本发明涉及一种转换方法,特别是涉及一种语音转换虚拟脸部图像的方法。
背景技术:
动画、游戏和电影等行业常会创建虚拟角色,而在创造虚拟角色的其中一个重要的技术为使虚拟角色讲话时能够具有自然流畅并与声音同步的嘴型动作,为达到声音与嘴型动作的同步,设计师需要根据音频的内容在时间轴上调整嘴型配置,非常消耗时间和人力,再者,事先制作出动画,无法依现场气氛做出变化,因此现有多家厂商致力发展实时语音驱动的虚拟角色说话的技术。
然而,现有实时语音驱动的虚拟角色说话的技术多是将声音先转至文字,再由文字转换成虚拟角色的嘴型图像,先转换成文字的转换处理的时间过长,无法得到实时的效果。
技术实现要素:
本发明的目的在于提供一种能实时将语音转换虚拟脸部图像的方法。
本发明的语音转换虚拟脸部图像的方法,适用于将用户的语音转换成虚拟脸部图像,由计算机系统执行,所述计算机系统存储多帧相关于数字角色于发出多种不同音素时及一静音音素所对应的多种不同嘴型的嘴型图像、多笔谈话,及多个分别对应所述谈话的音素串行,及相关所述用户的语音特征数据,每一嘴型图像对应于所述音素及静音音素的其中一者,每一谈话所对应的音素串行包含多个排列组合出该谈话的音素,每一谈话包含多个谈话片段,每一谈话片段对应所对应的音素串行中的所述音素的其中一者,所述计算机系统包含用于连续地撷取当前声音的声音撷取单元,所述语音转换虚拟脸部图像的方法包含步骤(a)、步骤(b)、步骤(c)、步骤(d)、步骤(e),及步骤(f)。
所述步骤(a)中,所述计算机系统将每一谈话的每一谈话片段及其对应的音素进行机器学习演算,以建立出用于将语音片段转换成音素的音素转换模型。
所述步骤(b)中,根据所述语音特征数据,将所述声音撷取单元所撷取到的当前声音滤除所述用户的语音外的声音,以获得滤除后声音数据。
所述步骤(c)中,所述计算机系统判定所述滤除后声音数据是否包括语音片段。
所述步骤(d)中,当判定出所述滤除后声音数据包括语音片段时,所述计算机系统利用所述音素转换模型,将所述滤除后声音数据所包括的语音片段转换成目标音素。
所述步骤(e)中,所述计算机系统根据所述目标音素,从所述嘴型图像获得对应于所述目标音素的目标嘴型图像。
所述步骤(f)中,所述计算机系统根据所述目标嘴型图像获得至少一相关于所述数字角色的虚拟脸部图像。
较佳地,本发明的语音转换虚拟脸部图像的方法,所述计算机系统还存储多帧相关于所述数字角色的多种不同脸部表情的表情图像,每一种脸部表情对应于指示出所述脸部表情的表情参数,每一表情图像对应于所述脸部表情的其中一者所对应的表情参数,所述声音撷取单元所撷取到的当前的语音片段包含至少一语音子片段,在步骤(c)后及步骤(f)前还包含以下步骤:
(g)当判定出所述滤除后声音数据包括语音片段时,对于所述滤除后声音数据包括的语音片段的每一语音子片段,利用用于将语音子片段转换成表情参数的表情转换模型,将所述语音子片段转换成目标表情参数;及
(h)对于每一目标表情参数,根据所述目标表情参数,从所述表情图像获得对应所述目标表情参数的目标表情图像;
其中,在步骤(f)中,还根据步骤(h)所获得的目标表情图像获得该至少一虚拟脸部图像。
较佳地,本发明的语音转换虚拟脸部图像的方法,在步骤(h)前还包含以下步骤:
(i)当判定出所述滤除后声音数据不包括语音片段时,将静音表情参数作为所述目标表情参数。
较佳地,本发明的语音转换虚拟脸部图像的方法,所述计算机系统还存储多笔影音数据,每一影音数据包括多帧相关于训练者演说的脸部图像及多个分别对应所述脸部图像的音频片段,在步骤(g)前还包含以下步骤:
(j)对于所述影音数据的每一脸部图像,获得所述脸部图像中对应于所述训练者脸部的其中一器官的器官部分;
(k)对于所述影音数据的每一脸部图像,根据所述脸部图像中的器官部分获得器官特征;
(l)对于所述影音数据的每一脸部图像,根据所述脸部图像对应的器官特征将所述脸部图像进行表情辨识,以获得所述脸部图像所对应的所述训练者的表情辨识结果;及
(m)将每一脸部图像所对应的表情辨识结果及音讯片段进行机器学习演算,以建立所述表情转换模型。
较佳地,本发明的语音转换虚拟脸部图像的方法,在步骤(j)中,所述器官部分为对应所述训练者脸部的眉毛。
较佳地,本发明的语音转换虚拟脸部图像的方法,在步骤(l)中,所述表情辨识结果是高兴、生气、难过,及无表情的其中一者。
较佳地,本发明的语音转换虚拟脸部图像的方法,在步骤(b)前还包含以下步骤:
(n)判定所述声音撷取单元所撷取到的当前声音是否包括语音片段;在判定出所述声音撷取单元所撷取到的当前声音包括语音片段后,进行步骤(b)。
较佳地,本发明的语音转换虚拟脸部图像的方法,在步骤(e)前还包含以下步骤:
(o)在判定出所述声音撷取单元所撷取到的当前声音不包括语音片段后,将所述静音音素作为所述目标音素。
较佳地,本发明的语音转换虚拟脸部图像的方法,在步骤(c)后还包含以下步骤:
(p)在判定出所述滤除后声音数据不包括语音片段后,将所述静音音素作为所述目标音素。
本发明的有益效果在于:借由所述计算机系统撷取所述当前语音片段之后,利用所述音素转换模型,以快速获得对应于所述目标音素的所述目标嘴型图像,并根据所述目标嘴型图像实时获得该至少一虚拟脸部图像,以达到快速转换的效果。
附图说明
本发明的其他的特征及功效,将于参照图式的实施方式中清楚地呈现,其中:
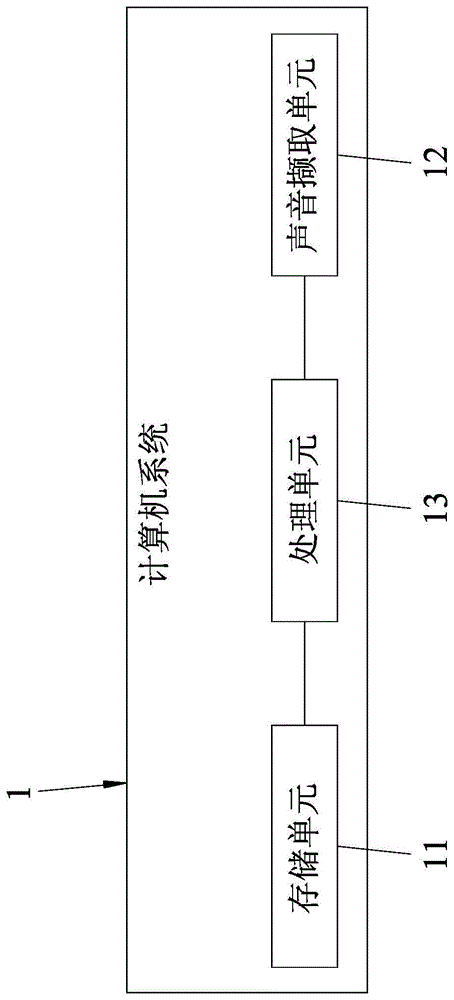
图1是一方块图,说明用于实施本发明语音转换虚拟脸部图像的方法的一计算机系统;
图2是一示意图,说明本发明语音转换虚拟脸部图像的方法的该实施例的每一音素对应的嘴型图像;
图3是一流程图,说明本发明语音转换虚拟脸部图像的方法的一实施例的一音素转换模型建立程序;
图4是一流程图,说明该实施例的一表情转换模型建立程序;及
图5是一流程图,说明该实施例的一语音转换虚拟脸部图像程序。
具体实施方式
在本发明被详细描述前,应当注意在以下的说明内容中,类似的组件是以相同的编号来表示。
参阅图1,本发明语音转换虚拟脸部图像的方法的一实施例,适用于将一用户的语音转换成虚拟脸部图像,该方法是由一计算机系统1执行,该计算机系统1包含一存储单元11、一声音撷取单元12及一电连接该存储单元11及该声音撷取单元12的处理单元13。
该存储单元11存储有多帧相关于一数字角色于发出多种不同音素(phoneme)时及一静音音素所对应的多种不同嘴型的嘴型图像、多笔谈话、多笔影音数据、一相关该用户的语音特征数据,及多帧相关于该数字角色的多种不同脸部表情的表情图像。值得注意的是,在本实施例中,所述音素例如为oo、iy、ee、aa、ww、ll、er、uu、fv、mm、ch,以及dd等,每一嘴型图像对应于所述音素的其中一者(如图2所示),该语音特征数据例如包括相关于该使用者的音频、说话频率等特征,所述嘴型图像例如为三维图像,但不以此为限。每一谈话包含多个谈话片段,每一影音数据包括多帧相关于一训练者演说的脸部图像及多个分别对应所述脸部图像的音频片段,每一种脸部表情对应于一指示出该脸部表情的表情参数,每一表情图像对应于所述脸部表情的其中一者所对应的表情参数。
该声音撷取单元12用于连续地撷取当前声音。在本实施例中,该声音撷取单元12例如为麦克风,但不以此为限。
参阅图2、3、4,本发明语音转换虚拟脸部图像的方法的该实施例包含一音素转换模型建立程序2、一表情转换模型建立程序3,及一语音转换虚拟脸部图像程序4。
参阅图1、3,该音素转换模型建立程序2包含步骤21~23,以下详述图3所示的该音素转换模型建立程序2的各个步骤。
在步骤21中,该处理单元13从一有声字典提取所述音素的特征。
在步骤22中,对于每一谈话,该处理单元13根据所述音素的特征及该谈话,产生一包含多个排列组合出该谈话的音素的音素串行,该谈话的每一谈话片段对应该音素串行中的所述音素的其中一者。
在步骤23中,该处理单元13将每一谈话的每一谈话片段及其对应的音素进行机器学习演算,例如卷积神经网络(convolutionalneuralnetwork,cnn),以建立出一用于将语音片段转换成音素的音素转换模型。
参阅图1、4,该表情转换模型建立程序3包含步骤31~34,以下详述图4所示的该表情转换模型建立程序3的各个步骤。
在步骤31中,对于该存储单元11存储的所述影音数据的每一脸部图像,该处理单元13获得该脸部图像中对应于该训练者脸部的眉毛部分。
在步骤32中,对于该存储单元11存储的所述影音数据的每一脸部图像,该处理单元13根据该脸部图像中的眉毛部分获得一眉毛特征。值得注意的是,在本实施例中,步骤31、32中该处理单元13是获得眉毛部分及眉毛特征,在其他实施方式也可获得其他脸部器官的部分及特征,不以此为限。
在步骤33中,对于该存储单元11存储的所述影音数据的每一脸部图像,该处理单元13根据该脸部图像对应的眉毛特征将该脸部图像进行表情辨识,以获得该脸部图像所对应的该训练者的表情辨识结果。值得注意的是,在本实施例中,所述表情辨识结果是高兴、生气、难过,及无表情的其中一者,在其他实施方式中所述表情辨识结果更可包括其他表情,不以此为限。
在步骤34中,该处理单元13将每一脸部图像所对应的表情辨识结果及音讯片段进行机器学习演算,以建立一用于将语音子片段转换成表情参数的表情转换模型。值得注意的是,在本实施例中,每一脸部图像所对应的音频片段的时间长度与每一语音子片段的时间长度相等,即播放一帧图像的时间。
参阅图1、5,该语音转换虚拟脸部图像程序4包含步骤41~49,以下详述图5所示的该语音转换虚拟脸部图像程序4的各个步骤。
在步骤41中,该处理单元13判定该声音撷取单元12所撷取到的当前声音是否包括语音片段。当该处理单元13判定出该声音撷取单元12所撷取到的当前声音不包括语音片段时,流程进行步骤42;而当该处理单元13判定出该声音撷取单元12所撷取到的当前声音包括语音片段时,则流程进行步骤43。
在步骤42中,该处理单元13将该静音音素作为一目标音素,且将静音表情参数作为目标表情参数。
在步骤43中,该处理单元13根据该语音特征数据,将该声音撷取单元12所撷取到的当前声音滤除该用户的语音外的声音,以获得一滤除后声音数据。
在步骤44中,该处理单元13判定该滤除后声音数据是否包括语音片段。当该处理单元13判定出该滤除后声音数据不包括语音片段时,流程进行步骤42;而当该处理单元13判定出该滤除后声音数据包括语音片段时,则流程进行步骤45及步骤47。
在步骤45中,该处理单元13利用该音素转换模型,将该滤除后声音数据所包括的语音片段转换成一目标音素。
在步骤42或45后的步骤46中,该处理单元13根据该目标音素,从所述嘴型图像获得对应于该目标音素的一目标嘴型图像。
在步骤47中,对于该滤除后声音数据包括的语音片段的每一语音子片段,该处理单元13利用该表情转换模型,将该语音子片段转换成一目标表情参数。
在步骤42或步骤47后的步骤48中,对于每一目标表情参数,该处理单元13根据该目标表情参数,从所述表情图像获得对应该目标表情参数的一目标表情图像。
要特别注意的是,在本实施例中,该表情转换模型包括二次指数平滑法(doubleexponentialsmoothingmethod),即不同时间的语音子片段拥有不同的权重,越接近当前时间的语音子片段权重越大,在步骤47中,对于当前语音片段的该至少一语音子片段的每一者,该处理单元13根据该语音子片段前的所有语音片段以及该语音子片段,进行预测以转换出该目标表情参数,利用二次指数平滑法可使得步骤48中所获得该目标表情图像与前一时段获得的目标表情图像较为连贯,由于本发明的特征并不在于本领域技术人员所已知的二次指数平滑法,因此为了简洁,故在此省略了二次指数平滑法的细节。
要再特别注意的是,在本实施例中,步骤45、46与步骤47、48同时进行,在其他实施方式中,步骤45、46可在步骤47、48前或后执行,不以此为限。
在步骤46及步骤48后的步骤49中,该处理单元13根据该目标嘴型图像及该至少一目标表情图像,获得至少一相关于该数字角色的虚拟脸部图像。
要再特别注意的是,当该当前语音片段仅包含一语音子片段时,在步骤47中,该处理单元13将该语音子片段转换成一目标表情参数,并在步骤48中,该处理单元13从所述表情图像获得对应该目标表情参数的一目标表情图像,最后在步骤49中,该处理单元13根据该目标嘴型图像及该目标表情图像,获得一虚拟脸部图像;而当该当前语音片段包含多个语音子片段时,在步骤47中,该处理单元13将所述语音子片段转换成多个目标表情参数,并在步骤48中,该处理单元13分别从所述表情图像获得对应所述目标表情参数的多个目标表情图像,最后在步骤49中,该处理单元13根据该目标嘴型图像及所述目标表情图像,获得多帧虚拟脸部图像,表示所述虚拟脸部图像具有相同的嘴型。
综上所述,本发明语音转换虚拟脸部图像的方法,借由该处理单元13将所述谈话及音素串行进行机器学习演算,以建立该音素转换模型,且将所述脸部图像所对应的表情辨识结果及所述音讯片段进行机器学习演算,以建立该表情转换模型,使得该声音撷取单元12撷取该当前语音片段后,该处理单元13利用该音素转换模型及该表情转换模型,快速获得对应于该目标音素的该目标嘴型图像及该至少一目标表情图像,并根据该目标嘴型图像及该至少一目标表情图像实时获得该至少一虚拟脸部图像,以达到快速转换的效果,此外,该音素转换模型不受限于语言,能支持各国语言的嘴型转换,故确实能达成本发明的目的。
以上所述者,仅为本发明的实施例而已,当不能以此限定本发明实施的范围,即凡依本发明权利要求书及说明书内容所作的简单的等效变化与修饰,皆仍属本发明的范围。
本文用于企业家、创业者技术爱好者查询,结果仅供参考。

