:
1.本发明涉及一种多尺度自注意力特征融合的行人检测方法,属于人工智能领域。
背景技术:
2.行人检测作为计算机视觉中一个极具研究价值的领域,其广泛应用于汽车无人驾驶,人体行为分析,智能交通,智能视频监控等领域;它是车辆辅助驾驶,智能视频监控和人体行为分析等应用中的第一步,近年来也应用在航拍图像、受害者营救等新兴领域中;由于人体姿态高度随意,形体复杂多变,且有附着和遮挡等问题,准确的在各种场景下检测到行人的理论和技术仍然需要深入探索和研究;行人检测的流程是:对输入的图片或者视频进行检测,判断其中是否包含行人,若有行人,则给出行人信息。
3.传统的行人检测算法核心是提取输入信息的特征并对特征进行分类,利用手工设计的特征提取器很难全方位分析行人的信息,所以这种行人检测方法的检测效果并不理想;随着计算机算力的提升,近几年深度学习得到了飞速发展;基于深度学习的方法显著提升了目标检测的效果;因此,本文提出了一种多尺度自注意力特征融合的行人检测方法;以faster r
‑
cnn为核心,重新设计该框架的特征提取网络,旨在保证检测准确率的条件下减小框架的复杂度,提高模型的检测效率。
技术实现要素:
4.针对传统行人目标检测算法检测效率低,检测效果不好的问题,提出了一种多尺度自注意力特征融合的行人检测算法。
5.为此,本发明提供了如下技术方案:
6.1.一种多尺度自注意力特征融合的行人检测方法,其特征在于,该方法包括以下步骤:
7.步骤1:行人检测图像数据的采集;
8.步骤2:检测图像中行人尺寸的设计;
9.步骤3:行人数据集正负样本的划分;
10.步骤4:行人检测模型的搭建。
11.2.根据权利要求1所述的一种多尺度自注意力特征融合的行人检测方法,其特征在于,所述步骤1中,行人检测图像数据的采集,行人检测数据集是在图像和视频中检测直立行人的研究工作中收集的,数据集中的行人主要是直立状态,并且高于100个像素,图片清晰度高,图片大部分选自个人照片,谷歌以及相机拍摄。
12.3.根据权利要求1所述的一种多尺度自注意力特征融合的行人检测方法,其特征在于,所述步骤2中,检测图像中行人尺寸的设计,具体步骤为:利用 k
‑
means算法针对行人数据集重新聚类,得到更适应本模型的anchor size,为了更快更准确的迭代出最终结果,改用iou即预测框和anchor box的重叠度作为度量,即目标函数:distance=1
–
iou(box,center),其中box表示真实物体包围框的集合,center表示聚类中心框集合;对行人数据进
行聚类最终得到4个中心点,分别是(12,22),(25,38),(41,77),(48,91)。
13.4.根据权利要求1所述的一种多尺度自注意力特征融合的行人检测方法,其特征在于,所述步骤3中,行人数据集正负样本的划分,具体步骤为:利用目标检测标注工具进行标注,将图片格式化为一定的图片尺寸,进而获得行人图像信息,分为包含行人和不包含行人两大类,采取随机抽样的方式将所采集的行人图像数据按一定的比例划分为独立不重复的训练集和测试集。
14.5.根据权利要求1所述的一种多尺度自注意力特征融合的行人检测方法,其特征在于,在所述步骤4中,行人检测模型的搭建,具体过程为:
15.步骤4
‑
1通过使用轻量化网络模型减少网络参数和网络的运算量可以有效提升行人检测的效率,mobilenetv2为轻量化网络,将其应用于特征信息提取任务;
16.步骤4
‑
2深层网络的感受野比较大,语义信息抽象能力强,但是特征图的像素数量级小,会丢失很多细节信息,缺乏空间几何特征的表达能力,浅层网络的感受野比较小,空间信息表征能力强,虽然像素数量级高,但是语义信息的抽象能力弱,将深层语义信息与浅层高分辨率特征进行融合,组成预测坐标位置框和分类任务的多尺度特征图,以此来提高检测精度;
17.步骤4
‑
3senet是一种复杂度低,计算量小的简单有效的注意力机制网络模型;senet模块能够使网络在特征图通道维度上进行拟合,起到强化图像中具有判断力的特征,抑制图像中非显著性特征的作用,分别将senet模块镶嵌在多尺度特征融合之前对特征图进行卷积处理。
18.有益效果:
19.通过上述技术方案,本发明的有益效果是:提出了一种多尺度自注意力特征融合的行人检测方法;首先,用轻量化模型mobilenetv2作为faster r
‑
cnn的特征提取网络,提高行人检测效率;其次,将mobilenetv2网络的不同尺度的特征层进行多尺度特征融合,充分利用高层语义信息和底层高分辨率特征;最后,运用多尺度特征层设计自适应尺度的特征融合网络,在多尺度特征层中间衔接 senet网络模块,为特征层的不同通道分配不同的权重;针对行人目标检测的特定应用,利用k
‑
means方法对anchor重新聚类以确定anchor的尺寸;与现有技术相比,本发明的优点是:
20.1、本方法以faster r
‑
cnn为框架,利用mobilenetv2替换vgg16作为 faster r
‑
cnn网络的特征提取模块,减小了网络的计算量和模型规模,从而提高了faster r
‑
cnn的检测效率。
21.2、引入多尺度特征融合,将mobilenetv2网络的不同尺度的特征层进行多尺度特征融合,来获取高分辨率特征和高语义信息相结合的特征图,为算法的目标预测部分提供更详细的细节信息,改善了行人检测尺度单一的局限性。
22.3、对四种不同尺度的特征图衔接senet模块,为网络在通道维度增添注意力机制,为特征层的不同通道分配不同的权重,进一步提高检测效率。
23.4、针对行人目标检测这一特定应用,利用k
‑
means方法对anchor重新聚类以确定anchor的尺寸,为faster r
‑
cnn网络中的anchor尺寸重新设计新的尺寸,使网络能够更好的拟合行人结构特征,从而更容易准确的预测目标位置。
24.faster r
‑
cnn主要从一下几个方面有所改进:
25.1、通过使用轻量化网络模型减少网络参数和网络的运算量可以有效提升行人检测的效率;mobilenetv2为轻量化网络,将其应用于特征信息提取任务;有别于传统的卷积结构,mobilenetv2使用倒残差结构和瓶颈层相结合的卷积计算方式,能够有效减少网络的运算量和模型参数,在保持检测精度的前提下提高行人目标检测的效率;在resnet中的残差结构是将输入先降维再卷积最后升维的过程;mobilenetv2借鉴resnet的思想,提出了倒残差结构,所谓到残差结构就是先将输入特征图用1
×
1的卷积来进行通道扩张,特征提取任务用3
×
3 的深度可分离卷积来完成,再用1
×
1的卷积做通道压缩,过程与残差结构相反,其目的是让网络更充分的学习目标特征。
26.2、卷积神经网络的工作原理是通过卷积核逐层拟合来提取目标特征,其中一个重要的概念就是感受野;深层网络的感受野比较大,语义信息抽象能力强,但是特征图的像素数量级小,会丢失很多细节信息,缺乏空间几何特征的表达能力;浅层网络的感受野比较小,空间信息表征能力强,虽然像素数量级高,但是语义信息的抽象能力弱;将深层语义信息与浅层高分辨率特征进行融合,组成预测坐标位置框和分类任务的多尺度特征图,以此来提高检测精度。
27.3、对四种不同尺度的特征图衔接senet模块,为网络在通道维度增添注意力机制,senet模块能够使网络在特征图通道维度上进行拟合,起到强化图像中具有判断力的特征,抑制图像中非显著性特征的作用。
附图说明:
28.图1为本发明实施多尺度自注意力特征融合的行人检测方法流程图;
29.图2为本发明实施改进前用于提取图像特征的网络结构简图;
30.图3为经过本发明实施改进后用于提取图像特征的网络结构简图;
31.图4,图6为本发明实施改进前的检测效果图;
32.图5,图7为本发明实施改进后的检测效果图;
33.图8为本发明与其它方法的性能对比图。
具体实施方式
34.下面结合说明书附图,对本发明作进一步说明,以让本领域技术人员参照说明书文字能够具体实施。
35.本发明采用的技术方案为:一种多尺度自注意力特征融合的行人检测方法,包括以下步骤:
36.(1)行人检测图像数据的采集;
37.(2)检测图像中行人尺寸的设计;
38.(3)行人数据集正负样本的划分;
39.(4)行人检测模型的搭建。
40.下面结合附图,对发明作进一步详细说明,本发明提供一种多尺度自注意力特征融合的行人检测方法,训练步骤如图1所示:
41.行人检测图像数据的采集,行人检测数据集是在图像和视频中检测直立行人的研究工作中收集的,数据集中的行人主要是直立状态,并且高于100个像素,图片清晰度高,图
片大部分选自个人照片,谷歌以及相机拍摄。
42.检测图像中行人尺寸的设计,具体步骤为:利用k
‑
means算法针对行人数据集重新聚类,得到更适应本模型的anchor size,为了更快更准确的迭代出最终结果,改用iou即预测框和anchor box的重叠度作为度量,即目标函数:distance =1
–
iou(box,center),其中box表示真实物体包围框的集合,center表示聚类中心框集合;对行人数据进行聚类最终得到4个中心点,分别是(12,22), (25,38),(41,77),(48,91)。
43.行人数据集正负样本的划分,具体步骤为:利用目标检测标注工具进行标注,将图片格式化为一定的图片尺寸,进而获得行人图像信息,分为包含行人和不包含行人两大类,采取随机抽样的方式将所采集的行人图像数据按一定的比例划分为独立不重复的训练集和测试集。
44.行人检测模型的搭建,具体过程为:
45.步骤1:通过使用轻量化网络模型减少网络参数和网络的运算量可以有效提升行人检测的效率,mobilenetv2为轻量化网络,将其应用于特征信息提取任务;
46.步骤2:深层网络的感受野比较大,语义信息抽象能力强,但是特征图的像素数量级小,会丢失很多细节信息,缺乏空间几何特征的表达能力,浅层网络的感受野比较小,空间信息表征能力强,虽然像素数量级高,但是语义信息的抽象能力弱,将深层语义信息与浅层高分辨率特征进行融合,组成预测坐标位置框和分类任务的多尺度特征图,以此来提高检测精度;
47.步骤3:senet是一种复杂度低,计算量小的简单有效的注意力机制网络模型;senet模块能够使网络在特征图通道维度上进行拟合,起到强化图像中具有判断力的特征,抑制图像中非显著性特征的作用,分别将senet模块镶嵌在多尺度特征融合之前对特征图进行卷积处理。
48.相比图2中传统模型,搭建完成的模型如图3所示,主要处理流程如下:
49.1)将原始数据输入mobilenetv2网络,得到初步的feature map;
50.2)选取bottleneck4,bottleneck5,bottleneck7的输出进行多尺度特征融合,在这三个特征提取层后面分别衔接一个senet模块,用senet模块对这三层的输出进行拟合;
51.3)将经过senet拟合后的特征图通道维数用1
×
1的卷积扩张为320;
52.4)bottleneck7的输出经过senet 1
×
1卷积处理之后得到第一个预测层p1;
53.5)将p1进行2倍上采样,与经过senet 1
×
1卷积处理过的bottleneck5的输出相加,得到p2;
54.6)将p2进行2倍上采样,与经过senet 1
×
1卷积处理过的bottleneck4的输出相加,得到p3;
55.7)把p1,p2,p3分别输入rpn中产生目标候选框,根据候选框尺寸反应用于 p1,p2,p3生成目标候选区域;
56.8)对目标候选区域做后处理来进行预测和定位;
57.图4,图5,图6,图7展示了本发明的测试前后的效果图,共挑选了两组进行对比;本文挑选了街边两个场景作为样本进行研究;图4,图6是没有使用多尺度自注意力特征融合改进的测试效果图,图5,图7是使用多尺度自注意力特征融合改进的测试效果图;对于改进前来说,精度低且存在漏检的项目,改进后,检测精度明显高于之前,缓解了漏检的缺陷;总
的来说,此项目使用多尺度自注意力特征融合对检测准确性起到了一定的提升作用。
58.实验采用精度(precision)、召回率(recall)、平均精度(ap)作为算法性能的定量评价指标,其中精度(precision),召回率(recall)表示为:
[0059][0060][0061][0062]
式中tp(true positive):iou>0.7的预测框个数(每一个ground truth只参与一次),fp(false positive):iou<=0.7的预测框(或者是预测到同样gt的其它预测框)个数,fn(false negative):没有检测到的gt的数量,ap: precision
‑
recall曲线下面积;为了更好的评估算法的可行性,我们还遵照 log
‑
average miss rate over false positives per image(记为mr
‑2)的评估策略。
[0063]
为了说明本文算法有效性,我们将本文算法与目前的高性能算法进行了比较,其中包括faster r
‑
cnn、bf rpn、csp、pbm、or
‑
cnn,另外还包括一阶段算法 yolo9000、ssd和alfnet;本文采用相同的实验配置,在inria和citypersons 两个数据集上实现了上述算法;图8展示了当前流行算法用mr
‑2评估方法在 citypersons上的性能;对于算法的mr
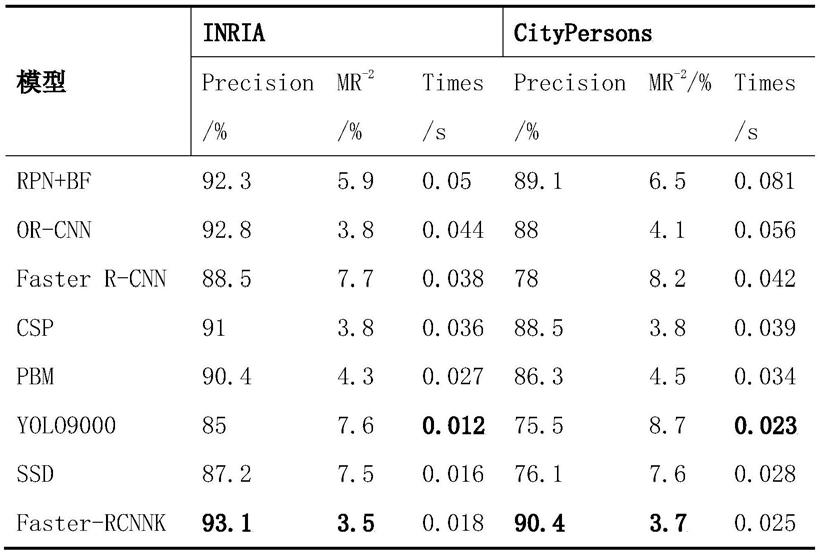
‑2,检测精度以及运算速度的对比结果如表 1所示。
[0064]
表1不同方法的评估结果
[0065][0066]
faster r
‑
cnnk是本文创新的算法结构,其特征提取模块用的是mobilenetv2网络,将该网络的bottleneck4,bottleneck5,bottleneck7的输出增加senet 注意力机制并进行多尺度特征融合,对于anchor box的尺寸重新聚类;从表中可以看出,改进的faster r
‑
cnnk结构的检测精度和mr
‑2均高于其它算法;fasterr
‑
cnnk的检测效率虽略低于
yolo9000,但是检测效果要远优于yolo9000.将csp, alfnet和faster r
‑
cnnk模型在inria数据集上训练完成之后利用其测试集进行测试;综合来看,对于检测效率和检测效果的折衷,本文的faster r
‑
cnnk 表现最好;该实验数据证明了本模型是个好模型,可以应用于实际情况;此外,本发明只验证了多尺度自注意力特征融合有效,对于其它是否可加以及有效,本发明未涉及,这也是需要后续更进一步的工作深入。
[0067]
对于本领域技术人员而言,显然本发明不限于上述示范性实施例的细节,而且在不背离本发明的精神或基本特征的情况下,能够以其他的具体形式实现本发明;因此,无论从哪一点来看,均应将实施例看作是示范性的,而且是非限制性的,本发明的范围由所附权利要求而不是上述说明限定,因此旨在将落在权利要求的等同要件的含义和范围内的所有变化囊括在本发明内;不应将权利要求中的任何附图标记视为限制所涉及的权利要求。
[0068]
此外,应当理解,虽然本说明书按照实施方式加以描述,但并非每个实施方式仅包含一个独立的技术方案,说明书的这种叙述方式仅仅是为清楚起见,本领域技术人员应当将说明书作为一个整体,各实施例的技术方案也可以经适当的组合,形成本领域技术人员可以理解的其他实施方式。
再多了解一些
本文用于企业家、创业者技术爱好者查询,结果仅供参考。
