度学习分类模型判断无意义文本的召回率较低。因此,用集成模型xgboost判断文本是否有意义时,进行判断时能够依赖各种特征如学习分类模型的结果和语言模型的ppl等特征,能够提高模型的准确率与召回率。
[0051]
步骤103,将特征向量输入训练好的无意义文本识别模型,根据无意义文本识别模型的输出结果判断文本信息是否为无意义文本。
[0052]
本实施例中,无意义文本是不符合常规表达方式的文本,即文本中文字的表述是常用的表达方式。
[0053]
需要说明的是,一般而言,若是文本信息是语音指令中夹杂环境噪声等干扰信息的文本,则文本信息的内容被干扰信息打断,就不能在常用中的表达方式中找到,也就是说,无意义文本实际和实际下达的指令不同,如果对其进行应答,应答也必然和指令中蕴含的意图不同,即应答错误。因此,判断是否为无意义文本的本质是在判断文本信息是否能够被正确应答,如果不能被正确应答,也就不需要进行应答了。
[0054]
步骤104,若文本信息不是无意义文本,在利用训练好的应答判断模型检测到需要对文本信息进应答后,对文本信息进行应答。
[0055]
本实施例中,即使文本是有意义文本,即受到干扰小或几乎没有干扰,文本信息也不一定需要进行应答,如文本信息为“我在看书”、“天气晴”等内容时,用户可能并不需要电子设备进行应答,或者,asr可能识别周围人的聊天信息,导致机器人不停应答的现象,例如“妈妈我也要去”“老婆拜拜了”不是对机器人下达指令,也不需要进行应答。因此,在确定文本信息之后,还需要判断是否需要对文本信息进行应答。
[0056]
此外,根据对步骤103的说明可知,当判断无意义文本时,不需要进行应答。因此,在一些实施例中,参考图2,步骤103为:将特征向量输入训练好的无意义文本识别模型,根据无意义文本识别模型的输出结果判断文本信息是否为无意义文本,若是,执行步骤105,若否,执行步骤106。
[0057]
步骤103之后还包括以下步骤:
[0058]
步骤105,放弃对文本信息进行应答。
[0059]
步骤106,利用训练好的应答判断模型判断是否需要对文本信息进应答,若是,执行步骤107,若否,执行步骤105。
[0060]
步骤107,对文本信息进行应答。
[0061]
上述步骤105
‑
107实际是:对于文本信息,首先调用无意义文本识别模型判断文本信息是否有意义,如果没有意义则停止后续处理,不应答,如果有意义则调用应答判断模
型,判断对该文本是否进行应答。例如asr识别文本为“请问航班在哪里值机”,该文本经过无意义文本识别模型,结果为有意义文本,则继续调用应答判断模型,判断结果为需要应答,机器人给出应答结果;对于文本“没事我这是在向值机算我”,经过无意义文本识别模型结果为无意义文本,则不再调用应答判断模型,机器人不应答。
[0062]
需要说明的是,上述步骤106和步骤107相当于步骤104,此处只是给出了一种具体地实现方式,还可能对其他步骤进行拆分或合并等,此处就不再一一赘述了。
[0063]
上述实施例说明了如何利用模型进行语音交互,以下实施例将对如何对模型进行训练进行说明。
[0064]
在一些实施例中,步骤103之前还包括步骤108:对无意义文本识别模型进行训练,参考图3,步骤108具体包括以下步骤:
[0065]
步骤1081,构造同时包含无意义文本和有意义文本的初始训练集。
[0066]
本实施例中,初始训练集可以是已有的开源数据集,也可以是任一种包含无意义文本和有意义文本的语料库。本实施例不对初始训练集的中文本数量和数据集的大小进行限定,也不对数据集中有意义文本和无意义文本的比例等进行限定。
[0067]
需要说明的是,初始数据集中的文本不是单纯的文本,而是带有是否意义标注的文本,如文本“请开灯”被标注为有意义、文本“回答我比分的温暖”被标注为无意义等。
[0068]
步骤1082,对初始训练集中包含的无意义文本和有意义文本进行特征提取,将得到的特征向量作为识别训练集。
[0069]
步骤1083,利用识别训练集对无意义文本识别模型进行训练,得到训练好的无意义文本识别模型。
[0070]
需要说明的是,本实施例中不对训练的方式进行限定,如训练目标等,可以根据实际情况确定如何训练。
[0071]
值得一提的是,本实施例中利用无意义文本和有意义文本提取的特征进行训练,而不是无意义文本和有意义文本本身,使得用于训练的样本更能反映文本在是否有意义方面的特征,而不会过多参考文本的其他特征,使得模型对是否有意义的识别更加准确,提高了无意义文本识别模型的识别效果。
[0072]
还需要说明的是,步骤1082中进行特征提取可以是利用自然语言理解nlu模型中的lstm模型、unigram模型和bert模型从多个维度分别进行特征提取实现的,进一步地,在一些实施例,在步骤108之前还包括步骤109:对nlu模型进行训练,其中,nlu模型包括lstm模型、unigram模型和bert模型,参考图4,步骤109具体包括以下步骤:
[0073]
步骤1091,构造同时包含无意义文本和有意义文本的bert训练集。
[0074]
本实施例中,bert训练集的含义和步骤1081中的初始训练集含义大致相同,此处就不一一赘述了。
[0075]
步骤1092,利用bert训练集对bert模型进行训练。
[0076]
本实施例实际是利用bert训练集对bert模型进行优化。
[0077]
值得一提的是,使用有意义文本和无意义文本组成的训练集来训练bert模型,使得bert模型能够对文本是否有意义进行感知,提高bert模型输出结果在是否有意义方向的感知度。
[0078]
步骤1093,利用开源数据集对unigram模型和lstm模型进行训练。
[0079]
本实施例中,开源数据集可以是例如维基百科、小说、新闻等,当然以上仅为具体的举例说明,还可以是其他类型的开源数据集,此处就不再一一赘述了。
[0080]
值得一提的是,由于使用开源数据集,因此具有大量的训练数据,能够更好地对语言模型进行无监督学习,避免训练不能满足精度、准确度等方面的要求。
[0081]
在构造包含无意义文本和有意义文本的数据集的过程中,如步骤1081中初始训练集和步骤1091中的bert训练集的构造,需要获取大量的无意义文本以提高训练效果,但是大量的无意义文本意味着大量的人工标注工作,因此,在一些实施例中,参考图5,获取无意义文本的方式包括:
[0082]
步骤501,从语料库中获取不符合常规表达方式的文本和符合常规表达方式的文本。
[0083]
步骤502,对符合常规表达方式的文本随机进行调整操作,调整操作包括以下操作中的一种或组合:乱序处理、切割处理和拼接处理。
[0084]
本实施例中,对符合常规表达式的文本,即有意义文本进行调整,如将切割后与其他文本或其他文本切割后的部分进行拼接、将文本的字符顺序打乱、将两个文本进行拼接等,从而使得有意义文本通过调整出现语句不同等情况,模拟实际场景中受到干扰的语音指令转化后的文本。
[0085]
在一个例子中,将正常的有意义文本“你长得真漂亮”随机打乱为“长你得漂亮真”,将正常的有意义文本“你长得真漂亮”随机切断为“你长得真”,将两句正常的有意义文本“你长得真漂亮”“我想问下怎么办理值机”切割并拼接为“你长得真办理值机”等。
[0086]
步骤503,将调整后的符合常规表达方式的文本和不符合常规表达方式的文本,作为初始训练集和bert训练集中的无意义文本。
[0087]
值得一提的是,由于周围环境噪声导致无意义文本的形势多种多样,如果单纯依靠人工查找、构造和标注训练数据需要耗费的大量的人力成本。步骤501和步骤502直接通过有意义文本的切割和随机组合来生成新的无意义文本,不要人工判断和打标注,在扩大数据集容量的同时还不需要增加人力资源的消耗。
[0088]
此外,考虑到有一些bert模型实际是对输入进行编码后再解码,因此其输出结果和输入比较相似,而无意义文本识别模型输入的多个特征中包括bert模型的输出结果,也就是说,使用同一个数据集训练bert模型和无意义文本识别模型时会存在用于训练bert模型的数据和用于训练无意义文本识别模型的数据有一定内容重合,进而导致训练后的无意义文本识别模型存在过拟合问题,上述bert训练集和初始训练集的交集为空集,即使用两份不重合的数据集分别训练bert与无意义文本识别模型,这样就能避免了无意义文本识别模型的过拟合问题。
[0089]
进一步地,在一些实施例中,为了使bert训练集和初始训练集的交集为空,可以先获取一个较大的包含无意义文本和有意义文本的数据集d,然后对数据集d进行分割得到两个数据集d1和d2,d1和d2分别作为bert训练集和初始训练集,数据集d1和d2大小可以相同,也可以不同,有意义文本和无意义文本的数量、比例等可以相同,也可以不同,此处就不一一赘述了。
[0090]
另外,本发明提供的语音交互方法中还涉及应答判断模型,在一些实施例中,应答判断模型为fasttext模型,步骤104之前使用训练好的fasttext模型之前,利用预先构造的
应答数据集对fasttext模型进行训练,得到训练好的fasttext模型,其中,应答数据集包括需要进行应答的文本和不需要进行应答的文本,即文本被标注了是否需要进行应答。
[0091]
为了更好地说明本发明的效果,以下将本发明提供语音交互和传统提高asr精度的语音交互方法的实验结果进行对比:
[0092]
asr处理得到的文本传统方法本发明请问南航在哪里值机应答应答没事我这是在向值机算我应答不应答妈妈我也要去应答不应答便问我应答不应答
[0093]
如上表,可以看出但干扰过大时,传统方法不能避免由于根据错误文本进行应答导致的应答错误问题,如asr处理得到的文本为“没事我这是在向值机算我”传统方法仍然进行应答。
[0094]
上面各种方法的步骤划分,只是为了描述清楚,实现时可以合并为一个步骤或者对某些步骤进行拆分,分解为多个步骤,只要包括相同的逻辑关系,都在本专利的保护范围内;对算法中或者流程中添加无关紧要的修改或者引入无关紧要的设计,但不改变其算法和流程的核心设计都在该专利的保护范围内。
[0095]
本发明的实施例还提供了一种语音识别系统,如图6所示,包括:
[0096]
获取模块601,用于获取语音信号经自动语音识别asr处理后得到的文本信息,其中,语音信号为从环境中获取的声音信号。
[0097]
特征提取模块602,用于对文本信息进行特征提取,得到文本信息的特征向量。
[0098]
意义判断模块603,用于将特征向量输入训练好的无意义文本识别模型,根据无意义文本识别模型的输出结果判断文本信息是否为无意义文本,其中,无意义文本为不符合常规表达方式的文本。
[0099]
应答模块604,用于若文本信息不是无意义文本,在利用训练好的应答判断模型检测到需要对文本信息进应答后,对文本信息进行应答。
[0100]
不难发现,本实施例为与上述方法实施例相对应的系统实施例,本实施例可与方法实施例互相配合实施。方法实施例中提到的相关技术细节在本实施例中依然有效,为了减少重复,这里不再赘述。相应地,本实施例中提到的相关技术细节也可应用在方法实施方式中。
[0101]
值得一提的是,本实施例中所涉及到的各模块均为逻辑模块,在实际应用中,一个逻辑单元可以是一个物理单元,也可以是一个物理单元的一部分,还可以以多个物理单元的组合实现。此外,为了突出本发明的创新部分,本实施例中并没有将与解决本发明所提出的技术问题关系不太密切的单元引入,但这并不表明本实施例中不存在其它的单元。
[0102]
本发明实施例还提供了一种电子设备,如图7所示,包括:
[0103]
至少一个处理器701;以及,
[0104]
与所述至少一个处理器701通信连接的存储器702;其中,
[0105]
所述存储器702存储有可被所述至少一个处理器执行的指令,所述指令被所述至少一个处理器701执行,以使所述至少一个处理器701能够执行本发明实施例提供的语音识别方法。
[0106]
其中,存储器和处理器采用总线方式连接,总线可以包括任意数量的互联的总线和桥,总线将一个或多个处理器和存储器的各种电路链接在一起。总线还可以将诸如外围设备、稳压器和功率管理电路等之类的各种其他电路链接在一起,这些都是本领域所公知的,因此,本文不再对其进行进一步描述。总线接口在总线和收发机之间提供接口。收发机可以是一个元件,也可以是多个元件,比如多个接收器和发送器,提供用于在传输介质上与各种其他装置通信的单元。经处理器处理的数据通过天线在无线介质上进行传输,进一步,天线还接收数据并将数据传送给处理器。
[0107]
处理器负责管理总线和通常的处理,还可以提供各种功能,包括定时,外围接口,电压调节、电源管理以及其他控制功能。而存储器可以被用于存储处理器在执行操作时所使用的数据。
[0108]
本领域技术人员可以理解实现上述实施例方法中的全部或部分步骤是可以通过程序来指令相关的硬件来完成,该程序存储在一个存储介质中,包括若干指令用以使得一个设备(可以是单片机,芯片等)或处理器(processor)执行本技术各个实施例所述方法的全部或部分步骤。而前述的存储介质包括:u盘、移动硬盘、只读存储器(rom,read
‑
only memory)、随机存取存储器(ram,random access memory)、磁碟或者光盘等各种可以存储程序代码的介质。
[0109]
本领域的普通技术人员可以理解,上述各实施方式是实现本发明的具体实施例,而在实际应用中,可以在形式上和细节上对其作各种改变,而不偏离本发明的精神和范围。
再多了解一些
本文用于企业家、创业者技术爱好者查询,结果仅供参考。

